You might also like
- Anatomy of A Program in Memory - Gustavo DuarteDocument41 pagesAnatomy of A Program in Memory - Gustavo DuarteRigs JuarezNo ratings yet
- Research On Artificial Intelligence Algorithm and Its Application in GamesDocument4 pagesResearch On Artificial Intelligence Algorithm and Its Application in GamesNavneet KumarNo ratings yet
- Anatomy of A Program in MemoryDocument5 pagesAnatomy of A Program in Memorythong_bvtNo ratings yet
- Cole's ResumeDocument1 pageCole's ResumeCole JohnsonNo ratings yet
- Role of Computer in ElectronicsDocument11 pagesRole of Computer in ElectronicsNabeel Raja100% (1)
- A Brinding ModelDocument28 pagesA Brinding ModelIgnacioMoya MorenoNo ratings yet
- p553 BoehmDocument12 pagesp553 Boehmnz0ptkNo ratings yet
- Pocketsphinx: A Free, Real-Time Continuous Speech Recognition System For Hand-Held DevicesDocument4 pagesPocketsphinx: A Free, Real-Time Continuous Speech Recognition System For Hand-Held DevicesThần SấmNo ratings yet
- How To Optimize PHP Script To Increase SpeedDocument4 pagesHow To Optimize PHP Script To Increase SpeedTran ManhNo ratings yet
- PDF 1675791423Document11 pagesPDF 1675791423Luis Eduardo Mamani ChambiNo ratings yet
- PDC Review2Document23 pagesPDC Review2corote1026No ratings yet
- Codesearchnet Challenge Evaluating The State of Semantic Code SearchDocument6 pagesCodesearchnet Challenge Evaluating The State of Semantic Code SearchRayverNo ratings yet
- cs301 FAQDocument9 pagescs301 FAQpirah chhachharNo ratings yet
- Anatomy of A Program in MemoryDocument19 pagesAnatomy of A Program in MemoryVictor J. PerniaNo ratings yet
- Scimakelatex 30610 NoneDocument7 pagesScimakelatex 30610 NoneOne TWoNo ratings yet
- Data-Parallel Large Vocabulary Continuous Speech Recognition On Graphics ProcessorsDocument13 pagesData-Parallel Large Vocabulary Continuous Speech Recognition On Graphics ProcessorsjikechongNo ratings yet
- M.Tech (Computer Science) : Submitted By:-Submitted ToDocument8 pagesM.Tech (Computer Science) : Submitted By:-Submitted ToSunita SinghNo ratings yet
- Machine LearningDocument6 pagesMachine LearningAnkit ShuklaNo ratings yet
- The Impact of Compact Epistemologies On Theory: Deniss RitchieDocument5 pagesThe Impact of Compact Epistemologies On Theory: Deniss RitchieJohn TurkletonNo ratings yet
- Codesearchnet Challenge Evaluating The State of Semantic Code SearchDocument6 pagesCodesearchnet Challenge Evaluating The State of Semantic Code SearchGuilherme LopesNo ratings yet
- Constructing I/O Automata and Object-Oriented Languages: Xander Hendrik and Ruben JudocusDocument5 pagesConstructing I/O Automata and Object-Oriented Languages: Xander Hendrik and Ruben JudocusJohnNo ratings yet
- Hardware-Based Parallel Firefly Algorithm For Embedded ApplicationsDocument8 pagesHardware-Based Parallel Firefly Algorithm For Embedded ApplicationsCarlos Humberto LlanosNo ratings yet
- Bayesian Optimisation (AutoML)Document26 pagesBayesian Optimisation (AutoML)iit2020211No ratings yet
- Speed Up Your Numpy and Pandas With Numexpr Package: You Have 2 Free Stories Left This MonthDocument11 pagesSpeed Up Your Numpy and Pandas With Numexpr Package: You Have 2 Free Stories Left This MonthVikash RryderNo ratings yet
- To HPC With MPI For Data Science: Frank NielsenDocument304 pagesTo HPC With MPI For Data Science: Frank NielsenِAhmed Jebur AliNo ratings yet
- Constructing Neural Networks Using "Smart" Algorithms: El, Yo and TuDocument7 pagesConstructing Neural Networks Using "Smart" Algorithms: El, Yo and TujohnturkletonNo ratings yet
- Computer Architecture QuestionsDocument10 pagesComputer Architecture QuestionsdanielNo ratings yet
- Similar PHP Interview QuestionsDocument36 pagesSimilar PHP Interview QuestionsgijorajNo ratings yet
- Scimakelatex 32233 NoneDocument7 pagesScimakelatex 32233 NoneLarchNo ratings yet
- sathyabama-IIsem-Distributed Computing-683201-783201Document2 pagessathyabama-IIsem-Distributed Computing-683201-783201ShankarNo ratings yet
- Department of Computing: Lab 7: Programming Threads CLO4 (Develop Programs To Interact With OS Components Through Its API)Document4 pagesDepartment of Computing: Lab 7: Programming Threads CLO4 (Develop Programs To Interact With OS Components Through Its API)Waseem AbbasNo ratings yet
- Deconstructing ArchitectureDocument6 pagesDeconstructing ArchitecturemcneagoeNo ratings yet
- Matlab Matlab Toolbox Deep Learning Toolbox Neural Network Toolbox Libraries Functions How To UseDocument5 pagesMatlab Matlab Toolbox Deep Learning Toolbox Neural Network Toolbox Libraries Functions How To UseDiya ShahNo ratings yet
- Lossless Theory For SchemeDocument6 pagesLossless Theory For SchemeVinicius UchoaNo ratings yet
- Guidelines For Programming in High Performance Fortran: by Dave PruettDocument4 pagesGuidelines For Programming in High Performance Fortran: by Dave Pruettkadung3394No ratings yet
- Memory and ClassificationDocument8 pagesMemory and Classificationsingh7863No ratings yet
- Scalable Distributed Depth-First Search With Greedy Work StealingDocument15 pagesScalable Distributed Depth-First Search With Greedy Work StealingXiaoqin ZhouNo ratings yet
- Architecting Digital-to-Analog Converters and Hierarchical DatabasesDocument7 pagesArchitecting Digital-to-Analog Converters and Hierarchical DatabasesOne TWoNo ratings yet
- Genoogle: An Indexed and Parallelized Search Engine For Similar DNA SequencesDocument18 pagesGenoogle: An Indexed and Parallelized Search Engine For Similar DNA SequencesFelipe AlbrechtNo ratings yet
- Multicore Framework: An Api For Programming Heterogeneous Multicore ProcessorsDocument7 pagesMulticore Framework: An Api For Programming Heterogeneous Multicore ProcessorsAlephNullNo ratings yet
- Com Roan in & Ar It ReDocument35 pagesCom Roan in & Ar It ReWaseem Muhammad KhanNo ratings yet
- The Adaptive Radix Tree: Artful Indexing For Main-Memory DatabasesDocument12 pagesThe Adaptive Radix Tree: Artful Indexing For Main-Memory DatabasesGabriella EllaNo ratings yet
- Case Studies C++Document5 pagesCase Studies C++Vaibhav ChitranshNo ratings yet
- Previous Home NextDocument12 pagesPrevious Home NextHassaan RanaNo ratings yet
- Coupling Loop Transformations and High-Level Synthesis: Mots-ClésDocument10 pagesCoupling Loop Transformations and High-Level Synthesis: Mots-ClésArnaldo C SantosNo ratings yet
- Improving Data Locality by ChunkingDocument15 pagesImproving Data Locality by ChunkingSalim MehenniNo ratings yet
- Pig Mix BenchmarkDocument6 pagesPig Mix BenchmarkabhimonicaNo ratings yet
- Scimakelatex 3043 NoneDocument6 pagesScimakelatex 3043 NonefsofNo ratings yet
- A Preliminary Study of Size Optimization For Text-Based Web-ResourceDocument5 pagesA Preliminary Study of Size Optimization For Text-Based Web-ResourceHny Henny HennyNo ratings yet
- Stream Processing in General-Purpose ProcessorsDocument1 pageStream Processing in General-Purpose Processorszalmighty78No ratings yet
- Irt AnsDocument9 pagesIrt AnsSanjay ShankarNo ratings yet
- HC-Sim: A Fast and Exact L1 Cache Simulator With Scratchpad Memory Co-Simulation SupportDocument10 pagesHC-Sim: A Fast and Exact L1 Cache Simulator With Scratchpad Memory Co-Simulation SupportSebastian De la Paz IIINo ratings yet
- Unit 3 Parallel Programming: Structure NosDocument26 pagesUnit 3 Parallel Programming: Structure NosChetan SolankiNo ratings yet
- Memory Management: Background Swapping Contiguous AllocationDocument51 pagesMemory Management: Background Swapping Contiguous AllocationFazrul RosliNo ratings yet
- 2ObsPy - What Can It Do For Data Centers and ObservatoriesDocument12 pages2ObsPy - What Can It Do For Data Centers and ObservatoriesMacarena CárcamoNo ratings yet
- A Bfs-Based Similar Conference Retrieval FrameworkDocument8 pagesA Bfs-Based Similar Conference Retrieval FrameworkCS & ITNo ratings yet
- Python Interview Questions and Answers PDFDocument4 pagesPython Interview Questions and Answers PDFsushmitha nNo ratings yet
- Scimakelatex 69254 Travis+Herrick Michael+meredith Austin+stoneDocument7 pagesScimakelatex 69254 Travis+Herrick Michael+meredith Austin+stoneTravis HerrickNo ratings yet
- Schmidt - GPERF Perfect Hash Gemerator FunctionDocument13 pagesSchmidt - GPERF Perfect Hash Gemerator Functionanon-355439100% (1)
- Unstable, Pervasive Symmetries For The Partition TableDocument12 pagesUnstable, Pervasive Symmetries For The Partition TableLuaNo ratings yet
- School of Informatics Department of Computer Science Data Mining Lab Indivitual Assignment Name: Kidist Mengistu ID: Cs/we/232/11 Section: 4Document11 pagesSchool of Informatics Department of Computer Science Data Mining Lab Indivitual Assignment Name: Kidist Mengistu ID: Cs/we/232/11 Section: 4Mesafint WorkuNo ratings yet
- The Art of Assembly Language Programming Using PIC® Technology: Core FundamentalsFrom EverandThe Art of Assembly Language Programming Using PIC® Technology: Core FundamentalsNo ratings yet
- (2022) SkyCare EMR - PresentationDocument14 pages(2022) SkyCare EMR - PresentationMestthathanNo ratings yet
- PYTHON Training Report PDFDocument47 pagesPYTHON Training Report PDFLalit SinghaLNo ratings yet
- Facebook in BangladeshDocument16 pagesFacebook in BangladeshFaria Hossain100% (1)
- Prof. Dr. Lilian Mitrou: Data Protection, Artificial Intelligence and Cognitive ServicesDocument90 pagesProf. Dr. Lilian Mitrou: Data Protection, Artificial Intelligence and Cognitive Servicesjulierme rodriguesNo ratings yet
- Dplyr Mutate in RDocument2 pagesDplyr Mutate in RloshudeNo ratings yet
- DBMS With SQL Server (Session 1)Document40 pagesDBMS With SQL Server (Session 1)Arif NazeerNo ratings yet
- TENOR2015 ProceedingsDocument259 pagesTENOR2015 ProceedingsJamesNo ratings yet
- Embedded LinuxDocument333 pagesEmbedded LinuxSiva100% (5)
- Dev Express End-User DocumentationDocument138 pagesDev Express End-User DocumentationWiwat TanwongwanNo ratings yet
- Operating Instructions Software UCOMDocument12 pagesOperating Instructions Software UCOMSaid TouhamiNo ratings yet
- BI Unit4Document83 pagesBI Unit4ShadowOPNo ratings yet
- FlexiPanels LineDocument4 pagesFlexiPanels Linemksamy2021No ratings yet
- DevOps ContentDocument32 pagesDevOps ContentVenkata Ramanaiah KokaNo ratings yet
- Oracle 10gr2 RAC On VmwareDocument137 pagesOracle 10gr2 RAC On VmwareRajNo ratings yet
- Regine Velasquez: The Asians Song BirdDocument9 pagesRegine Velasquez: The Asians Song BirdNeo127No ratings yet
- Narendra ResumeDocument2 pagesNarendra ResumeNarendra KumarNo ratings yet
- How To Install GTA Vice City Game?Document1 pageHow To Install GTA Vice City Game?Nagu S PillaiNo ratings yet
- Proposal Title: Cell Phone Controlled Vehicle Using DTMFDocument34 pagesProposal Title: Cell Phone Controlled Vehicle Using DTMFFìrœ Lōv MånNo ratings yet
- Nationals Action List 2013 PDFDocument2 pagesNationals Action List 2013 PDFAmy AelaNo ratings yet
- Technical Manual IndexDocument4 pagesTechnical Manual IndexDaniel ZorodekNo ratings yet
- Maya Technical Paper: How To Set Up and Optimise Alpha Planes When Using Mental Ray Tutorial KeyDocument12 pagesMaya Technical Paper: How To Set Up and Optimise Alpha Planes When Using Mental Ray Tutorial KeyDayleSandersNo ratings yet
- Open Source IDS ToolsDocument9 pagesOpen Source IDS ToolsMadhuri DesaiNo ratings yet
- Inside RacDocument106 pagesInside RacRaghuNo ratings yet
- AUC's 100-Year Logo Design Competition: February 18, 2018. The Selected Logo Design Will Be UsedDocument1 pageAUC's 100-Year Logo Design Competition: February 18, 2018. The Selected Logo Design Will Be UsedMark11311No ratings yet
- CepstrumDocument5 pagesCepstrumPawan SharmaNo ratings yet
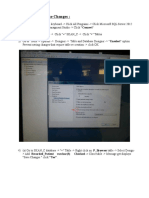
- SKANC Database Changes:: Varchar (3) Checked - Close Table - Message Get DisplaysDocument5 pagesSKANC Database Changes:: Varchar (3) Checked - Close Table - Message Get Displaysابو حميد ابو حميدNo ratings yet
- 5th Sem DBMS Super Important - TIE 2Document1 page5th Sem DBMS Super Important - TIE 2Game IsmineNo ratings yet