You might also like
- BIO307 Lecture (Protein Structure and Function)Document18 pagesBIO307 Lecture (Protein Structure and Function)Kerstin MarobelaNo ratings yet
- San Gabriel 198 - REPLANTEO PLANTA BAJA RAMPADocument1 pageSan Gabriel 198 - REPLANTEO PLANTA BAJA RAMPAAylen GimenezNo ratings yet
- Perbesaran Model Bor Ni Rahadewi Netta M / 20: OB OB OBDocument1 pagePerbesaran Model Bor Ni Rahadewi Netta M / 20: OB OB OBrahadewiNo ratings yet
- ArchitecturalDocument7 pagesArchitecturaluapsaua.rubiteNo ratings yet
- Floor Layout: Studio-Type UnitDocument1 pageFloor Layout: Studio-Type UnitJohari YanevaNo ratings yet
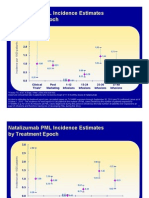
- Historical PML by Treatment Epoch October 2010Document12 pagesHistorical PML by Treatment Epoch October 2010MSDocumentsNo ratings yet
- Gráficas Del Sistema Pentano HeptanoDocument2 pagesGráficas Del Sistema Pentano HeptanoDiego InfanteNo ratings yet
- SINOPSIS DikonversiDocument1 pageSINOPSIS DikonversiDella TaselkaNo ratings yet
- Kitchen Det. 2 BTDocument1 pageKitchen Det. 2 BTELY JONES DEPINONo ratings yet
- Boyle's LawDocument6 pagesBoyle's LawDastm BgraNo ratings yet
- Planta Primer Piso Dibujo BasicoDocument1 pagePlanta Primer Piso Dibujo BasicoYair CbNo ratings yet
- Projecto Belo 3Document1 pageProjecto Belo 3Sabino UloNo ratings yet
- Bed Rm. 3.88X4.36Document1 pageBed Rm. 3.88X4.36Zulkarnain RezaNo ratings yet
- App E.1.4 - UC Plot (Cellar Deck) 1yr NDLLDocument1 pageApp E.1.4 - UC Plot (Cellar Deck) 1yr NDLLadlanamran2No ratings yet
- Floor PlansDocument1 pageFloor PlansGervie Cabang PalattaoNo ratings yet
- 3 Tecnicas AcotadaDocument1 page3 Tecnicas AcotadaDanny MaczNo ratings yet
- Electric eDocument1 pageElectric eahmed lionNo ratings yet
- 001 Planos Iglesia Juan Pablo II - 11Document1 page001 Planos Iglesia Juan Pablo II - 11Paola Perez SantanaNo ratings yet
- App E.1.2 - UC Plot (Mezzanine Deck) 1yr NDLLDocument1 pageApp E.1.2 - UC Plot (Mezzanine Deck) 1yr NDLLadlanamran2No ratings yet
- Lay Out LuminariasDocument1 pageLay Out LuminariasNemias RégisNo ratings yet
- L4 GrafikDocument2 pagesL4 GrafikTiara Putri ValentinaNo ratings yet
- Layout Visi Misi LorongDocument1 pageLayout Visi Misi Lorongketok mejikNo ratings yet
- Untuk Tukang 3Document1 pageUntuk Tukang 3YantNo ratings yet
- Kandang MobilDocument1 pageKandang MobilBegu SagunNo ratings yet
- Konsetrasi Asam Asetat Yang Terdistribusi (N)Document6 pagesKonsetrasi Asam Asetat Yang Terdistribusi (N)nurizaNo ratings yet
- Sistema de Microriego Baibua (Muyupampa)Document1 pageSistema de Microriego Baibua (Muyupampa)Juan Carlos Soliz QNo ratings yet
- VN049 - ID Junction Long Thanh - Sale Gallery - HO SO KIEN TRUC TONG MAT BANG 1-500Document1 pageVN049 - ID Junction Long Thanh - Sale Gallery - HO SO KIEN TRUC TONG MAT BANG 1-500nguyenleyenoanh95No ratings yet
- Lavandería: Primer NivelDocument1 pageLavandería: Primer NivelYn IngaNo ratings yet
- Unidades Sanitarias La Aurora 2Document1 pageUnidades Sanitarias La Aurora 2Carlos RamírezNo ratings yet
- Pre Parcail SuelosDocument5 pagesPre Parcail SuelosLaura Alvarez GarcíaNo ratings yet
- Pre Parcail SuelosDocument5 pagesPre Parcail SuelosLaura Alvarez GarcíaNo ratings yet
- Pre Parcail SuelosDocument5 pagesPre Parcail SuelosLaura Alvarez GarcíaNo ratings yet
- Hasil GC-Ms Tongkol Jagung 96%2Document13 pagesHasil GC-Ms Tongkol Jagung 96%2Abdi KaryaNo ratings yet
- Plano 3 y TechoDocument1 pagePlano 3 y TechoNayeli ninoska Quica RuizNo ratings yet
- Heladería-Pastelería MagisterioDocument1 pageHeladería-Pastelería MagisterioDaniel MalpartidaNo ratings yet
- Dimension Plan House Plan: Entrada 1.79X1.59 Cocina 3.16X1.96 Lavadero 2.60X1.96Document1 pageDimension Plan House Plan: Entrada 1.79X1.59 Cocina 3.16X1.96 Lavadero 2.60X1.96komal akhtarNo ratings yet
- DIRECCIÓNDocument1 pageDIRECCIÓNKevin Soncco GamarraNo ratings yet
- Captura de Pantalla 2022-10-17 A La(s) 11.31.03Document10 pagesCaptura de Pantalla 2022-10-17 A La(s) 11.31.03Jorge AVNo ratings yet
- Plano Escalas Acceso Casa 2Document1 pagePlano Escalas Acceso Casa 2David Higuita RamirezNo ratings yet
- MustafaDocument1 pageMustafaforyouuonly1234No ratings yet
- Update LoxonDocument112 pagesUpdate LoxonwojiaojericNo ratings yet
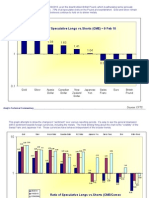
- Commitment of Traders and British Pound Thoughts On 13feb10Document5 pagesCommitment of Traders and British Pound Thoughts On 13feb10AndysTechnicalsNo ratings yet
- F L O O R PL A N: Smoking AreaDocument1 pageF L O O R PL A N: Smoking Arealeonel manalangNo ratings yet
- Viga Metalica 1 (Sum)Document1 pageViga Metalica 1 (Sum)Ezequiel GiorelloNo ratings yet
- 4 Tecnicas AcotadaDocument1 page4 Tecnicas AcotadaDanny MaczNo ratings yet
- Cerco PropuestoDocument1 pageCerco PropuestoMarcos Ramirez CruzNo ratings yet
- Planimetria ConstruccionDocument9 pagesPlanimetria ConstruccionDaniela AlexiaNo ratings yet
- Iso1 PDFDocument1 pageIso1 PDFjeniffer mosqueraNo ratings yet
- Answer AssignmentDocument6 pagesAnswer AssignmentMuhammad HazraienNo ratings yet
- Practico 4, Del 9 Creo Al 13Document7 pagesPractico 4, Del 9 Creo Al 13Cristian Rosas SotoNo ratings yet
- Pila La-01Document1 pagePila La-01Oskar CorderoNo ratings yet
- WilliamT - CabeceraDocument1 pageWilliamT - CabeceraWilliam TibaquiráNo ratings yet
- Plan View: Construction of Single Barrel RCBC (3M X 3M)Document1 pagePlan View: Construction of Single Barrel RCBC (3M X 3M)Herbee ZevlagNo ratings yet
- Sample 1 2 3 4 5: X Bar ChartDocument3 pagesSample 1 2 3 4 5: X Bar Chartimikimi89No ratings yet
- App E.1.3 - UC Plot (Main Deck) 1yr NDLLDocument1 pageApp E.1.3 - UC Plot (Main Deck) 1yr NDLLadlanamran2No ratings yet
- Basement Plan: Proposed Two (2) - Storey Commercial Building With RoofdeckDocument1 pageBasement Plan: Proposed Two (2) - Storey Commercial Building With Roofdeckdante mortelNo ratings yet
- Peroxidase Activity Varies With TimeDocument4 pagesPeroxidase Activity Varies With TimeWatcharapongWongkaewNo ratings yet
- Belcorp Tocancipá - Colombia Printed: 2/11/2018 - 8:10:19 A. M. Measured On: Spectro-Guide Sphere CRIISS File Name: Contingencia Celso - WSVDocument3 pagesBelcorp Tocancipá - Colombia Printed: 2/11/2018 - 8:10:19 A. M. Measured On: Spectro-Guide Sphere CRIISS File Name: Contingencia Celso - WSVLuis Felipe BenavidesNo ratings yet
- Applied Time Series Econometrics: A Practical Guide for Macroeconomic Researchers with a Focus on AfricaFrom EverandApplied Time Series Econometrics: A Practical Guide for Macroeconomic Researchers with a Focus on AfricaRating: 3 out of 5 stars3/5 (1)
- Custom Taqman SNP Genotyping Assays Simplify Your Genomic ProjectsDocument4 pagesCustom Taqman SNP Genotyping Assays Simplify Your Genomic ProjectsRogerio Merces Ferreira SantosNo ratings yet
- (Current Topics in Membranes 72) Vann Bennett (Eds.) - Functional Organization of Vertebrate Plasma Membrane-Academic Press (2013) PDFDocument364 pages(Current Topics in Membranes 72) Vann Bennett (Eds.) - Functional Organization of Vertebrate Plasma Membrane-Academic Press (2013) PDFSankarshan talluriNo ratings yet
- Tura KuDocument104 pagesTura KuFitzgerald BillyNo ratings yet
- Cam PathwayDocument7 pagesCam PathwayMelanie CabforoNo ratings yet
- Regulacion TranscripcionalDocument27 pagesRegulacion TranscripcionalPaulina CisnerosNo ratings yet
- Patofisiologi PsoriasisDocument9 pagesPatofisiologi PsoriasisBilly Y. SinoelinggaNo ratings yet
- Hep ABC - Lab DiagnosisDocument15 pagesHep ABC - Lab DiagnosisjunaidiabdhalimNo ratings yet
- Virulence Factors MycoplasmDocument9 pagesVirulence Factors MycoplasmAlan GarcíaNo ratings yet
- Code No: 45056Document4 pagesCode No: 45056SRINIVASA RAO GANTANo ratings yet
- Anatomy and Physiology Chapter 7 The Muscular SystemDocument13 pagesAnatomy and Physiology Chapter 7 The Muscular System俺気健人No ratings yet
- Gene TherapyDocument85 pagesGene TherapyVIDYANo ratings yet
- Samer Hawash 27s ResumeDocument2 pagesSamer Hawash 27s Resumeapi-438554282No ratings yet
- Activity 3.1 The Endomembrane SystemDocument4 pagesActivity 3.1 The Endomembrane SystemVelasco, Josiah M.No ratings yet
- SSC 10th Class Science Text Book Part 2Document121 pagesSSC 10th Class Science Text Book Part 2SakinaNo ratings yet
- Development of DNA Barcode For Magnoliopsida and LDocument9 pagesDevelopment of DNA Barcode For Magnoliopsida and LarisNo ratings yet
- Department of Molecular Biology. Covid 19 RTPCR With Home Collection Test Name Result Unit Bio. Ref. Range MethodDocument2 pagesDepartment of Molecular Biology. Covid 19 RTPCR With Home Collection Test Name Result Unit Bio. Ref. Range MethodAshwini PrinceNo ratings yet
- Human Biology: Unit PaperDocument24 pagesHuman Biology: Unit Paperadel hanyNo ratings yet
- Paper For 01 11 09 Safe Hands Target GD andDocument1 pagePaper For 01 11 09 Safe Hands Target GD andnitinNo ratings yet
- Q4 Week 2 Gen BioDocument2 pagesQ4 Week 2 Gen BioMarga TeumeNo ratings yet
- Carbohydrates, Lipid and Protein Metabolism: Guyton and Hall Textbook of Medical Physiology (14th Ed.), Chapters 68-70Document107 pagesCarbohydrates, Lipid and Protein Metabolism: Guyton and Hall Textbook of Medical Physiology (14th Ed.), Chapters 68-70Prixie AntonioNo ratings yet
- Taksonomi NanasDocument20 pagesTaksonomi Nanas180 RuthAnastasyaNo ratings yet
- Biomolecules _ Short Notes __ Lakshya JEE 2024Document2 pagesBiomolecules _ Short Notes __ Lakshya JEE 2024librarybooks.tashiNo ratings yet
- Major and Subcellular Organelles of CellsDocument29 pagesMajor and Subcellular Organelles of CellsrookitszNo ratings yet
- NCMA 215 PrelimsDocument30 pagesNCMA 215 PrelimsClaudine Jo B. TalabocNo ratings yet
- I. Specific Catabolic PathwaysDocument17 pagesI. Specific Catabolic PathwaysMary Rose Bobis VicenteNo ratings yet
- Zoo Lab ActivityDocument1 pageZoo Lab ActivityHarold DavidNo ratings yet
- The Human GenomeDocument10 pagesThe Human Genomeaimee WeebNo ratings yet
- A Draf Map of The Human ProteomeDocument15 pagesA Draf Map of The Human ProteomeDarkill JackNo ratings yet
- BiopharmingDocument2 pagesBiopharmingRonaldo ChachaNo ratings yet
- Reproduction of Prokaryotic CellDocument29 pagesReproduction of Prokaryotic CellNurrazanahKarmanNo ratings yet