You might also like
- FIDP Oral Com 1Document5 pagesFIDP Oral Com 1Jomark RebolledoNo ratings yet
- Music Genre Classification Using Machine Learning Techniques: April 2018Document13 pagesMusic Genre Classification Using Machine Learning Techniques: April 2018Sahil BansalNo ratings yet
- Teaching Language in Context. Chapter 1 SummaryDocument6 pagesTeaching Language in Context. Chapter 1 SummarySC Zoe100% (6)
- Curriculum Map in English 8Document13 pagesCurriculum Map in English 8Jennelyn TadleNo ratings yet
- Poster Ecoc Rimini 030921Document1 pagePoster Ecoc Rimini 030921Jaya Kumar KbNo ratings yet
- Time-Frequency Audio Features For Speech-Music ClassificationDocument5 pagesTime-Frequency Audio Features For Speech-Music ClassificationShrouk AbdallahNo ratings yet
- English GR 456 1st Quarter MG Bow 1Document24 pagesEnglish GR 456 1st Quarter MG Bow 1api-359551623100% (1)
- MALAPATAN-1 - English-Assessment-Report - LEAST LEARNED AND MASTERED COMPETENCIESDocument7 pagesMALAPATAN-1 - English-Assessment-Report - LEAST LEARNED AND MASTERED COMPETENCIESJivielyn VargasNo ratings yet
- Spectral and Textural Features For AutomaticDocument4 pagesSpectral and Textural Features For AutomaticAicha ZitouniNo ratings yet
- Natus Bio Logic Navigator Pro Master IIDocument2 pagesNatus Bio Logic Navigator Pro Master IIferranNo ratings yet
- Poster Design With Emi in Mind 1691391858356Document1 pagePoster Design With Emi in Mind 1691391858356luidgi12345No ratings yet
- Paombong High School, Inc. S.Y. 2017-2018 Curriculum Map English 8Document18 pagesPaombong High School, Inc. S.Y. 2017-2018 Curriculum Map English 8Jzaninna SolNo ratings yet
- JDSU Fibercharacterization Poster October2005Document1 pageJDSU Fibercharacterization Poster October2005Gaurav SainiNo ratings yet
- Vol7no3 331-336 PDFDocument6 pagesVol7no3 331-336 PDFNghị Hoàng MaiNo ratings yet
- Group 10 - Curriculum MapDocument2 pagesGroup 10 - Curriculum MapAni Pearl PanganibanNo ratings yet
- LCD in English Q1 To Q4Document124 pagesLCD in English Q1 To Q4Crail ManikaNo ratings yet
- Foreign Accent Conversion Through Voice MorphingDocument6 pagesForeign Accent Conversion Through Voice Morphingrachitapatel449No ratings yet
- Phonological Processes in Connected Speech: FormativeDocument4 pagesPhonological Processes in Connected Speech: FormativebetancourtandgaliffaNo ratings yet
- Histogram of Gradients of Time-Frequency Representations For Audio Scene DetectionDocument15 pagesHistogram of Gradients of Time-Frequency Representations For Audio Scene DetectionMuhammet Ali KökerNo ratings yet
- Unpacking Grade 7 1st QuarterDocument9 pagesUnpacking Grade 7 1st QuarterGideon Pol TiongcoNo ratings yet
- 1st Sem Fidp Oral CommDocument5 pages1st Sem Fidp Oral CommMarielle AlystraNo ratings yet
- 1 Quarter: - News Reports - Speeches - Informative Talks - Panel DiscussionsDocument2 pages1 Quarter: - News Reports - Speeches - Informative Talks - Panel DiscussionsCarrie Alyss P Eder-Ibacarra100% (2)
- RF PropogationDocument3 pagesRF PropogationShubham RastogiNo ratings yet
- Anumanchipalli2019 - Speech Synthesis From Neural Decoding of Spoken SentencesDocument20 pagesAnumanchipalli2019 - Speech Synthesis From Neural Decoding of Spoken SentencesErick SolisNo ratings yet
- Unsupervised Speech Representation Learning Using Wavenet AutoencodersDocument13 pagesUnsupervised Speech Representation Learning Using Wavenet AutoencodersYoann DragneelNo ratings yet
- Visualization of Perceptual Qualities in Textural SoundsDocument8 pagesVisualization of Perceptual Qualities in Textural SoundsgrxxxNo ratings yet
- Fidp Oral ComDocument10 pagesFidp Oral ComClarissa SanchezNo ratings yet
- 2 AES ImmersiveDocument5 pages2 AES ImmersiveDavid BonillaNo ratings yet
- A Study On Automatic Speech RecognitionDocument2 pagesA Study On Automatic Speech RecognitionInternational Journal of Innovative Science and Research Technology100% (1)
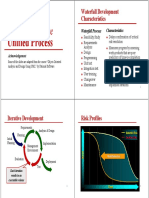
- Unified Process: Introduction To TheDocument8 pagesUnified Process: Introduction To TheSevNo ratings yet
- WorkflowGraphic Final v01Document1 pageWorkflowGraphic Final v01jfNo ratings yet
- Curriculum Map 7 2019 2020Document9 pagesCurriculum Map 7 2019 2020Junna Gariando BalolotNo ratings yet
- Radiographic Assessment of Pediatric Foot Alignment: Review: ObjectiveDocument8 pagesRadiographic Assessment of Pediatric Foot Alignment: Review: ObjectiveEGNo ratings yet
- VisingerDocument5 pagesVisingerkyeonjNo ratings yet
- Earth Sci Fidp (g11)Document8 pagesEarth Sci Fidp (g11)arvie lucesNo ratings yet
- 5 Avenue, Ledesco Village, La Paz, Iloilo City, Philippines Tel. #: (033) 320-4854 School ID: 404172 Email AddDocument8 pages5 Avenue, Ledesco Village, La Paz, Iloilo City, Philippines Tel. #: (033) 320-4854 School ID: 404172 Email AddMelerose Dela SernaNo ratings yet
- Effective Treatment For ChildhoodDocument28 pagesEffective Treatment For ChildhoodRafael AlvesNo ratings yet
- International Journal of Current Advanced Research: A Survey On Automatic Speech Recognition System Research ArticleDocument11 pagesInternational Journal of Current Advanced Research: A Survey On Automatic Speech Recognition System Research ArticleSana IsamNo ratings yet
- Automatic Detection of Vocal Segments in Popular Songs.: January 2004Document9 pagesAutomatic Detection of Vocal Segments in Popular Songs.: January 2004LomarenceNo ratings yet
- Paper 5Document4 pagesPaper 5s.dedaloscribdNo ratings yet
- DLL Grade 7 Week 1Document6 pagesDLL Grade 7 Week 1Almar MiraNo ratings yet
- FBA DiagramDocument2 pagesFBA Diagramana sandra popNo ratings yet
- Quarter 1 Week 3: PRIMALS (English Class, Group 1 - The Linguists)Document4 pagesQuarter 1 Week 3: PRIMALS (English Class, Group 1 - The Linguists)ANNA MARIE LARGADAS MALULANNo ratings yet
- Part One The Nature of Approaches and MethodsDocument1 pagePart One The Nature of Approaches and Methodsbertaniamine7No ratings yet
- A Sub-Character Architecture For Korean Language ProcessingDocument6 pagesA Sub-Character Architecture For Korean Language ProcessingNicolly PradoNo ratings yet
- Overall SyllabusDocument525 pagesOverall SyllabusDIVYANSH GAUR (RA2011027010090)No ratings yet
- Fully Convolutional Networks For Semantic Segmentation: Jonathan Long Evan Shelhamer Trevor Darrell UC BerkeleyDocument10 pagesFully Convolutional Networks For Semantic Segmentation: Jonathan Long Evan Shelhamer Trevor Darrell UC BerkeleyUnaixa KhanNo ratings yet
- Curriculum Map English 8Document26 pagesCurriculum Map English 8Tipa JacoNo ratings yet
- Review of The Emotional Feature Extraction and Classification Using EEG SignalsDocument12 pagesReview of The Emotional Feature Extraction and Classification Using EEG Signalsforooz davoodzadehNo ratings yet
- Sat GuideDocument56 pagesSat Guidemuhayyoeshonqulova0No ratings yet
- Speaker Recognition Based On Deep Learning: An OverviewDocument39 pagesSpeaker Recognition Based On Deep Learning: An OverviewfranciscoNo ratings yet
- Shirani MehrH PDFDocument8 pagesShirani MehrH PDFchirag801No ratings yet
- DLL ENG8 3RDQ Week1Document7 pagesDLL ENG8 3RDQ Week1Donna Mae MonteroNo ratings yet
- 5831 978-1-5386-4658-8/18/$31.00 ©2019 Ieee Icassp 2019Document5 pages5831 978-1-5386-4658-8/18/$31.00 ©2019 Ieee Icassp 2019ABDUL KHADER U ANo ratings yet
- English 7 Curriculum Map: 443 Mabini Street Atimonan, Quezon (Recognized by The Government) No. 010 S. 1986Document6 pagesEnglish 7 Curriculum Map: 443 Mabini Street Atimonan, Quezon (Recognized by The Government) No. 010 S. 1986ZarahJoyceSegoviaNo ratings yet
- Headphone Technology Hear-Through, Bone Conduction, Noise CancelingDocument6 pagesHeadphone Technology Hear-Through, Bone Conduction, Noise CancelingRichard HallumNo ratings yet
- Curriculum Map 1-4Document29 pagesCurriculum Map 1-4DoreenSevillesNo ratings yet
- Beyond Minimum: Speech Showing Prosodic Asking Ideas ComingDocument8 pagesBeyond Minimum: Speech Showing Prosodic Asking Ideas ComingGeraldNo ratings yet
- Deep Learning For Audio Signal ProcessingDocument14 pagesDeep Learning For Audio Signal Processingsantoshmore439No ratings yet