You might also like
- PCCP Thickness DesignDocument11 pagesPCCP Thickness DesignArmand Mikhail G. TempladoNo ratings yet
- POH - PA44 Seminole G1000 NXiDocument388 pagesPOH - PA44 Seminole G1000 NXiroxyNo ratings yet
- Blast Chiller Service ManualDocument100 pagesBlast Chiller Service ManualClaudio Valencia MarínNo ratings yet
- Assignment R New 1Document26 pagesAssignment R New 1Sohel RanaNo ratings yet
- Module 04 - Part1 AssignmentDocument10 pagesModule 04 - Part1 Assignmentsuresh avadutha75% (4)
- Business Statistics: Level 3Document26 pagesBusiness Statistics: Level 3Hein Linn Kyaw100% (1)
- Feeder Protection: Understanding CTs and Relay OperationDocument19 pagesFeeder Protection: Understanding CTs and Relay Operationsandeepy_27100% (1)
- Vibrational Numbers (FAQ) PDFDocument4 pagesVibrational Numbers (FAQ) PDFJcpathak100% (1)
- IADC Formula Sheet: X X X + + ÷ X + X - ÷ XDocument5 pagesIADC Formula Sheet: X X X + + ÷ X + X - ÷ XMarwa ElghifaryNo ratings yet
- Let's Practise: Maths Workbook Coursebook 7From EverandLet's Practise: Maths Workbook Coursebook 7No ratings yet
- Linear Programming - Case Studies+SolutionsDocument119 pagesLinear Programming - Case Studies+SolutionsNicholas Oneal100% (2)
- Fundamentals of AI Seismic InversionDocument30 pagesFundamentals of AI Seismic InversionYoggie Surya PradanaNo ratings yet
- Quantum Field Theory IDocument599 pagesQuantum Field Theory IBryan Aleman100% (3)
- Business Decision MakingDocument17 pagesBusiness Decision MakingMezba Ul Haque0% (1)
- Switched Reluctance MotorDocument52 pagesSwitched Reluctance Motorkoppulabro75% (8)
- Regression-Timeseries ForecastingDocument4 pagesRegression-Timeseries ForecastingAkshat TiwariNo ratings yet
- Decision-Making Management: A Tutorial and ApplicationsFrom EverandDecision-Making Management: A Tutorial and ApplicationsNo ratings yet
- Kozyrev - Aether, Time and Torsion - Divine CosmosDocument1 pageKozyrev - Aether, Time and Torsion - Divine Cosmospaulsub63No ratings yet
- 02 MulticollinearityDocument8 pages02 MulticollinearityGabriel Gheorghe100% (1)
- Activity Event DurationDocument17 pagesActivity Event DurationBasharat SaigalNo ratings yet
- STAT 3301 - Dataset and Data Summary ReportDocument9 pagesSTAT 3301 - Dataset and Data Summary ReportSuleman KhanNo ratings yet
- Selected Examples and Their SolutionsDocument20 pagesSelected Examples and Their SolutionsRebeccah NdungiNo ratings yet
- AssignmentDocument12 pagesAssignmentTharanga KariyawasamNo ratings yet
- Cost and EstimationDocument16 pagesCost and EstimationRonald Mulley0% (1)
- 4 6006014285984042352Document4 pages4 6006014285984042352Hailu Harka100% (1)
- Topic Two Cost Estimation MethodsDocument7 pagesTopic Two Cost Estimation Methodsmercy kirwaNo ratings yet
- Linear ProgrammingDocument20 pagesLinear ProgrammingNabatanzi HeatherNo ratings yet
- MAS202 IB1604 HW1 NgoChiThien CS170289Document12 pagesMAS202 IB1604 HW1 NgoChiThien CS170289Ngo Chi Thien (K17CT)No ratings yet
- Eco Assignment NDocument8 pagesEco Assignment NshambelNo ratings yet
- El Efecto Más Grande Es El de "D" Con Un Valor DE 2.43625Document6 pagesEl Efecto Más Grande Es El de "D" Con Un Valor DE 2.43625Carol CelyNo ratings yet
- EXCEL Output: Regression StatisticsDocument21 pagesEXCEL Output: Regression StatisticsFranklin NguyenNo ratings yet
- Isye4031 Regression and Forecasting Practice Problems 2 Fall 2014Document5 pagesIsye4031 Regression and Forecasting Practice Problems 2 Fall 2014cthunder_1No ratings yet
- Exercise Sem 2 20162017 - Past YearDocument5 pagesExercise Sem 2 20162017 - Past Yearsyakirah-mustaphaNo ratings yet
- Production AnalysisDocument36 pagesProduction AnalysisMr BhanushaliNo ratings yet
- 20miy0018 VL2022230102069 Ast01Document10 pages20miy0018 VL2022230102069 Ast01Ruban RajNo ratings yet
- 4 Multiple Regression ModelsDocument66 pages4 Multiple Regression ModelsWingtung HoNo ratings yet
- DS Updated PDF QuestionsDocument35 pagesDS Updated PDF Questionsdiksha1920dangdeNo ratings yet
- Guia 2Document12 pagesGuia 2Duvan RodriguezNo ratings yet
- Ekomet Jawaban CH 2Document8 pagesEkomet Jawaban CH 2valen mirandaNo ratings yet
- Tatenda Muswere Econometrics AnalyticsDocument11 pagesTatenda Muswere Econometrics AnalyticscultureTeeNo ratings yet
- (20 Points, 4 Points Each)Document3 pages(20 Points, 4 Points Each)TranQuynhChi2001 PhanNo ratings yet
- Report: Integral Calculations Using C++ CodeDocument8 pagesReport: Integral Calculations Using C++ CodeYosua Heru IrawanNo ratings yet
- GBS514test12014 Evening (2)Document6 pagesGBS514test12014 Evening (2)kaszulu1No ratings yet
- 105 ST - AssignmentDocument4 pages105 ST - AssignmentjatinNo ratings yet
- Econometrics FinalDocument16 pagesEconometrics FinalDanikaLiNo ratings yet
- Managerial Economics GuideDocument15 pagesManagerial Economics GuideNotYGurLzNo ratings yet
- Course: STAT-212 Term: 182 Homework # 5 Material: Chapter 14 Due Date: Thursday, 24-March-2019Document3 pagesCourse: STAT-212 Term: 182 Homework # 5 Material: Chapter 14 Due Date: Thursday, 24-March-2019rrNo ratings yet
- Mock exam questions QB, EBC2025, 29 May 2020Document4 pagesMock exam questions QB, EBC2025, 29 May 2020Boris van LieshoutNo ratings yet
- Chapter 3 Arithmetic For Computers-NewDocument32 pagesChapter 3 Arithmetic For Computers-NewStephanieNo ratings yet
- 6 Real-World Case Studies: Data Science For BusinessDocument18 pages6 Real-World Case Studies: Data Science For BusinessSqaure PodNo ratings yet
- Tasks A TreesDocument14 pagesTasks A TreesAmos Keli MutuaNo ratings yet
- 6 XG Boost - Jupyter NotebookDocument3 pages6 XG Boost - Jupyter Notebookvenkatesh m100% (1)
- M2L2 Producing Reports ExercisesDocument6 pagesM2L2 Producing Reports ExercisesRichard LiuNo ratings yet
- PRD 521 CAT Answers Analyzed for Critical Path and Queuing ModelsDocument7 pagesPRD 521 CAT Answers Analyzed for Critical Path and Queuing ModelsmarkwechenjeNo ratings yet
- Regression analysis predicting math exam scores from school spending & lunch programsDocument11 pagesRegression analysis predicting math exam scores from school spending & lunch programsAdami Fajri50% (2)
- Ayushi Patel A044 R SoftwareDocument8 pagesAyushi Patel A044 R SoftwareAyushi PatelNo ratings yet
- Mathematical Applications in Economics ECON 262 Practice Set 1Document4 pagesMathematical Applications in Economics ECON 262 Practice Set 1Salman FarooqNo ratings yet
- 1916034_CE1.docDocument10 pages1916034_CE1.docGoutam MandalNo ratings yet
- Example EconometricsDocument6 pagesExample Econometricsyoutube2301No ratings yet
- Econ 3201 Final Exam: Key Concepts and ModelsDocument12 pagesEcon 3201 Final Exam: Key Concepts and ModelsJiten NakraniNo ratings yet
- Lecture 01Document26 pagesLecture 01mohamed ezzatNo ratings yet
- Statistics and ProbabilityDocument8 pagesStatistics and ProbabilityAlesya alesyaNo ratings yet
- STAT 431 - Practice Term Test # 2Document4 pagesSTAT 431 - Practice Term Test # 2Sarika UppalNo ratings yet
- ML Question Bank and SolDocument12 pagesML Question Bank and SolPrabhu Prasad DevNo ratings yet
- IE 451 Fall 2023-2024 Homework 4 SolutionsDocument19 pagesIE 451 Fall 2023-2024 Homework 4 SolutionsAbdullah BingaziNo ratings yet
- Which stock offers the best investment opportunityDocument9 pagesWhich stock offers the best investment opportunityAi Tien TranNo ratings yet
- Statistics For Criminology and Criminal Justice 4Th Edition Bachman Solutions Manual Full Chapter PDFDocument29 pagesStatistics For Criminology and Criminal Justice 4Th Edition Bachman Solutions Manual Full Chapter PDFjennie.walker479100% (11)
- SQL ManufacturingDocument5 pagesSQL Manufacturingjavitillo03casNo ratings yet
- Analog Vs DigitalDocument6 pagesAnalog Vs DigitalMohan AwasthyNo ratings yet
- Varisoft Eq 100 Ti c0920 CosmotecDocument3 pagesVarisoft Eq 100 Ti c0920 CosmotecHayala MotaNo ratings yet
- SJ-20160119164028-015-ZXR10 5960 Series (V3.02.20) All 10-Gigabit Data Center Switch Configuration Guide (IDC)Document127 pagesSJ-20160119164028-015-ZXR10 5960 Series (V3.02.20) All 10-Gigabit Data Center Switch Configuration Guide (IDC)keslleyNo ratings yet
- Logarithmic Spiral Antenna Covers 0.4-3.8 GHzDocument8 pagesLogarithmic Spiral Antenna Covers 0.4-3.8 GHzmarcosnt66No ratings yet
- SPSS ImplicationsDocument3 pagesSPSS ImplicationsAnonymous MMNqiyxBUNo ratings yet
- Cyclohexane Production Workshop: Introduction To Aspen PlusDocument2 pagesCyclohexane Production Workshop: Introduction To Aspen Plusnico123456789No ratings yet
- Prokofiev NotesDocument14 pagesProkofiev NotesUlyssesm90No ratings yet
- Home Lighting PDFDocument8 pagesHome Lighting PDFpilapil_j100% (1)
- 1 to 10 DSBDA case studyDocument17 pages1 to 10 DSBDA case studyGanesh BagulNo ratings yet
- HW#1 Mos PDFDocument2 pagesHW#1 Mos PDFmuhammadNo ratings yet
- Quick Disconnect Coupling DataDocument2 pagesQuick Disconnect Coupling DataEagle1968No ratings yet
- Amarillo 1000 1800 Repair ManualDocument32 pagesAmarillo 1000 1800 Repair ManualmuazmaslanNo ratings yet
- Astm D1014 PDFDocument4 pagesAstm D1014 PDFabilio_j_vieiraNo ratings yet
- 7805T Ecg-960Document2 pages7805T Ecg-960bellscbNo ratings yet
- The Heuristic Methods For Assembly Line Balancing ProblemDocument13 pagesThe Heuristic Methods For Assembly Line Balancing Problemmg_catanaNo ratings yet
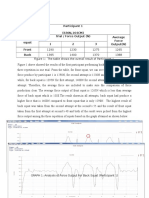
- Result: Participant 1 (630N, 164CM) Type of Squat Trial / Force Output (N) Average Force Output (N) 1 2 3 Front BackDocument5 pagesResult: Participant 1 (630N, 164CM) Type of Squat Trial / Force Output (N) Average Force Output (N) 1 2 3 Front BackpatenggNo ratings yet
- Bascom Avr Demonstration BoardDocument8 pagesBascom Avr Demonstration BoardNitish KumarNo ratings yet
- ChlorantraniliproleDocument3 pagesChlorantraniliproleLaura GuarguatiNo ratings yet
- Protein MetabolismDocument18 pagesProtein MetabolismAbdul RehmanNo ratings yet
- Factors That Determine Reaction SpontaneityDocument5 pagesFactors That Determine Reaction SpontaneityDavid PetalcurinNo ratings yet