You might also like
- More Details On Data ModelsDocument23 pagesMore Details On Data ModelschitraalavaniNo ratings yet
- No SQLDocument36 pagesNo SQLHELLO WorldNo ratings yet
- Unit IDocument28 pagesUnit Iprashanth kumarNo ratings yet
- Nosql What Does It MeanDocument8 pagesNosql What Does It MeannadeemNo ratings yet
- RDBMSvs DBMSDocument9 pagesRDBMSvs DBMSRishitaNo ratings yet
- Nosql What Does It MeanDocument15 pagesNosql What Does It MeannadeemNo ratings yet
- BDA UT2 QB AnswersDocument22 pagesBDA UT2 QB Answerswih ijNo ratings yet
- AscolParajuli IndividualProjectDocument42 pagesAscolParajuli IndividualProjectAman Kumar DevNo ratings yet
- Theory dbs1Document18 pagesTheory dbs1Haadi KhanNo ratings yet
- AshiDocument31 pagesAshiNahadafathima FathimaNo ratings yet
- Introduction To NoSQLDocument16 pagesIntroduction To NoSQLAkshay BaraiyaNo ratings yet
- Object-Oriented Database: Adoption of Object DatabasesDocument5 pagesObject-Oriented Database: Adoption of Object DatabasesvedmcaNo ratings yet
- SQL CODING FOR BEGINNERS: Step-by-Step Beginner's Guide to Mastering SQL Programming and Coding (2022 Crash Course for Newbies)From EverandSQL CODING FOR BEGINNERS: Step-by-Step Beginner's Guide to Mastering SQL Programming and Coding (2022 Crash Course for Newbies)No ratings yet
- Im Unit 3 DBMS UpdatedDocument93 pagesIm Unit 3 DBMS UpdatedJustin RahulNo ratings yet
- Ass. 1 - Quijano, Jan Cleo C.Document3 pagesAss. 1 - Quijano, Jan Cleo C.Jan Cleo Cerdiña QuijanoNo ratings yet
- Databasemanagementsystem-190120173107 DdsfsDocument50 pagesDatabasemanagementsystem-190120173107 DdsfsRaj KundraNo ratings yet
- Database SystemsDocument86 pagesDatabase SystemsHaider SultanNo ratings yet
- Nosqlmodule 1Document102 pagesNosqlmodule 1Amina SultanaNo ratings yet
- NoSQL Databases NotesDocument5 pagesNoSQL Databases NotesAkansha UniyalNo ratings yet
- University Institute of Computing: Master of Computer Applications (MCA)Document10 pagesUniversity Institute of Computing: Master of Computer Applications (MCA)Rohit DahiyaNo ratings yet
- Case Study On Different Nosql Data ModelsDocument6 pagesCase Study On Different Nosql Data ModelsutkarshNo ratings yet
- What Is DatabaseDocument15 pagesWhat Is Databaseshivam kacholeNo ratings yet
- Mysql PDFDocument188 pagesMysql PDFBANKERS INFO 2019No ratings yet
- WhynosqlDocument12 pagesWhynosqlchitraalavaniNo ratings yet
- Cassandra: Types of Nosql DatabasesDocument6 pagesCassandra: Types of Nosql DatabasesVinod BihalNo ratings yet
- NoSQL Group1Document15 pagesNoSQL Group1ShawnNo ratings yet
- Chap 2 Emerging Database LandscapeDocument10 pagesChap 2 Emerging Database LandscapeSwatiJadhavNo ratings yet
- NoSQL DATABSESDocument12 pagesNoSQL DATABSESGaurav AroraNo ratings yet
- Lec 15 NotesDocument3 pagesLec 15 NotesRitikNo ratings yet
- DATABASE From the conceptual model to the final application in Access, Visual Basic, Pascal, Html and Php: Inside, examples of applications created with Access, Visual Studio, Lazarus and WampFrom EverandDATABASE From the conceptual model to the final application in Access, Visual Basic, Pascal, Html and Php: Inside, examples of applications created with Access, Visual Studio, Lazarus and WampNo ratings yet
- Data Mesh: Building Scalable, Resilient, and Decentralized Data Infrastructure for the Enterprise Part 1From EverandData Mesh: Building Scalable, Resilient, and Decentralized Data Infrastructure for the Enterprise Part 1No ratings yet
- Big Data NotesDocument70 pagesBig Data NotesGuru RajNo ratings yet
- Jump Start MySQL: Master the Database That Powers the WebFrom EverandJump Start MySQL: Master the Database That Powers the WebNo ratings yet
- Five Critical Dimensions Organizations Should Use To EvaluateDocument47 pagesFive Critical Dimensions Organizations Should Use To EvaluateBindu BhargaviNo ratings yet
- Unit 5Document17 pagesUnit 5kumarNo ratings yet
- Rational Database: By: Tyrick Minott Douglas Northover ShayDocument4 pagesRational Database: By: Tyrick Minott Douglas Northover ShayTyrick MinottNo ratings yet
- DBMS Da 2 (19bce1668)Document8 pagesDBMS Da 2 (19bce1668)Siddharth JrNo ratings yet
- NoSql 2024 Assign2Document189 pagesNoSql 2024 Assign2shanayasharma3301No ratings yet
- Differences DBMS RDBMSDocument4 pagesDifferences DBMS RDBMSbsgindia82No ratings yet
- Lecture 1Document50 pagesLecture 1Lakshay MITTALNo ratings yet
- DatabaseDocument15 pagesDatabasesadaf noorNo ratings yet
- DBMS - Chapter 1Document45 pagesDBMS - Chapter 1Harapriya MohantaNo ratings yet
- Data Base ModelsDocument26 pagesData Base ModelsTony JacobNo ratings yet
- A Database Is A Collection of Data That Is Stored in An Organized MannerDocument3 pagesA Database Is A Collection of Data That Is Stored in An Organized MannerVenkata HemanthNo ratings yet
- Aggregate Data Models Unit 2Document16 pagesAggregate Data Models Unit 2Devina CNo ratings yet
- Database System ConceptDocument33 pagesDatabase System ConceptDisha SharmaNo ratings yet
- Pindi Yulinar Rosita - Session 4Document3 pagesPindi Yulinar Rosita - Session 4Pindi YulinarNo ratings yet
- Oracle DBADocument569 pagesOracle DBASraVanKuMarThadakamalla100% (2)
- 2014 Ieee Computer NosqlDocument4 pages2014 Ieee Computer NosqlSagar PhullNo ratings yet
- Dbms 2Document9 pagesDbms 2Mohd AmirNo ratings yet
- Aggregate Data ModelsDocument55 pagesAggregate Data ModelschitraalavaniNo ratings yet
- Diffrance Between Database and DatawarehouseDocument3 pagesDiffrance Between Database and DatawarehouseganeshkultheNo ratings yet
- DatabaseDocument12 pagesDatabasenawasyt700No ratings yet
- Dbms 2Document9 pagesDbms 2Mohd AmirNo ratings yet
- TypesDocument7 pagesTypestemp16112000No ratings yet
- Working With The Database Management SystemDocument15 pagesWorking With The Database Management SystemCresanelle PoloNo ratings yet
- DBMS Ques and AnsDocument6 pagesDBMS Ques and AnsSonu YadavNo ratings yet
- DBMS Ques and AnsDocument6 pagesDBMS Ques and AnsSonu YadavNo ratings yet
- CS 2255 - Database Management SystemsDocument45 pagesCS 2255 - Database Management SystemsSaran RiderNo ratings yet
- Housing Price PredictionDocument7 pagesHousing Price PredictionA To Z INFONo ratings yet
- Minor Project Report - 1Document5 pagesMinor Project Report - 1A To Z INFONo ratings yet
- Mini Project Report FormatDocument22 pagesMini Project Report FormatA To Z INFONo ratings yet
- Module 4 Chapt1 DepreciationDocument15 pagesModule 4 Chapt1 DepreciationA To Z INFONo ratings yet
- Dayananda Sagar College of Engineering: (An Autonomous Institute Affiliated To VTU, Belagavi)Document3 pagesDayananda Sagar College of Engineering: (An Autonomous Institute Affiliated To VTU, Belagavi)Akshata PattarNo ratings yet
- TECHNICALPAPERDocument7 pagesTECHNICALPAPERA To Z INFONo ratings yet
- Skin Disease Detection Using Machine LearningDocument6 pagesSkin Disease Detection Using Machine LearningIJRASETPublicationsNo ratings yet
- TECHNICALPAPERDocument7 pagesTECHNICALPAPERA To Z INFONo ratings yet
- AI ML - LAB - Manual - 2020 - 211213 - 100634Document53 pagesAI ML - LAB - Manual - 2020 - 211213 - 100634Sachin C BNo ratings yet
- LexpgmDocument2 pagesLexpgmA To Z INFONo ratings yet
- UHV-Unit-2 NotesDocument19 pagesUHV-Unit-2 NotesA To Z INFONo ratings yet
- Mac ProtocolsDocument51 pagesMac ProtocolsA To Z INFONo ratings yet
- UHV-Unit 3 NotesDocument18 pagesUHV-Unit 3 NotesA To Z INFONo ratings yet
- Mod 5 SolutionsDocument11 pagesMod 5 SolutionsA To Z INFONo ratings yet
- Mod 5 QB AnswersDocument6 pagesMod 5 QB AnswersA To Z INFONo ratings yet
- Module 4 QB SolutionsDocument15 pagesModule 4 QB SolutionsA To Z INFONo ratings yet
- Unit 4 QBDocument1 pageUnit 4 QBA To Z INFONo ratings yet
- BCT Mod 2 QB AnsDocument11 pagesBCT Mod 2 QB AnsA To Z INFONo ratings yet
- Calender Auto 2017Document1 pageCalender Auto 2017Hareesha N GNo ratings yet
- Mod 5 SolutionsDocument11 pagesMod 5 SolutionsA To Z INFONo ratings yet
- Mod 5 QB AnswersDocument6 pagesMod 5 QB AnswersA To Z INFONo ratings yet
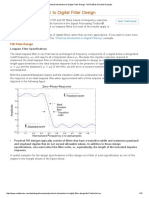
- Practical Introduction To Digital Filter Design - MATLAB ExampleDocument12 pagesPractical Introduction To Digital Filter Design - MATLAB ExampleEdsonNo ratings yet
- SCADA (Supervisory Control and Data Acquisition)Document20 pagesSCADA (Supervisory Control and Data Acquisition)Pao CastillonNo ratings yet
- Systems Theory: March 2017Document19 pagesSystems Theory: March 2017Ailie Christie PanedNo ratings yet
- Course OutlineDocument3 pagesCourse OutlineJawwad AhmedNo ratings yet
- LTA KL2300/24 AUG/JFK-MIA: - Not For Real World NavigationDocument52 pagesLTA KL2300/24 AUG/JFK-MIA: - Not For Real World NavigationAlcides Francisnei Oliveira da ConceicaoNo ratings yet
- Control SystemsDocument8 pagesControl SystemspadmajasivaNo ratings yet
- Systems Development Investigation and AnalysisDocument15 pagesSystems Development Investigation and AnalysisAditya Singh100% (1)
- BSC DSAI CurriculumDocument2 pagesBSC DSAI Curriculum�Mithra S S PSGRKCWNo ratings yet
- 4 Lecture 4-Dimensional ModellingDocument45 pages4 Lecture 4-Dimensional Modellingsignup8707No ratings yet
- Computer Application & GraphicsDocument44 pagesComputer Application & GraphicsHMGNo ratings yet
- Online Control of SVC Using ANN Based Pole Placement ApproachDocument5 pagesOnline Control of SVC Using ANN Based Pole Placement ApproachAbdo AliNo ratings yet
- c05 Net ModelsDocument55 pagesc05 Net ModelsRaunak TimilsinaNo ratings yet
- By Paul Pearsall, PHD Gary E. Schwartz, PHD Linda G. Russek, PHDDocument8 pagesBy Paul Pearsall, PHD Gary E. Schwartz, PHD Linda G. Russek, PHDJOSH USHERNo ratings yet
- L5Document75 pagesL5anon_584584906No ratings yet
- OOAD Sample PaperDocument23 pagesOOAD Sample PaperHassan Bin RaeesNo ratings yet
- FiltersDocument34 pagesFiltersPrashant ChaharNo ratings yet
- Lecture On 23-09-2020Document4 pagesLecture On 23-09-2020neemarawat11No ratings yet
- 2.5 Block Diagram AlgebraDocument28 pages2.5 Block Diagram AlgebraAklilu AyeleNo ratings yet
- Operations Management (OPM530) C11 MaintenanceDocument29 pagesOperations Management (OPM530) C11 Maintenanceazwan ayopNo ratings yet
- Boundary Conditions: Short Course On Molecular Dynamics SimulationDocument12 pagesBoundary Conditions: Short Course On Molecular Dynamics SimulationAmalVijayNo ratings yet
- Advanced Chemical Engineering Thermodynamics-CHE 211-S16 (05 262021) - Rev ADocument8 pagesAdvanced Chemical Engineering Thermodynamics-CHE 211-S16 (05 262021) - Rev ALi ChNo ratings yet
- Bus Suspension SystemDocument28 pagesBus Suspension SystemNor Diyana AhmadNo ratings yet
- Application Studies For Control System DesignDocument7 pagesApplication Studies For Control System DesignhanythekingNo ratings yet
- Lab Report Heat ExchangerDocument17 pagesLab Report Heat ExchangerFirdaus Zainal AbidinNo ratings yet
- OptimDocument70 pagesOptimNitin KumarNo ratings yet
- Executive Summary: Aluminum Alloy Vacuum Die-Casting Assistant System DevelopmentDocument2 pagesExecutive Summary: Aluminum Alloy Vacuum Die-Casting Assistant System DevelopmentjaydevpatelNo ratings yet
- Equation Sheet: Boyang Qin Date Created: Jan 2013Document3 pagesEquation Sheet: Boyang Qin Date Created: Jan 2013Boyang QinNo ratings yet
- Q Mxδt: Specific HeatDocument3 pagesQ Mxδt: Specific HeatNico YowNo ratings yet
- The Nature of Systems Development: WarningDocument12 pagesThe Nature of Systems Development: Warningrundy3100% (1)
- CENELEC EN 50128 and IEC 62279 Software For Safety Related SystemsDocument63 pagesCENELEC EN 50128 and IEC 62279 Software For Safety Related SystemsmachinmayNo ratings yet