You might also like
- Open System (1) ThermodynamicDocument38 pagesOpen System (1) ThermodynamicSakinah KamalNo ratings yet
- Completed Idp Report PDFDocument117 pagesCompleted Idp Report PDFFarhana Hussin100% (1)
- Acoustic Speech Production BasicsDocument57 pagesAcoustic Speech Production BasicsMiza MariyamNo ratings yet
- An Introduction To Extended Vocal TechniquesDocument21 pagesAn Introduction To Extended Vocal TechniquesblopascNo ratings yet
- Ertesvag - Turbulent Flow and CombustionDocument298 pagesErtesvag - Turbulent Flow and CombustionNgew HongNo ratings yet
- Albert, David - Quantum Mechanics and ExperienceDocument108 pagesAlbert, David - Quantum Mechanics and Experiencekarenhunt9583% (6)
- Torsional Waves in A Bowed StringDocument14 pagesTorsional Waves in A Bowed StringpsykosomatikNo ratings yet
- Periodic and Aperiodic SoundsDocument2 pagesPeriodic and Aperiodic SoundsTiresia GiunoNo ratings yet
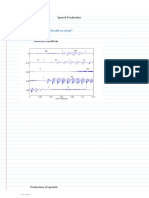
- 3.4 The Source-Filter Model of Speech Production: Figure 2.31: Saggital Cross Section of The Vocal TractDocument4 pages3.4 The Source-Filter Model of Speech Production: Figure 2.31: Saggital Cross Section of The Vocal TractMirjana NenadovicNo ratings yet
- Types of Waveform.Document5 pagesTypes of Waveform.Onoriode PraiseNo ratings yet
- Acoustic and Articulatory Units of Speech SoundsDocument11 pagesAcoustic and Articulatory Units of Speech SoundsLucifer LightburnNo ratings yet
- General NotesDocument19 pagesGeneral NotesAhmedBIowarNo ratings yet
- English Phonetics and Phonology 6Document20 pagesEnglish Phonetics and Phonology 6Mohd Zulkhairi AbdullahNo ratings yet
- Phonetics Source-Filter Theory HandoutDocument4 pagesPhonetics Source-Filter Theory HandoutTaha AhsanNo ratings yet
- Unit 2Document23 pagesUnit 2ASRNo ratings yet
- Definition of Terms Sound TheoryDocument28 pagesDefinition of Terms Sound TheoryAnonymous 5kOS4tNo ratings yet
- SOUND Verka (B) AmritsarDocument19 pagesSOUND Verka (B) Amritsarapi-3731257No ratings yet
- TerminologyDocument2 pagesTerminologyGiovanna Simões MaropoNo ratings yet
- YodelingDocument9 pagesYodelingAlexander Chen100% (2)
- Chapter 2: Articulatory, Auditory and Acoustic Phonetics. PhonologyDocument5 pagesChapter 2: Articulatory, Auditory and Acoustic Phonetics. PhonologycalluraNo ratings yet
- Brass Instrument Acoustics - An IntroductionDocument22 pagesBrass Instrument Acoustics - An IntroductionBrandon Mcguire100% (1)
- Sundberg SingingVoice ScientificAmerican 1977Document10 pagesSundberg SingingVoice ScientificAmerican 1977Elia Koussa100% (2)
- SINOHIN JOSHUA PHYSICS02 Midterm HW01Document6 pagesSINOHIN JOSHUA PHYSICS02 Midterm HW01morikun2003No ratings yet
- 01 The Basics of SoundDocument2 pages01 The Basics of SoundFrançois HarewoodNo ratings yet
- The Four Processes of SpeechDocument2 pagesThe Four Processes of SpeechKeiKoNo ratings yet
- Notes WK 1 1Document12 pagesNotes WK 1 1HarshalNo ratings yet
- Acoustic Phonetics 1Document6 pagesAcoustic Phonetics 1ummeammara866No ratings yet
- Physics of Sound: Traveling WavesDocument3 pagesPhysics of Sound: Traveling WavesReksa Indika SuryaNo ratings yet
- UNc2rjc ncr2ocmxedIT 2Document3 pagesUNc2rjc ncr2ocmxedIT 2chemaNo ratings yet
- Acoustic For Music TheoryDocument6 pagesAcoustic For Music TheoryAriputhiran NarayananNo ratings yet
- Phonolog Y: The Study of Sound Structure in LanguageDocument21 pagesPhonolog Y: The Study of Sound Structure in LanguageTiramisu YummyNo ratings yet
- Fonetyka 18.12Document7 pagesFonetyka 18.12Karolina KNo ratings yet
- Measuring and Modeling Speech ProductionDocument3 pagesMeasuring and Modeling Speech ProductionNurhazreen KadirNo ratings yet
- Choir AcousticsDocument17 pagesChoir Acousticssuoiviet100% (1)
- Quarterly Progress and Status Report: Dept. For Speech, Music and HearingDocument26 pagesQuarterly Progress and Status Report: Dept. For Speech, Music and HearingTheresa HagenNo ratings yet
- Physiology of Auditory SystemDocument32 pagesPhysiology of Auditory SystemDr. T. Balasubramanian75% (4)
- Acoustics of The Vocal TractDocument14 pagesAcoustics of The Vocal TractGiovanna Simões MaropoNo ratings yet
- Physics 1010 ProjectDocument16 pagesPhysics 1010 Projectapi-265745081No ratings yet
- Understanding Airstream MechanismsDocument5 pagesUnderstanding Airstream MechanismsZena SattarNo ratings yet
- Acoustics PresentationDocument33 pagesAcoustics PresentationYourBestFriemdNo ratings yet
- How Digital Audio WorksDocument11 pagesHow Digital Audio WorksPhan Giang ChâuNo ratings yet
- Techniques de La Prise de Son Et Du Mixage I - Chapitre-1Document4 pagesTechniques de La Prise de Son Et Du Mixage I - Chapitre-1Samah KanaanNo ratings yet
- The Creation of Musical ScalesDocument38 pagesThe Creation of Musical ScalesMatheus ModestiNo ratings yet
- 3 Levels of Intensity ControlDocument1 page3 Levels of Intensity ControlHari PrasadNo ratings yet
- Himonides2009Mapping25Document27 pagesHimonides2009Mapping25haloninenineNo ratings yet
- Introduction to the study of acousticsDocument9 pagesIntroduction to the study of acousticsPrakruthi PrashanthNo ratings yet
- Notes PedagogyDocument8 pagesNotes PedagogyEsteban José Zúñiga CalderónNo ratings yet
- Acoustics From Oxford Companion PDFDocument17 pagesAcoustics From Oxford Companion PDFMegan Griffith100% (1)
- Sound: Norazura BT Mizal AzzmiDocument58 pagesSound: Norazura BT Mizal AzzmiWan Mohd SayutiNo ratings yet
- Perception of Sound: Longitudinal and Transverse WavesDocument16 pagesPerception of Sound: Longitudinal and Transverse WavesSasanka Sekhar Pani100% (1)
- Physics of MusicDocument19 pagesPhysics of MusicSiddharta HoangNo ratings yet
- Sound Waves - An EssayDocument8 pagesSound Waves - An EssayAshley RoyNo ratings yet
- Physics PPT SoundDocument20 pagesPhysics PPT SoundJoshua Chacko PonnachanNo ratings yet
- Acoustic PhoneticsDocument30 pagesAcoustic PhoneticsAzzad UddinNo ratings yet
- Acoustics of The Singing VoiceDocument13 pagesAcoustics of The Singing VoiceDuany Et DaniloNo ratings yet
- PsychoPhisics, ExperimentsDocument9 pagesPsychoPhisics, ExperimentsMaria Isabel BinimelisNo ratings yet
- 04.3 UNIT - 4 Surface Mining Env - IDocument117 pages04.3 UNIT - 4 Surface Mining Env - Inumendrakumarpandey2003No ratings yet
- Sonorant by Anmar Ahmed English Sonorant ChartDocument9 pagesSonorant by Anmar Ahmed English Sonorant Chartanmar ahmedNo ratings yet
- Fundamentals of Architectural AcousticsDocument49 pagesFundamentals of Architectural AcousticsRukminiPriyanka33% (3)
- Sound Perception Topic: 92-96 Perceiving SoundDocument18 pagesSound Perception Topic: 92-96 Perceiving SoundMariabutt ButtNo ratings yet
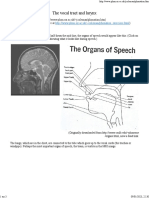
- The Vocal Tract and Larynx ExplainedDocument3 pagesThe Vocal Tract and Larynx ExplainedDjalal MoumenNo ratings yet
- Basics of Sound Waves ExplainedDocument12 pagesBasics of Sound Waves ExplainedL.F.No ratings yet
- EP - 1.gussenhoven (2004) Introduction To Pitch-FusionadoDocument11 pagesEP - 1.gussenhoven (2004) Introduction To Pitch-FusionadoPepe KuyoteNo ratings yet
- ENEC Serie 221 RichtigDocument45 pagesENEC Serie 221 RichtigAli KayaNo ratings yet
- David Reitz - Simulation - Forces and Motion - PhetDocument3 pagesDavid Reitz - Simulation - Forces and Motion - Phetapi-545302422No ratings yet
- Lesson Plan 10 CPDocument5 pagesLesson Plan 10 CPapi-582839918No ratings yet
- HW2 ADocument2 pagesHW2 Ajambu99No ratings yet
- Mark I. Stockman, Professor of Physics, PHD, Dsc. Gsu Center For Nano-Optics (Ceno), DirectorDocument43 pagesMark I. Stockman, Professor of Physics, PHD, Dsc. Gsu Center For Nano-Optics (Ceno), Directordoroty3048No ratings yet
- Class XII-linear ProgrammingDocument6 pagesClass XII-linear ProgrammingSWETHA VNNo ratings yet
- The Basic Theory of Crowning Industrial RollersDocument8 pagesThe Basic Theory of Crowning Industrial RollersJuan Carlos CárdenasNo ratings yet
- Chp01 - Capacitors (Notes)Document6 pagesChp01 - Capacitors (Notes)sherry mughalNo ratings yet
- What Is Image Processing?Document5 pagesWhat Is Image Processing?JggNo ratings yet
- Midterm Answer Bio MechanicsDocument11 pagesMidterm Answer Bio MechanicsUmmu HauraNo ratings yet
- CE 309 06 Relative Equilibrium of LiquidsDocument14 pagesCE 309 06 Relative Equilibrium of LiquidsKarl TristanNo ratings yet
- SOLUTION OF Lens, Mirror, RefractionDocument4 pagesSOLUTION OF Lens, Mirror, RefractionRumpa DasNo ratings yet
- Coriolis Mass Flow Meter With Uncompromising Performance: Features ApplicationsDocument6 pagesCoriolis Mass Flow Meter With Uncompromising Performance: Features ApplicationsJhon SierraNo ratings yet
- Capacity, PR and RR Test Procedure v2.0Document8 pagesCapacity, PR and RR Test Procedure v2.0Mun Haeng PhonNo ratings yet
- ResEng2 Exam-2018Document4 pagesResEng2 Exam-2018Nijat AhmadovNo ratings yet
- Plate 4 Effective Stresses in SoilDocument14 pagesPlate 4 Effective Stresses in SoilSofia Isabelle GarciaNo ratings yet
- Thermal Properties of Matter - 3Document16 pagesThermal Properties of Matter - 3Nik AshrafNo ratings yet
- Beat Phenomenon - Vibration - Sys. Analys.Document5 pagesBeat Phenomenon - Vibration - Sys. Analys.Miguel CervantesNo ratings yet
- Aerodynamics Coarse OutlineDocument3 pagesAerodynamics Coarse OutlineBasil DubeNo ratings yet
- Notes Sqqs1043 Chapter 3 - StudentDocument54 pagesNotes Sqqs1043 Chapter 3 - StudentMaya MaisarahNo ratings yet
- Test Based On Electric DipoleDocument5 pagesTest Based On Electric DipoleKunal MukherjeeNo ratings yet
- Chapter 3 PDFDocument19 pagesChapter 3 PDFMUHAMMAD LUKMAN ARSHADNo ratings yet
- Analysis & Design of Multistorey BuildingDocument124 pagesAnalysis & Design of Multistorey Buildingriyasproject86% (36)
- Combined Model of LFC and Voltage Control in Matla SoftwareDocument12 pagesCombined Model of LFC and Voltage Control in Matla SoftwareMahmudul BappiNo ratings yet
- Soal B InggrisDocument6 pagesSoal B Inggrishari fajarNo ratings yet
- MT R 108 000 0 000000-0 DHHS B eDocument68 pagesMT R 108 000 0 000000-0 DHHS B eRafal WojciechowskiNo ratings yet