You might also like
- Course Notes - Basic ProbabilityDocument6 pagesCourse Notes - Basic ProbabilityAnshulNo ratings yet
- Course Notes Basic ProbabilityDocument6 pagesCourse Notes Basic ProbabilityAzizNo ratings yet
- 03 Statistical & Internal ValidityDocument58 pages03 Statistical & Internal ValidityAssan AchibatNo ratings yet
- Lec 07Document51 pagesLec 07Tùng ĐàoNo ratings yet
- Class 3 SPDocument14 pagesClass 3 SPAbel GulilatNo ratings yet
- LECTURE 02-Probability IE 3373 - ALDocument44 pagesLECTURE 02-Probability IE 3373 - ALMahmoud AbdelazizNo ratings yet
- Probability and StatisticsDocument53 pagesProbability and Statisticsvinita sandriNo ratings yet
- Probability Theory: Much Inspired by The Presentation of Kren and SamuelssonDocument27 pagesProbability Theory: Much Inspired by The Presentation of Kren and Samuelssonduylinh65No ratings yet
- MATHINTIIIU33Probability CombinationsDocument8 pagesMATHINTIIIU33Probability CombinationsDerrick ApongNo ratings yet
- 2.3 Probability & StatisticsDocument24 pages2.3 Probability & StatisticsRajaNo ratings yet
- Classical (Or Theoretical) Probability Is Used When Each Outcome in A Sample Space IsDocument4 pagesClassical (Or Theoretical) Probability Is Used When Each Outcome in A Sample Space Isrosalynmejia1196No ratings yet
- EDA Counting RulesDocument7 pagesEDA Counting RulesMaryang DescartesNo ratings yet
- ML4 Linear ModelsDocument34 pagesML4 Linear ModelsGonzalo ContrerasNo ratings yet
- Leure ( - ) : Probability CalculationsDocument56 pagesLeure ( - ) : Probability CalculationsanabNo ratings yet
- Math ProbabilityDocument4 pagesMath ProbabilityV CNo ratings yet
- Evidence 2.1 2.3Document10 pagesEvidence 2.1 2.3alan ErivesNo ratings yet
- Lesson 2 Statistical InferenceDocument45 pagesLesson 2 Statistical InferencemaartenwildersNo ratings yet
- ProbabilityDocument34 pagesProbabilityAwais BangashNo ratings yet
- Permutations and Combinations Class NoteDocument9 pagesPermutations and Combinations Class NoteSudhanshu KumarNo ratings yet
- ES 23 Lecture 2 - ProbabilityDocument24 pagesES 23 Lecture 2 - ProbabilityPao PaoNo ratings yet
- Module 6: Analysis of Algorithms: Reading From The Textbook: Chapter 4 AlgorithmsDocument19 pagesModule 6: Analysis of Algorithms: Reading From The Textbook: Chapter 4 AlgorithmsDejing KongNo ratings yet
- Statistics Concepts: An Overview of Upper-Division Statistics With RDocument69 pagesStatistics Concepts: An Overview of Upper-Division Statistics With RmukeshNo ratings yet
- MathDocument8 pagesMathAalyyah C.No ratings yet
- ProbabilityDocument5 pagesProbabilityJeorge HugnoNo ratings yet
- Probability MITDocument116 pagesProbability MITMinh Quan LENo ratings yet
- 9 SamplingDocument5 pages9 SamplingTasbir HasanNo ratings yet
- ML Summarized LecturesDocument14 pagesML Summarized LecturesShah HoodNo ratings yet
- Probability and Statistics: To P, or Not To P?: Module Leader: DR James AbdeyDocument5 pagesProbability and Statistics: To P, or Not To P?: Module Leader: DR James Abdeynithin UppalapatiNo ratings yet
- 1.1 Basic Time Series Decomposition PDFDocument38 pages1.1 Basic Time Series Decomposition PDFIdvin NettNo ratings yet
- TOPIC1. Summation and Factorial Notations, Data Types, Data CollectionDocument8 pagesTOPIC1. Summation and Factorial Notations, Data Types, Data CollectionKyrby CabalquintoNo ratings yet
- The Likelihood of An Event Occurring: Expected ValuesDocument5 pagesThe Likelihood of An Event Occurring: Expected ValuesDRANZER101No ratings yet
- Acceptance Sampling For AttributesDocument10 pagesAcceptance Sampling For AttributesAbdirahman MohamedNo ratings yet
- Probability Cheat Sheet 2Document4 pagesProbability Cheat Sheet 2Mbouzou Fomena PalmasNo ratings yet
- UNIT 5 - UncertaintyDocument36 pagesUNIT 5 - UncertaintyNoobs RageNo ratings yet
- Slides 11 09 PDFDocument105 pagesSlides 11 09 PDFGaurav Kumar GuptaNo ratings yet
- Slides-SkskDocument151 pagesSlides-SkskGaurav Kumar Gupta100% (1)
- Statistics and Probability KatabasisDocument7 pagesStatistics and Probability KatabasisDaniel N Sherine FooNo ratings yet
- Math2101Stat 3Document30 pagesMath2101Stat 3iamtawhidhassanNo ratings yet
- Lecture 3 CS648 2023Document29 pagesLecture 3 CS648 2023Technology TectrixNo ratings yet
- Apuntes Probabilidad y Estadística FundamentalDocument132 pagesApuntes Probabilidad y Estadística FundamentalJuan David Garcia NunezNo ratings yet
- Probability and Hypothesis TestingDocument31 pagesProbability and Hypothesis TestingAbdul sami dahriNo ratings yet
- Lecture 4 Sampling Sampling Distribution and CLT Part 1 1Document31 pagesLecture 4 Sampling Sampling Distribution and CLT Part 1 1Tristan PenarroyoNo ratings yet
- Probability: 201A: Econometrics I Peter E. Rossi Anderson School of ManagementDocument25 pagesProbability: 201A: Econometrics I Peter E. Rossi Anderson School of Managementgokuler137No ratings yet
- Fall 2022 Midterm Notes PDFDocument15 pagesFall 2022 Midterm Notes PDFJack ANo ratings yet
- Elements of ProbabilityDocument21 pagesElements of ProbabilityIbrahim OjedokunNo ratings yet
- ML & Statistics Unit 6Document36 pagesML & Statistics Unit 6Soham BadjateNo ratings yet
- Business Econometrics Using SAS Tools (BEST) : Class IV - Probability RefresherDocument31 pagesBusiness Econometrics Using SAS Tools (BEST) : Class IV - Probability RefresherRohit RajNo ratings yet
- MIT18 05S14 ReadingsDocument291 pagesMIT18 05S14 ReadingspucalerroneNo ratings yet
- Mathematics Language and Symbols - Lec 2Document46 pagesMathematics Language and Symbols - Lec 2France DiazNo ratings yet
- Randomized Algorithms: - Tools For P ( (+) )Document20 pagesRandomized Algorithms: - Tools For P ( (+) )KrishnaKishoreNo ratings yet
- Randomized Algorithms: - Tools For P ( (+) )Document20 pagesRandomized Algorithms: - Tools For P ( (+) )KrishnaKishoreNo ratings yet
- Probability Cheat SheetDocument5 pagesProbability Cheat SheetApo LogoNo ratings yet
- Probability Cheat SheetDocument5 pagesProbability Cheat SheetZhivko ZhelyazkovNo ratings yet
- Unit 5 - Probability Theory For Financial RiskDocument74 pagesUnit 5 - Probability Theory For Financial RiskiDeo StudiosNo ratings yet
- Lecture 01 ProbabilityDocument51 pagesLecture 01 ProbabilitydantieNo ratings yet
- Statistic (5) - Probability StatisticDocument23 pagesStatistic (5) - Probability StatisticTiofanNo ratings yet
- Mathematical Language & Symbols: Mathematics in The Modern WorldDocument39 pagesMathematical Language & Symbols: Mathematics in The Modern WorldMarjorie OroNo ratings yet
- Mit18 05 s22 ProbabilityDocument112 pagesMit18 05 s22 ProbabilityMuhammad RafayNo ratings yet
- Attacking Problems in Logarithms and Exponential FunctionsFrom EverandAttacking Problems in Logarithms and Exponential FunctionsRating: 5 out of 5 stars5/5 (1)
- Peter John Crodua Final Demo 11Document10 pagesPeter John Crodua Final Demo 11Romalyn VillegasNo ratings yet
- Key To CorrectionDocument2 pagesKey To CorrectionRomalyn VillegasNo ratings yet
- GLORIOUS MYSTERY (Wed and Sun)Document50 pagesGLORIOUS MYSTERY (Wed and Sun)Romalyn VillegasNo ratings yet
- GLORIOUS MYSTERY (Wed and Sun)Document50 pagesGLORIOUS MYSTERY (Wed and Sun)Romalyn VillegasNo ratings yet
- GLORIOUS MYSTERY (Wed and Sun)Document50 pagesGLORIOUS MYSTERY (Wed and Sun)Romalyn VillegasNo ratings yet
- PT g10 MathematicsDocument5 pagesPT g10 MathematicsMary MillareNo ratings yet
- Set1 (SandP)Document5 pagesSet1 (SandP)Shashwat SinghNo ratings yet
- Math q1 Mod9 Remainder and Factor Theorems FINAL08122020Document19 pagesMath q1 Mod9 Remainder and Factor Theorems FINAL08122020Aldrin Ray M. MendezNo ratings yet
- Math 10 - ArchiveDocument1 pageMath 10 - ArchiveRomalyn VillegasNo ratings yet
- ACHIEVEDocument12 pagesACHIEVERomalyn VillegasNo ratings yet
- LeaP Math G9 Week 6 7 Q3Document9 pagesLeaP Math G9 Week 6 7 Q3Romalyn VillegasNo ratings yet
- Learning Area Quarter Grade Level Date I.Lesson Title Ii. Most Essential Learning Competencies (Melcs)Document8 pagesLearning Area Quarter Grade Level Date I.Lesson Title Ii. Most Essential Learning Competencies (Melcs)Romalyn VillegasNo ratings yet
- Family Day Big TaskDocument4 pagesFamily Day Big TaskRomalyn VillegasNo ratings yet
- LeaP Math G10 Week 7 Q3Document4 pagesLeaP Math G10 Week 7 Q3Janeth Miguel Satrain0% (1)
- Learning Area Grade Level Quarter Date I. Lesson Title Ii. Most Essential Learning Competencies (Melcs) Iii. Content/Core ContentDocument8 pagesLearning Area Grade Level Quarter Date I. Lesson Title Ii. Most Essential Learning Competencies (Melcs) Iii. Content/Core ContentRomalyn VillegasNo ratings yet
- Direct Variation I. ObjectivesDocument9 pagesDirect Variation I. ObjectivesRomalyn VillegasNo ratings yet
- Republic of The Philippines Department of Education: M8Ge-Iva - 1 M8Ge-Iva - 1Document6 pagesRepublic of The Philippines Department of Education: M8Ge-Iva - 1 M8Ge-Iva - 1Romalyn VillegasNo ratings yet
- Percentiles Detailed Lesson PlanDocument8 pagesPercentiles Detailed Lesson PlanMarc Galos100% (6)
- Subject Learning ExpectationDocument2 pagesSubject Learning ExpectationRomalyn VillegasNo ratings yet
- Curriculum Implementation Matrix (Cim)Document4 pagesCurriculum Implementation Matrix (Cim)Romalyn VillegasNo ratings yet
- Undertaking: Mary Jean M. Murillo Nilo I. Alcaraz Romer Ranoco District MKP Member LRMDS Focal PersonDocument1 pageUndertaking: Mary Jean M. Murillo Nilo I. Alcaraz Romer Ranoco District MKP Member LRMDS Focal PersonRomalyn VillegasNo ratings yet
- SEMIDocument4 pagesSEMIRomalyn VillegasNo ratings yet
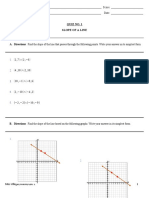
- Quiz 1 - Slope of A LineDocument3 pagesQuiz 1 - Slope of A LineRomalyn VillegasNo ratings yet
- 2017 Mathg10q1.2Document139 pages2017 Mathg10q1.2Romalyn VillegasNo ratings yet
- A Semi-Detailed Lesson Plan in Mathematics 9 3 Hours Quarter 1 Week Date: January 5, 2021Document18 pagesA Semi-Detailed Lesson Plan in Mathematics 9 3 Hours Quarter 1 Week Date: January 5, 2021Romalyn VillegasNo ratings yet
- Detailed Lesson Plan in Mathematics 10 CombinationsDocument7 pagesDetailed Lesson Plan in Mathematics 10 CombinationsRomalyn VillegasNo ratings yet
- Business Ethics and Social Responsibility: Performance Task # 2Document2 pagesBusiness Ethics and Social Responsibility: Performance Task # 2Romalyn VillegasNo ratings yet
- Graphing Linear Equations in Two Variables: Sketch The Graph of Each LineDocument2 pagesGraphing Linear Equations in Two Variables: Sketch The Graph of Each LineRomalyn VillegasNo ratings yet
- Describe Me As Honest and Detailed Person.: Experience A Number of Different FeelingsDocument2 pagesDescribe Me As Honest and Detailed Person.: Experience A Number of Different FeelingsRomalyn VillegasNo ratings yet
- ConstantinoDocument2 pagesConstantinoRomalyn VillegasNo ratings yet
- SSP-NR 550 The Passat GTE PDFDocument72 pagesSSP-NR 550 The Passat GTE PDFan89% (9)
- Explaining OPERCOM® Methodology in CommissioningDocument5 pagesExplaining OPERCOM® Methodology in Commissioningiman2222100% (2)
- StructSteel Takeoff InstructionsDocument56 pagesStructSteel Takeoff InstructionsAmrish TyagiNo ratings yet
- Wea Met Aws310 Brochure 210x280 B211290en C Low v2Document4 pagesWea Met Aws310 Brochure 210x280 B211290en C Low v2Anonymous rpSGuQPNo ratings yet
- Thermal Engineering For The Construction of Large Concrete Arch DamsDocument10 pagesThermal Engineering For The Construction of Large Concrete Arch DamsOscar LopezNo ratings yet
- Lesson Plan in Remainders TheoremDocument5 pagesLesson Plan in Remainders TheoremJune SabatinNo ratings yet
- Dataram RAMDisk Users ManualDocument20 pagesDataram RAMDisk Users ManualBabis ArbiliosNo ratings yet
- 12 One Way Ribbed Slab-SlightDocument18 pages12 One Way Ribbed Slab-Slightريام الموسوي100% (1)
- EVADTS - 6-1 - 04 June 2009Document232 pagesEVADTS - 6-1 - 04 June 2009Carlos TejedaNo ratings yet
- ArticleDocument10 pagesArticlePrachiNo ratings yet
- The Sacred Number Forty-NineDocument12 pagesThe Sacred Number Forty-NinePatrick Mulcahy100% (6)
- Aqa Byb1 W QP Jun07Document12 pagesAqa Byb1 W QP Jun07李超然No ratings yet
- MS Excel FunctionsDocument3 pagesMS Excel FunctionsRocket4No ratings yet
- Topic 9 - Transport in Animals: Blood and Lymph VesselsDocument15 pagesTopic 9 - Transport in Animals: Blood and Lymph Vesselsgytfnhj.comNo ratings yet
- Celonis Configuration Store Setup Guide 1.6Document11 pagesCelonis Configuration Store Setup Guide 1.6Venugopal JujhavarappuNo ratings yet
- Mitsubishi 4g64 Engine 2 4l Service ManualDocument10 pagesMitsubishi 4g64 Engine 2 4l Service Manualjennifer100% (49)
- Project Solar Tracking SystemDocument29 pagesProject Solar Tracking SystemJacob B Chacko100% (1)
- Lesson 5 Appraising Diagnostic Research StudiesDocument23 pagesLesson 5 Appraising Diagnostic Research StudiesProject MedbooksNo ratings yet
- Method IvivcDocument15 pagesMethod IvivcHari Krishnan100% (1)
- Reference Guide: TMS320C674x DSP CPU and Instruction SetDocument770 pagesReference Guide: TMS320C674x DSP CPU and Instruction SetSamreen tabassumNo ratings yet
- CBCS Revised BCA 5 and 6 Sem-FinalDocument38 pagesCBCS Revised BCA 5 and 6 Sem-FinalIrfan AhmedNo ratings yet
- DDDD (Repaired)Document61 pagesDDDD (Repaired)Phung ba Quoc AnhNo ratings yet
- Speciifactions and Cross Reference Bosch Spark PlugDocument3 pagesSpeciifactions and Cross Reference Bosch Spark Plugcarlos puerto100% (1)
- Anthony Hans HL Biology Ia Database WM PDFDocument12 pagesAnthony Hans HL Biology Ia Database WM PDFYadhira IbañezNo ratings yet
- HeliCoil CatalogueDocument34 pagesHeliCoil Cataloguejarv7910No ratings yet
- Quadratic Equation - MATH IS FUNDocument8 pagesQuadratic Equation - MATH IS FUNChanchan LebumfacilNo ratings yet
- E50 en Tcd210020ab 20220321 Inst WDocument1 pageE50 en Tcd210020ab 20220321 Inst Wesau hernandezNo ratings yet
- Ijtmsr201919 PDFDocument5 pagesIjtmsr201919 PDFPrakash InturiNo ratings yet
- FREE EthnicKnittingBookPattern HeadbandDocument4 pagesFREE EthnicKnittingBookPattern HeadbandriyuuhiNo ratings yet
- Irjet V4i10201 PDFDocument8 pagesIrjet V4i10201 PDFBesmir IsmailiNo ratings yet