You might also like
- Math, Grade 3: Strengthening Basic Skills with Jokes, Comics, and RiddlesFrom EverandMath, Grade 3: Strengthening Basic Skills with Jokes, Comics, and RiddlesNo ratings yet
- Introduction To Time Series Analysis: Welcome To The Course!Document20 pagesIntroduction To Time Series Analysis: Welcome To The Course!enrique gonzalez duranNo ratings yet
- Week 4, Solution: Exercise 4.38Document15 pagesWeek 4, Solution: Exercise 4.38John SmithNo ratings yet
- Calcula-Dibuja 4Document23 pagesCalcula-Dibuja 4ENRIQUE CRESPONo ratings yet
- Foo PDFDocument7 pagesFoo PDFfodsffNo ratings yet
- Q Q Plot of Residuals: Batch# 1 Batch# 2 Batch# 3Document2 pagesQ Q Plot of Residuals: Batch# 1 Batch# 2 Batch# 3apsara karkiNo ratings yet
- CH Multiple Linear Regression Everitt HothornDocument12 pagesCH Multiple Linear Regression Everitt HothornRuan CerqueiraNo ratings yet
- Mock Midterm Test 1: Exercise Exercise ExerciseDocument2 pagesMock Midterm Test 1: Exercise Exercise ExercisePETERNo ratings yet
- Displaying Model Plots in Lattice PlotsDocument16 pagesDisplaying Model Plots in Lattice PlotsAriake SwyceNo ratings yet
- 1 Microbalance Accuracy: Manuel F. G. Weinkauf, José G. Kunze, Joanna J. Waniek, Michal Ku CeraDocument9 pages1 Microbalance Accuracy: Manuel F. G. Weinkauf, José G. Kunze, Joanna J. Waniek, Michal Ku CerawessilissaNo ratings yet
- V64i04 PDFDocument34 pagesV64i04 PDFElíGomaraGilNo ratings yet
- On The Estimation of Change Points in The Beer-Lambert Law ProblemDocument14 pagesOn The Estimation of Change Points in The Beer-Lambert Law ProblemNunee AyuNo ratings yet
- Transformations and Misspecification of Econometric Models: August 27, 2014Document19 pagesTransformations and Misspecification of Econometric Models: August 27, 2014Maria RoaNo ratings yet
- 330 Lecture11 2014Document61 pages330 Lecture11 2014PETERNo ratings yet
- The Bayesian Lasso: Rebecca C. Steorts Predictive Modeling and Data Mining: STA 521Document16 pagesThe Bayesian Lasso: Rebecca C. Steorts Predictive Modeling and Data Mining: STA 521Malika BehroozrazeghNo ratings yet
- (With Residual Plot) : 40 60 80 100 120 140 160 WeightDocument11 pages(With Residual Plot) : 40 60 80 100 120 140 160 WeightmehrinfatimaNo ratings yet
- 330 Lecture8 2014Document34 pages330 Lecture8 2014Anonymous gUySMcpSqNo ratings yet
- Anscombe Regression Example DataDocument5 pagesAnscombe Regression Example DataAnonymous GvTPw4sNo ratings yet
- IntroductionDocument5 pagesIntroductionTalha FarooqNo ratings yet
- 330 Lecture8 2015Document33 pages330 Lecture8 2015Anonymous gUySMcpSqNo ratings yet
- Temperature ScatterplotDocument1 pageTemperature ScatterplotPiuNo ratings yet
- Costs: Developing The Language of CostsDocument27 pagesCosts: Developing The Language of Costsee400bps kudNo ratings yet
- Stat 5102 Lecture Slides: Deck 6 Gauss-Markov Theorem, Sufficiency, Generalized Linear Models, Likelihood Ratio Tests, Categorical Data AnalysisDocument86 pagesStat 5102 Lecture Slides: Deck 6 Gauss-Markov Theorem, Sufficiency, Generalized Linear Models, Likelihood Ratio Tests, Categorical Data AnalysisHông HoaNo ratings yet
- RootsExtremaInflections 2017-05-26Document16 pagesRootsExtremaInflections 2017-05-26mgrubisicNo ratings yet
- EloisaDocument12 pagesEloisastarbridNo ratings yet
- Multivariate Methods: M Ans ThulinDocument14 pagesMultivariate Methods: M Ans ThulinWERU JOAN NYOKABINo ratings yet
- 2014 TestDocument13 pages2014 TestAnonymous gUySMcpSqNo ratings yet
- RQ Mcycle1Document1 pageRQ Mcycle1rojasleopNo ratings yet
- Regression Analysis - From Statistics To Machine Learning: Ronald Hochreiter Sensational - AiDocument50 pagesRegression Analysis - From Statistics To Machine Learning: Ronald Hochreiter Sensational - AithcNo ratings yet
- Prelims StatsDocument39 pagesPrelims StatsSergioNo ratings yet
- HX 4Document1 pageHX 4drassuss45No ratings yet
- Noncentral TDocument56 pagesNoncentral TMadara RadillaNo ratings yet
- Lect6 Math231Document38 pagesLect6 Math231Qasim RafiNo ratings yet
- Midterm Test: Reaction Times Vs Caffeine IntakeDocument2 pagesMidterm Test: Reaction Times Vs Caffeine IntakeAnonymous gUySMcpSqNo ratings yet
- Delta QQ PlotDocument1 pageDelta QQ PlotBorysław PaulewiczNo ratings yet
- Part3 Set1 GARCHDocument37 pagesPart3 Set1 GARCHJames DeenNo ratings yet
- Sim RDocument6 pagesSim Rsipho23No ratings yet
- Player Aid - Ark SheetDocument1 pagePlayer Aid - Ark SheetRichard HarrisonNo ratings yet
- Lecture 16: Polynomial and Categorical Regression 1 ReviewDocument10 pagesLecture 16: Polynomial and Categorical Regression 1 ReviewSNo ratings yet
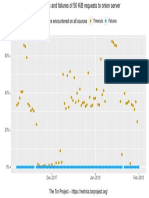
- Problems Encountered On All Sources: Timeouts FailuresDocument1 pageProblems Encountered On All Sources: Timeouts FailuresPatrick PerezNo ratings yet
- Abs. Minimum SelectionDocument2 pagesAbs. Minimum SelectionAlejandro RomeroNo ratings yet
- Boxplots Degs NSVD - PTL 2Document1 pageBoxplots Degs NSVD - PTL 2Amal KatribNo ratings yet
- 2.lecture2 AteDocument61 pages2.lecture2 AteMarc RomaníNo ratings yet
- Lecture 20: Outliers and Influential PointsDocument11 pagesLecture 20: Outliers and Influential PointsSNo ratings yet
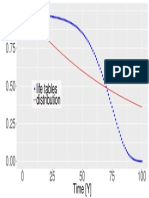
- Life Tables DistributionDocument1 pageLife Tables DistributionOliwierNo ratings yet
- 330 Lecture15 2014Document53 pages330 Lecture15 2014PiNo ratings yet
- Normal Q Q Plot (Sepal - Length) Normal Q Q Plot (Sepal - Width)Document1 pageNormal Q Q Plot (Sepal - Length) Normal Q Q Plot (Sepal - Width)Carlos MunozNo ratings yet
- Intervening With - Purge Without - Noov L2 Intervening Without - Purge Without - Noov L2Document10 pagesIntervening With - Purge Without - Noov L2 Intervening Without - Purge Without - Noov L2Esubalew MaruNo ratings yet
- Lecture HPC 11 ParallelizationDocument128 pagesLecture HPC 11 ParallelizationAldo Ndun AveiroNo ratings yet
- RQ RegsplineDocument1 pageRQ RegsplinerojasleopNo ratings yet
- Causal Inference: An Introduction: Qingyuan ZhaoDocument51 pagesCausal Inference: An Introduction: Qingyuan Zhaodewi ariantiNo ratings yet
- Ponch I Pack Coalesce Nte 14Document12 pagesPonch I Pack Coalesce Nte 14Amy MarsNo ratings yet
- 5 Regression PDFDocument115 pages5 Regression PDFhawk91No ratings yet
- 49dd120 Mazda CX 30Document2 pages49dd120 Mazda CX 30biggenaNo ratings yet
- Wager14a PDFDocument27 pagesWager14a PDFgeoman970No ratings yet
- pt4 Adv Regression Models PDFDocument170 pagespt4 Adv Regression Models PDFVishwajit kumarNo ratings yet
- Towards An Embedded Biologically-Inspired Machine Vision ProcessorDocument34 pagesTowards An Embedded Biologically-Inspired Machine Vision ProcessorSarthak GoyalNo ratings yet
- Lect6 PDFDocument22 pagesLect6 PDF杜晓晚No ratings yet
- Problems Encountered On All Sources: Timeouts FailuresDocument1 pageProblems Encountered On All Sources: Timeouts FailuresPatrick PerezNo ratings yet
- C2 Statistical LearningDocument37 pagesC2 Statistical LearningLluïsa GualNo ratings yet