You might also like
- Klein & Kulick Scandolous ActsDocument20 pagesKlein & Kulick Scandolous ActsClaudia Costa GarcíaNo ratings yet
- BlackScholesNN PDFDocument15 pagesBlackScholesNN PDFPaula GusmãoNo ratings yet
- Lecun DLHardware Isscc2019Document8 pagesLecun DLHardware Isscc2019claudiaNo ratings yet
- Basic Introduction To Convolutional Neural Network in Deep LearningDocument9 pagesBasic Introduction To Convolutional Neural Network in Deep LearningNarsini AKSHARANo ratings yet
- Practical On Artificial Neural Networks: Amrender KumarDocument11 pagesPractical On Artificial Neural Networks: Amrender Kumarnawel dounaneNo ratings yet
- Institute of Engineering and Technology Davv, Indore: Lab Assingment OnDocument14 pagesInstitute of Engineering and Technology Davv, Indore: Lab Assingment OnNikhil KhatloiyaNo ratings yet
- FlannDocument8 pagesFlannNadeem UddinNo ratings yet
- 4th Unit Aktu Machine LearningDocument9 pages4th Unit Aktu Machine LearningANMOL SINGHNo ratings yet
- Backpropagation Through Time What It Does and How To Do ItDocument11 pagesBackpropagation Through Time What It Does and How To Do ItDamiApacheNo ratings yet
- DL Unit-3Document9 pagesDL Unit-3Kalpana MNo ratings yet
- Ai Ga1Document7 pagesAi Ga1Darshnik DeepNo ratings yet
- Deep Learning Approach For Object Detection Using CNN: AbstractDocument7 pagesDeep Learning Approach For Object Detection Using CNN: AbstractAYUSH MISHRANo ratings yet
- Deep Learning: (Most Slides Courtesy of Mauro Castelli, New University of Lisbon, Portugal)Document40 pagesDeep Learning: (Most Slides Courtesy of Mauro Castelli, New University of Lisbon, Portugal)Luca GuglielmiNo ratings yet
- Abhi PresentationDocument20 pagesAbhi PresentationChella venkannababuNo ratings yet
- Demystifying CNN MathDocument19 pagesDemystifying CNN MathfaisalNo ratings yet
- Backpropagation Through Time: What It Does and Howtodoit: Paul WerbosDocument11 pagesBackpropagation Through Time: What It Does and Howtodoit: Paul WerbostitaNo ratings yet
- Deep Learning Unit-IIIDocument9 pagesDeep Learning Unit-IIIAnonymous xMYE0TiNBcNo ratings yet
- UNIT-1 Foundations of Deep LearningDocument51 pagesUNIT-1 Foundations of Deep Learningbhavana100% (1)
- Convolutional Neural Networks: Computer VisionDocument14 pagesConvolutional Neural Networks: Computer VisionVIDUSHINo ratings yet
- 1 Deep Learning PrimerDocument56 pages1 Deep Learning PrimerRoque CaicedoNo ratings yet
- Lecture 8Document113 pagesLecture 8Ruben KempterNo ratings yet
- Every Model Learned by Gradient Descent Is Approximately A Kernel MachineDocument12 pagesEvery Model Learned by Gradient Descent Is Approximately A Kernel Machinekallenhard1No ratings yet
- A Brief History of Deep Learning - DATAVERSITYDocument7 pagesA Brief History of Deep Learning - DATAVERSITYMartinLukNo ratings yet
- Backpropagation Algorithm Explained in 40 CharactersDocument73 pagesBackpropagation Algorithm Explained in 40 CharacterstesscarcamoNo ratings yet
- DSA THEORY DADocument41 pagesDSA THEORY DAswastik rajNo ratings yet
- One-Shot Learning With Memory-Augmented Neural NetworksDocument13 pagesOne-Shot Learning With Memory-Augmented Neural Networksa4104165No ratings yet
- ANN Overview: Artificial Neural Networks ExplainedDocument31 pagesANN Overview: Artificial Neural Networks ExplainedMuhanad Al-khalisyNo ratings yet
- Assign 1 Soft CompDocument12 pagesAssign 1 Soft Compsharmasunishka30No ratings yet
- Demystifying Deep Convolutional Neural Networks - Adam Harley (2014) CNN PDFDocument27 pagesDemystifying Deep Convolutional Neural Networks - Adam Harley (2014) CNN PDFharislyeNo ratings yet
- CS407 Neural Computation: Lecturer: A/Prof. M. BennamounDocument34 pagesCS407 Neural Computation: Lecturer: A/Prof. M. Bennamounanant_nimkar9243No ratings yet
- Deep Learning Interview QuestionsDocument17 pagesDeep Learning Interview QuestionsSumathi MNo ratings yet
- An Introduction To Neural Networks: Instituto Tecgraf PUC-Rio Nome: Fernanda Duarte Orientador: Marcelo GattassDocument45 pagesAn Introduction To Neural Networks: Instituto Tecgraf PUC-Rio Nome: Fernanda Duarte Orientador: Marcelo GattassGiGa GFNo ratings yet
- Neural Networks in Business: Techniques and Applications For The Operations ResearcherDocument22 pagesNeural Networks in Business: Techniques and Applications For The Operations Researchernauli10No ratings yet
- Project ReportDocument13 pagesProject ReportMonica CocutNo ratings yet
- Complete Glossary of Keras Neural Network Layers With CodeDocument16 pagesComplete Glossary of Keras Neural Network Layers With CodeRadha KilariNo ratings yet
- Imagify Reconstruction of High - Resolution Images From Degraded ImagesDocument5 pagesImagify Reconstruction of High - Resolution Images From Degraded ImagesIJRASETPublicationsNo ratings yet
- Deep Learning Methods OverviewDocument12 pagesDeep Learning Methods OverviewOussama El B'charriNo ratings yet
- The Weka Multilayer Perceptron Classifier: Daniel I. MORARIU, Radu G. Creţulescu, Macarie BreazuDocument9 pagesThe Weka Multilayer Perceptron Classifier: Daniel I. MORARIU, Radu G. Creţulescu, Macarie BreazuAliza KhanNo ratings yet
- Artificial Intelligence in AerospaceDocument25 pagesArtificial Intelligence in AerospaceFael SermanNo ratings yet
- Deep Learning PDFDocument55 pagesDeep Learning PDFNitesh Kumar SharmaNo ratings yet
- Feedforward Neural Networks: An IntroductionDocument16 pagesFeedforward Neural Networks: An Introductionranjan2234No ratings yet
- Deep Learning: Nicholas G. Polson Vadim O. SokolovDocument18 pagesDeep Learning: Nicholas G. Polson Vadim O. SokolovAbdul HamidNo ratings yet
- DL Unit3Document8 pagesDL Unit3Anonymous xMYE0TiNBcNo ratings yet
- (Readings) Deep Learning Applications in Business ActivitiesDocument6 pages(Readings) Deep Learning Applications in Business ActivitiesJhoy CastroNo ratings yet
- FRJ PaperDocument9 pagesFRJ PaperMattNo ratings yet
- Neural Network Tool BoxDocument6 pagesNeural Network Tool BoxPoojaNo ratings yet
- Evolving Neural Network Using Real Coded Genetic Algorithm (GA) For Multispectral Image ClassificationDocument13 pagesEvolving Neural Network Using Real Coded Genetic Algorithm (GA) For Multispectral Image Classificationjkl316No ratings yet
- Content-Based Image Retrieval TutorialDocument16 pagesContent-Based Image Retrieval Tutorialwenhao zhangNo ratings yet
- Neural NetworksDocument12 pagesNeural NetworksP PNo ratings yet
- Applicable Artificial Intelligence: Introduction To Neural NetworksDocument36 pagesApplicable Artificial Intelligence: Introduction To Neural Networksmuhammed suhailNo ratings yet
- Unit 4Document57 pagesUnit 4HARIPRASATH PANNEER SELVAM100% (1)
- Deep Learning in Astronomy: Classifying GalaxiesDocument6 pagesDeep Learning in Astronomy: Classifying GalaxiesAniket SujayNo ratings yet
- Machine Learning Data Mining: ProblemsDocument27 pagesMachine Learning Data Mining: ProblemsnanaoNo ratings yet
- Artificial Intelligence Techniques in Solar Energy ApplicationsDocument26 pagesArtificial Intelligence Techniques in Solar Energy ApplicationsParas GupteNo ratings yet
- Convolutional Neural Networks & ZapierDocument75 pagesConvolutional Neural Networks & ZapierTimer InsightNo ratings yet
- Deep Learning Assignment 1 Solution: Name: Vivek Rana Roll No.: 1709113908Document5 pagesDeep Learning Assignment 1 Solution: Name: Vivek Rana Roll No.: 1709113908vikNo ratings yet
- Unit - 1 Deep Learning 3-2Document15 pagesUnit - 1 Deep Learning 3-2Ps NaveenNo ratings yet
- Unit 03 - Neural Networks - MDDocument24 pagesUnit 03 - Neural Networks - MDMega Silvia HasugianNo ratings yet
- PARALLEL NEURAL NETWORK FOR HANDWRITING RECOGNITIONDocument6 pagesPARALLEL NEURAL NETWORK FOR HANDWRITING RECOGNITIONDavid TodorovNo ratings yet
- TensorFlow in 1 Day: Make your own Neural NetworkFrom EverandTensorFlow in 1 Day: Make your own Neural NetworkRating: 4 out of 5 stars4/5 (8)
- Enhancing Deep Learning Performance Using Displaced Rectifier Linear UnitFrom EverandEnhancing Deep Learning Performance Using Displaced Rectifier Linear UnitNo ratings yet
- 99th Indian Science Congress (Bhubaneshwar)Document95 pages99th Indian Science Congress (Bhubaneshwar)Aadarsh DasNo ratings yet
- Catalogo Head FixDocument8 pagesCatalogo Head FixANDREA RAMOSNo ratings yet
- Boala Cronica Obstructive: BpocDocument21 pagesBoala Cronica Obstructive: BpocNicoleta IliescuNo ratings yet
- Timber, PVCu and aluminium window and door hardware systemsDocument24 pagesTimber, PVCu and aluminium window and door hardware systemsOmul Fara NumeNo ratings yet
- PediculosisDocument14 pagesPediculosisREYMARK HACOSTA100% (1)
- 20ME901 Automobile Engineering Unit 3Document74 pages20ME901 Automobile Engineering Unit 36044 sriramNo ratings yet
- Sia Mock+Test 1 Csat Updated CompressedDocument216 pagesSia Mock+Test 1 Csat Updated Compressedpooja bhatiNo ratings yet
- Akhmatova, Anna - 45 Poems With Requiem PDFDocument79 pagesAkhmatova, Anna - 45 Poems With Requiem PDFAnonymous 6N5Ew3No ratings yet
- Telephone Triggered SwitchesDocument22 pagesTelephone Triggered SwitchesSuresh Shah100% (1)
- How Do I Prepare For Public Administration For IAS by Myself Without Any Coaching? Which Books Should I Follow?Document3 pagesHow Do I Prepare For Public Administration For IAS by Myself Without Any Coaching? Which Books Should I Follow?saiviswanath0990100% (1)
- District Wise List of Colleges Under The Juridiction of MRSPTU BathindaDocument13 pagesDistrict Wise List of Colleges Under The Juridiction of MRSPTU BathindaGurpreet SandhuNo ratings yet
- HHG4M - Lifespan Development Textbook Lesson 2Document95 pagesHHG4M - Lifespan Development Textbook Lesson 2Lubomira SucheckiNo ratings yet
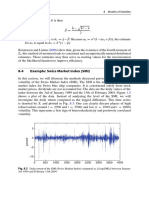
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- BCRW Course - Answer-Booklet PDFDocument18 pagesBCRW Course - Answer-Booklet PDFSarah ChaudharyNo ratings yet
- Lineapelle: Leather & Non-LeatherDocument16 pagesLineapelle: Leather & Non-LeatherShikha BhartiNo ratings yet
- DNA Affirmative - MSDI 2015Document146 pagesDNA Affirmative - MSDI 2015Michael TangNo ratings yet
- Early Diabetic Risk Prediction Using Machine Learning Classification TechniquesDocument6 pagesEarly Diabetic Risk Prediction Using Machine Learning Classification TechniquesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Friction, Gravity and Energy TransformationsDocument12 pagesFriction, Gravity and Energy TransformationsDaiserie LlanezaNo ratings yet
- English Extra Conversation Club International Women's DayDocument2 pagesEnglish Extra Conversation Club International Women's Dayevagloria11No ratings yet
- Telecommunications TechnicianDocument4 pagesTelecommunications Technicianapi-78381064No ratings yet
- 1 PBDocument11 pages1 PBAnggita Wulan RezkyanaNo ratings yet
- EST I - Literacy Test I (Language)Document20 pagesEST I - Literacy Test I (Language)Mohammed Abdallah100% (1)
- Tuberculin Skin Test: Facilitator GuideDocument31 pagesTuberculin Skin Test: Facilitator GuideTiwi NaloleNo ratings yet
- Astm D 664 - 07Document8 pagesAstm D 664 - 07Alfonso MartínezNo ratings yet
- SCJP 1.6 Mock Exam Questions (60 QuestionsDocument32 pagesSCJP 1.6 Mock Exam Questions (60 QuestionsManas GhoshNo ratings yet
- DLL Grade7 First 1solutions ConcentrationDocument5 pagesDLL Grade7 First 1solutions ConcentrationJaneth de JuanNo ratings yet
- DCAD OverviewDocument9 pagesDCAD OverviewSue KimNo ratings yet
- 2 5 Marking ScheduleDocument6 pages2 5 Marking Scheduleapi-218511741No ratings yet
- 41 PDFsam Redis CookbookDocument5 pages41 PDFsam Redis CookbookHữu Hưởng NguyễnNo ratings yet