You might also like
- Risk, Reliability and Sustainable Remediation in the Field of Civil and Environmental EngineeringFrom EverandRisk, Reliability and Sustainable Remediation in the Field of Civil and Environmental EngineeringThendiyath RoshniNo ratings yet
- GIS-based Landslide Susceptibility Mapping by AHP Method, A Case Study, Dena City, IranDocument10 pagesGIS-based Landslide Susceptibility Mapping by AHP Method, A Case Study, Dena City, IranAneel AhmedNo ratings yet
- The Impact of Fracture On Oil ProductionDocument20 pagesThe Impact of Fracture On Oil ProductionFaniyi Hussein KehindeNo ratings yet
- Remote SensingDocument29 pagesRemote SensingAfiat KhanNo ratings yet
- Machine-Learning Algorithms For Mapping Debris-Covered Glaciers: The Hunza Basin Case StudyDocument11 pagesMachine-Learning Algorithms For Mapping Debris-Covered Glaciers: The Hunza Basin Case StudyDoct shafiqNo ratings yet
- Water 14 03320 v2Document20 pagesWater 14 03320 v2Thoa HồNo ratings yet
- Nagendran, Sharan Kumar., Et Al, 2019Document9 pagesNagendran, Sharan Kumar., Et Al, 2019Melikhann KarakasNo ratings yet
- Fulltext-CatenaDocument13 pagesFulltext-CatenaAbdelhalim MiftahNo ratings yet
- GIS-Based Landslide Susceptibility Mapping For Land Use Planning and Risk AssessmentDocument28 pagesGIS-Based Landslide Susceptibility Mapping For Land Use Planning and Risk AssessmentVina TeachNo ratings yet
- Rock Slopes Risk Assessment Based On Advanced Geostructural Survey TechniquesDocument12 pagesRock Slopes Risk Assessment Based On Advanced Geostructural Survey TechniquesNimra KhanNo ratings yet
- From Drone-Based Remote Sensing To Digital Outcrop PDFDocument8 pagesFrom Drone-Based Remote Sensing To Digital Outcrop PDFAditya Rizky WibowoNo ratings yet
- Remotesensing 14 03021 v2Document28 pagesRemotesensing 14 03021 v2ansariNo ratings yet
- Landslide Risk Analysis Using Artificial Neural Ne PDFDocument16 pagesLandslide Risk Analysis Using Artificial Neural Ne PDFBambang SiswantoNo ratings yet
- Geospatial TechnologyDocument20 pagesGeospatial TechnologyParag Jyoti DuttaNo ratings yet
- QUAESTIONESGEOGRAPHICAEDocument15 pagesQUAESTIONESGEOGRAPHICAEarkaranNo ratings yet
- Analysis of Debris Flow Damage Using High-ResolutiDocument15 pagesAnalysis of Debris Flow Damage Using High-ResolutiByron PerezNo ratings yet
- Spatiotemporal Landslide Susceptibility Mapping Using Machine Learning Models_ a Case Study From DistrDocument14 pagesSpatiotemporal Landslide Susceptibility Mapping Using Machine Learning Models_ a Case Study From DistroscarmauricionietomolinaNo ratings yet
- Miko Bezak FrontiersDocument12 pagesMiko Bezak FrontiersMARCOS ABRAHAM ALEJANDRO BALDOCEDA HUAYASNo ratings yet
- Assessment of Soil Compaction Properties Based OnDocument8 pagesAssessment of Soil Compaction Properties Based OnHoracio Ramos SaldañaNo ratings yet
- 1 s2.0 S0012825222000289 MainDocument22 pages1 s2.0 S0012825222000289 MainJorge D. MarquesNo ratings yet
- Remotesensing 13 00421 v2Document21 pagesRemotesensing 13 00421 v2RezaNo ratings yet
- Rock Slope Stability Analysis by Using Integrated ApproachDocument24 pagesRock Slope Stability Analysis by Using Integrated ApproachMezamMohammedCherifNo ratings yet
- Himan, S. and Mazlan, H. (2015) - Landslide Susceptibility Mapping Using GIS Bases StatsModel and RSDocument15 pagesHiman, S. and Mazlan, H. (2015) - Landslide Susceptibility Mapping Using GIS Bases StatsModel and RSJESUS ZAVALANo ratings yet
- 1 PBDocument12 pages1 PBAntona AnggitaNo ratings yet
- Marjanovic 2009Document6 pagesMarjanovic 2009akbar kushanoorNo ratings yet
- 2013geom190desy SchoorlDocument9 pages2013geom190desy SchoorlNino PumaNo ratings yet
- A GIS Tool For Infinite Slope Stability Analysis GIS - 2021 - Geoscience FrontiDocument13 pagesA GIS Tool For Infinite Slope Stability Analysis GIS - 2021 - Geoscience FrontichestherNo ratings yet
- Deep Learning Method of Landslide Inventory Map With Imbalanced Samples in Optical Remote SensingDocument17 pagesDeep Learning Method of Landslide Inventory Map With Imbalanced Samples in Optical Remote Sensingnicolascabellos99No ratings yet
- Gatto Et Al. 2022bDocument13 pagesGatto Et Al. 2022bMichele GattoNo ratings yet
- Preprints202302 0390 v1Document32 pagesPreprints202302 0390 v1Alexandra JarnáNo ratings yet
- Skema Klasifikasi Anbalagan 1992Document10 pagesSkema Klasifikasi Anbalagan 1992MelindaAlamsyahNo ratings yet
- Remote Sensing: A Meta-Learning Approach of Optimisation For Spatial Prediction of LandslidesDocument30 pagesRemote Sensing: A Meta-Learning Approach of Optimisation For Spatial Prediction of LandslidesMarco ReateguiNo ratings yet
- Evaluation of Soil Erosion by RUSLE Model in Mount Guera: Issa Justin Laougué, Djebé Mbaindogoum, Mahamat Ali MustaphaDocument20 pagesEvaluation of Soil Erosion by RUSLE Model in Mount Guera: Issa Justin Laougué, Djebé Mbaindogoum, Mahamat Ali MustaphaIssa Justin LaougueNo ratings yet
- ACRS21 072 ProceedingDocument11 pagesACRS21 072 ProceedingYizeth Tellez VargasNo ratings yet
- Categorization of Mineral Resources Based On Different Geostatistical Simulation Algorithms: A Case Study From An Iron Ore DepositDocument25 pagesCategorization of Mineral Resources Based On Different Geostatistical Simulation Algorithms: A Case Study From An Iron Ore DepositSyahrul AzizNo ratings yet
- Seismic Refraction Method in The Determination of Site CharacteristicsDocument12 pagesSeismic Refraction Method in The Determination of Site CharacteristicsAngie V AceroNo ratings yet
- Measurement While Drilling TechniqueDocument9 pagesMeasurement While Drilling TechniqueDavid Umiña YanaNo ratings yet
- SPE-200021-MS Learning From Behavioral Frac Maps: A Montney Case Study in Integration of Modern Microseismic and Production Data AnalysesDocument33 pagesSPE-200021-MS Learning From Behavioral Frac Maps: A Montney Case Study in Integration of Modern Microseismic and Production Data AnalysesGabriel EduardoNo ratings yet
- Isprsannals II 5 385 2014Document7 pagesIsprsannals II 5 385 2014Pros Cons StatementNo ratings yet
- ANOTASI JURNAL PENGINDERAAN JAUH DAN SIG UNTUK MITIGASI BENCANA (LONGSORDocument11 pagesANOTASI JURNAL PENGINDERAAN JAUH DAN SIG UNTUK MITIGASI BENCANA (LONGSORHana FairuzNo ratings yet
- drones-NayyerDocument18 pagesdrones-Nayyerengr_n_n_malikNo ratings yet
- Sustainability 15 11233Document17 pagesSustainability 15 11233Zulkifli HaidarNo ratings yet
- Finite Element Analysis of Landslide-Prone Road Cut Slopes in the HimalayasDocument15 pagesFinite Element Analysis of Landslide-Prone Road Cut Slopes in the HimalayasRatan DasNo ratings yet
- Landslide Susceptibility Mapping Using Knowledge DDocument18 pagesLandslide Susceptibility Mapping Using Knowledge DnishantNo ratings yet
- Remotesensing 12 03389 PDFDocument27 pagesRemotesensing 12 03389 PDFGeoSolutions VinaNo ratings yet
- Applsci 11 06148 v2Document18 pagesApplsci 11 06148 v2Nhât LươngNo ratings yet
- Remotesensing 15 02540Document20 pagesRemotesensing 15 02540Aiman ChmireqNo ratings yet
- Mass Movement Susceptibility MappingDocument7 pagesMass Movement Susceptibility MappingDeysi PaicoNo ratings yet
- Topographic Position Index To Landform Classification and Spatial Planning, Using GIS, For Wadi Araba, South West JordanDocument24 pagesTopographic Position Index To Landform Classification and Spatial Planning, Using GIS, For Wadi Araba, South West Jordankp61mustafaNo ratings yet
- 02 - Geological Interpretation For Resource Modelling and Estimation - J H Duke and P J HannaDocument10 pages02 - Geological Interpretation For Resource Modelling and Estimation - J H Duke and P J HannaIron Huayhua Chávez100% (1)
- Comparing liquefaction predictions of two constitutive soil models using MPMDocument12 pagesComparing liquefaction predictions of two constitutive soil models using MPMTrung Trị LêNo ratings yet
- Engineering Geology: A B C B B D eDocument13 pagesEngineering Geology: A B C B B D eJohn GallegoNo ratings yet
- Sustainability 12 05784Document19 pagesSustainability 12 05784Xavier AbainzaNo ratings yet
- Structure-from-Motion Photogrammetry: A Novel, Low-Cost Tool For Geomorphological ApplicationsDocument16 pagesStructure-from-Motion Photogrammetry: A Novel, Low-Cost Tool For Geomorphological ApplicationsIka Nur FitriasariNo ratings yet
- Evaluation of 3D Seismic Survey Design Parameters Through Ray Trace Modeling and Seismic Illumination Studies: A Case StudyDocument11 pagesEvaluation of 3D Seismic Survey Design Parameters Through Ray Trace Modeling and Seismic Illumination Studies: A Case Studyfirman_SANo ratings yet
- 1 s2.0 S167498712030116X MainDocument9 pages1 s2.0 S167498712030116X MainYeersainth Figueroa GomezNo ratings yet
- DeGiorgis12. Classifiers For The Detection of Flood-Prone AreasDocument14 pagesDeGiorgis12. Classifiers For The Detection of Flood-Prone AreasPiero CostabileNo ratings yet
- Izhar Jiskani Fault Orientation Modeling of Sonda Jherruck Coalfield PakistanDocument9 pagesIzhar Jiskani Fault Orientation Modeling of Sonda Jherruck Coalfield PakistanAbdul Shakoor NuhrioNo ratings yet
- Measurement-While-Drilling Technique PDFDocument9 pagesMeasurement-While-Drilling Technique PDFWilkhen ChuraNo ratings yet
- Boutal 2018Document16 pagesBoutal 2018lozaNo ratings yet
- Acoustic Louver Product Data SheetDocument2 pagesAcoustic Louver Product Data SheetRichard OonNo ratings yet
- Chin Hin - Annual Report 2020Document255 pagesChin Hin - Annual Report 2020Richard OonNo ratings yet
- Acoustic Louver Product Data SheetDocument2 pagesAcoustic Louver Product Data SheetRichard OonNo ratings yet
- Weatherbond Solareflect: Technical Data SheetDocument2 pagesWeatherbond Solareflect: Technical Data SheetRichard OonNo ratings yet
- UOA Dev AR 2020Document156 pagesUOA Dev AR 2020Richard OonNo ratings yet
- Legacy Catalogue - 210205Document13 pagesLegacy Catalogue - 210205Richard OonNo ratings yet
- Polymers: Mechanical Properties of Fibre Reinforced Polymers Under Elevated Temperatures: An OverviewDocument31 pagesPolymers: Mechanical Properties of Fibre Reinforced Polymers Under Elevated Temperatures: An OverviewRichard OonNo ratings yet
- UOADEV - CG Report 31.12.2020Document40 pagesUOADEV - CG Report 31.12.2020Richard OonNo ratings yet
- Bim Phrasebook Pocket Guide PDFDocument8 pagesBim Phrasebook Pocket Guide PDFRichard OonNo ratings yet
- Product Catalogue (ARZTECH SOLUTION) PDFDocument5 pagesProduct Catalogue (ARZTECH SOLUTION) PDFAzizy YusofNo ratings yet
- TROP AnnualReport2019 PDFDocument285 pagesTROP AnnualReport2019 PDFRichard OonNo ratings yet
- OPSBersepaduCNY07 PDFDocument27 pagesOPSBersepaduCNY07 PDFRichard OonNo ratings yet
- Mynews Ar2019Document168 pagesMynews Ar2019Richard OonNo ratings yet
- Komune Living Wellness EFactSheetDocument3 pagesKomune Living Wellness EFactSheetRichard OonNo ratings yet
- HGB - Ar 2019Document173 pagesHGB - Ar 2019Richard OonNo ratings yet
- Series 2: Project Management: Understanding and Using 6 Basic ToolsDocument16 pagesSeries 2: Project Management: Understanding and Using 6 Basic ToolsRichard OonNo ratings yet
- DWGuide 2017 ENGFINALWEBDocument84 pagesDWGuide 2017 ENGFINALWEBBrad SusuNo ratings yet
- OPSBersepaduCNY07 PDFDocument27 pagesOPSBersepaduCNY07 PDFRichard OonNo ratings yet
- 1 PBDocument11 pages1 PBRichard OonNo ratings yet
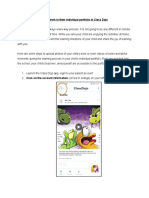
- How To Post Child's Work in Their Individual Portfolio in Class Dojo PDFDocument6 pagesHow To Post Child's Work in Their Individual Portfolio in Class Dojo PDFRichard OonNo ratings yet
- AutoCAD Tutorial - Draw Front View of Mechanical PartDocument10 pagesAutoCAD Tutorial - Draw Front View of Mechanical PartvintiloiusNo ratings yet
- TDS Sika Tile AdhesiveDocument3 pagesTDS Sika Tile AdhesiveRichard OonNo ratings yet
- MRR 243 A Study On Commercial Vehicle Speed and Its Operational CharacteristicsDocument60 pagesMRR 243 A Study On Commercial Vehicle Speed and Its Operational CharacteristicsRichard OonNo ratings yet
- How To Post Child's Work in Their Individual Portfolio in Class Dojo PDFDocument6 pagesHow To Post Child's Work in Their Individual Portfolio in Class Dojo PDFRichard OonNo ratings yet
- Sikalastic 612Document6 pagesSikalastic 612Richard OonNo ratings yet
- WBSELTxxx WWDocument2 pagesWBSELTxxx WWRichard OonNo ratings yet
- Sikabit® W-15: Wet-Bonded Waterproofing MembraneDocument8 pagesSikabit® W-15: Wet-Bonded Waterproofing MembraneRichard OonNo ratings yet
- France fines UBS record €3.7b in tax fraud caseDocument33 pagesFrance fines UBS record €3.7b in tax fraud caseRichard OonNo ratings yet
- Analogvsdigitalvsvoip 161129040115 PDFDocument1 pageAnalogvsdigitalvsvoip 161129040115 PDFRichard OonNo ratings yet
- Amery Hill School Newsletter Highlights Green Energy Project Win and New Facilities PlansDocument20 pagesAmery Hill School Newsletter Highlights Green Energy Project Win and New Facilities PlansboredokNo ratings yet
- Leonardo 2010 PresentationDocument21 pagesLeonardo 2010 Presentationapi-236016801No ratings yet
- Molen 1983Document17 pagesMolen 1983Cristell BiñasNo ratings yet
- Glogster Lesson PlanDocument2 pagesGlogster Lesson Plannwhite325No ratings yet
- Motivating Climate PLPDocument29 pagesMotivating Climate PLPclaire yowsNo ratings yet
- ABORTIONDocument6 pagesABORTIONMarice Abigail MarquezNo ratings yet
- A222 Tma01Document4 pagesA222 Tma01Joseph MurrayNo ratings yet
- Upgrading To Cisco Unified Contact Center Express, Release 8.5Document28 pagesUpgrading To Cisco Unified Contact Center Express, Release 8.5Jay AllenNo ratings yet
- EEE314 Data Communication and Computer Networks LabDocument2 pagesEEE314 Data Communication and Computer Networks LabAbdul MoqeetNo ratings yet
- 56 239 1 PBDocument11 pages56 239 1 PBahmad acengNo ratings yet
- Tyler Junior College Catalog 2022-2023 - CopieDocument289 pagesTyler Junior College Catalog 2022-2023 - Copieغير نفسكNo ratings yet
- Social Issues Essay ReflectionDocument2 pagesSocial Issues Essay Reflectionapi-457004717No ratings yet
- Circular Seating Arrangement Free PDF For Upcoming Prelims ExamsDocument14 pagesCircular Seating Arrangement Free PDF For Upcoming Prelims ExamsBiswapriyo MondalNo ratings yet
- Employment Transition of Fresh Business Graduates An AssessmentDocument49 pagesEmployment Transition of Fresh Business Graduates An AssessmentCyan Vincent CanlasNo ratings yet
- Prof Ed 310Document5 pagesProf Ed 310Argie Villacote BarracaNo ratings yet
- Annual Viva Examination 2022 - 2023: Date Sheet Class - Viii Date & Day SubjectDocument2 pagesAnnual Viva Examination 2022 - 2023: Date Sheet Class - Viii Date & Day SubjectAKARSH GAMING YTNo ratings yet
- Journey To JamestownDocument5 pagesJourney To Jamestownapi-238115483No ratings yet
- Teaching Case Study: Group D3Document16 pagesTeaching Case Study: Group D3Janel Scholine100% (1)
- Requirement GatheringDocument11 pagesRequirement GatheringHira FarooqNo ratings yet
- CV - Neway Yifru AdamuskilllessDocument2 pagesCV - Neway Yifru AdamuskilllessNeway YifruNo ratings yet
- Ccca Teacher Training Office: Ludic Activities During Synchronous ClassesDocument10 pagesCcca Teacher Training Office: Ludic Activities During Synchronous ClassesKelly LondoñoNo ratings yet
- DSM-IV and DSM-5 Criteria For The Personality Disorders 5-1-12Document15 pagesDSM-IV and DSM-5 Criteria For The Personality Disorders 5-1-12ouestlechatdememeNo ratings yet
- Geometry Honors 2012-2013 Semester Exams Practice Materials Semester 1Document59 pagesGeometry Honors 2012-2013 Semester Exams Practice Materials Semester 1peachcrushNo ratings yet
- Really Great Reading Diagnostic Decoding SurveysDocument20 pagesReally Great Reading Diagnostic Decoding Surveysapi-331571310100% (1)
- Al Anizi2009Document11 pagesAl Anizi2009Yuzar StuffNo ratings yet
- IELTS Writing Task 2 PatternDocument18 pagesIELTS Writing Task 2 Patternfaisal abdaNo ratings yet
- Cultural Anthropology (Bonvillain)Document1,980 pagesCultural Anthropology (Bonvillain)Mel NonymusNo ratings yet
- Ah102 Syllabus 20180417lDocument7 pagesAh102 Syllabus 20180417lapi-399629502No ratings yet
- Indah Nurmala Sari 27 33Document8 pagesIndah Nurmala Sari 27 33Arbianus SurbaktiNo ratings yet
- Unidad 8prDocument2 pagesUnidad 8prJose Saul Sanchez QuentasiNo ratings yet
- Roxane Gay & Everand Originals: My Year of Psychedelics: Lessons on Better LivingFrom EverandRoxane Gay & Everand Originals: My Year of Psychedelics: Lessons on Better LivingRating: 3.5 out of 5 stars3.5/5 (33)
- Roxane Gay & Everand Originals: My Year of Psychedelics: Lessons on Better LivingFrom EverandRoxane Gay & Everand Originals: My Year of Psychedelics: Lessons on Better LivingRating: 5 out of 5 stars5/5 (5)
- Wayfinding: The Science and Mystery of How Humans Navigate the WorldFrom EverandWayfinding: The Science and Mystery of How Humans Navigate the WorldRating: 4.5 out of 5 stars4.5/5 (18)
- Alex & Me: How a Scientist and a Parrot Discovered a Hidden World of Animal Intelligence—and Formed a Deep Bond in the ProcessFrom EverandAlex & Me: How a Scientist and a Parrot Discovered a Hidden World of Animal Intelligence—and Formed a Deep Bond in the ProcessNo ratings yet
- Fire Season: Field Notes from a Wilderness LookoutFrom EverandFire Season: Field Notes from a Wilderness LookoutRating: 4 out of 5 stars4/5 (142)
- Dark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseFrom EverandDark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseRating: 3.5 out of 5 stars3.5/5 (69)
- The Other End of the Leash: Why We Do What We Do Around DogsFrom EverandThe Other End of the Leash: Why We Do What We Do Around DogsRating: 5 out of 5 stars5/5 (63)
- World of Wonders: In Praise of Fireflies, Whale Sharks, and Other AstonishmentsFrom EverandWorld of Wonders: In Praise of Fireflies, Whale Sharks, and Other AstonishmentsRating: 4 out of 5 stars4/5 (222)
- The Ancestor's Tale: A Pilgrimage to the Dawn of EvolutionFrom EverandThe Ancestor's Tale: A Pilgrimage to the Dawn of EvolutionRating: 4 out of 5 stars4/5 (811)
- Why Fish Don't Exist: A Story of Loss, Love, and the Hidden Order of LifeFrom EverandWhy Fish Don't Exist: A Story of Loss, Love, and the Hidden Order of LifeRating: 4.5 out of 5 stars4.5/5 (699)
- Come Back, Como: Winning the Heart of a Reluctant DogFrom EverandCome Back, Como: Winning the Heart of a Reluctant DogRating: 3.5 out of 5 stars3.5/5 (10)
- The Lives of Bees: The Untold Story of the Honey Bee in the WildFrom EverandThe Lives of Bees: The Untold Story of the Honey Bee in the WildRating: 4.5 out of 5 stars4.5/5 (44)
- The Revolutionary Genius of Plants: A New Understanding of Plant Intelligence and BehaviorFrom EverandThe Revolutionary Genius of Plants: A New Understanding of Plant Intelligence and BehaviorRating: 4.5 out of 5 stars4.5/5 (137)
- When You Find Out the World Is Against You: And Other Funny Memories About Awful MomentsFrom EverandWhen You Find Out the World Is Against You: And Other Funny Memories About Awful MomentsRating: 3.5 out of 5 stars3.5/5 (13)
- Spoiled Rotten America: Outrages of Everyday LifeFrom EverandSpoiled Rotten America: Outrages of Everyday LifeRating: 3 out of 5 stars3/5 (19)
- The Hidden Life of Trees: What They Feel, How They CommunicateFrom EverandThe Hidden Life of Trees: What They Feel, How They CommunicateRating: 4 out of 5 stars4/5 (1002)
- The Secret Life of Lobsters: How Fishermen and Scientists Are Unraveling the Mysteries of Our Favorite CrustaceanFrom EverandThe Secret Life of Lobsters: How Fishermen and Scientists Are Unraveling the Mysteries of Our Favorite CrustaceanNo ratings yet
- Gathering Moss: A Natural and Cultural History of MossesFrom EverandGathering Moss: A Natural and Cultural History of MossesRating: 4.5 out of 5 stars4.5/5 (349)