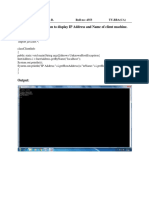
You might also like
- 52 Model Building Set Web Models 8 13465Document57 pages52 Model Building Set Web Models 8 13465kaganp784No ratings yet
- Steps To GetFolderIDFromPath When Using Framework Folders in UCMDocument5 pagesSteps To GetFolderIDFromPath When Using Framework Folders in UCMDhina Karan100% (1)
- ZetorDocument34 pagesZetorNoivo_da_LagoaNo ratings yet
- 8HP45Document8 pages8HP45Adrian Biasussi Biasuzzi100% (7)
- Little Squirrel DIY Crochet PatternDocument12 pagesLittle Squirrel DIY Crochet PatternAnastasia Mouse100% (4)
- JDBC Lecture NotesDocument14 pagesJDBC Lecture NotesminniNo ratings yet
- Spark Job DataprocDocument4 pagesSpark Job DataprocDenys StolbovNo ratings yet
- Create An Spark Streaming App: 1. Architecture and AbstractionDocument8 pagesCreate An Spark Streaming App: 1. Architecture and AbstractionNgô HoàngNo ratings yet
- 4X Database JDBCDocument75 pages4X Database JDBCpavan pongleNo ratings yet
- 05_functionsDocument6 pages05_functionsjenNo ratings yet
- AJP No.18Document2 pagesAJP No.18Saraswati ShelkeNo ratings yet
- SPARK SQL AND GRAPHX ANALYSISDocument5 pagesSPARK SQL AND GRAPHX ANALYSISbenben08No ratings yet
- Project 2 - Phase 2Document4 pagesProject 2 - Phase 2Srinivas HNo ratings yet
- C Make ListsDocument8 pagesC Make ListsSubhaharan SvNo ratings yet
- JDBCDocument7 pagesJDBCpreethiNo ratings yet
- BIRT REPORT ENGINE SOURCE CODEDocument3 pagesBIRT REPORT ENGINE SOURCE CODEArr RANo ratings yet
- JDBCDocument26 pagesJDBCnaresh madduNo ratings yet
- Python CodeDocument7 pagesPython CodeGnan ShettyNo ratings yet
- Pyspark - SQL ModuleDocument132 pagesPyspark - SQL Modulesergii volodarskiNo ratings yet
- Spark SQL, RDDs, and DataFramesDocument12 pagesSpark SQL, RDDs, and DataFramesRambabu GiduturiNo ratings yet
- Cadence To Matlab TutorialDocument3 pagesCadence To Matlab TutorialpetricliNo ratings yet
- Csharp SqliteDocument8 pagesCsharp SqliteZheng JunNo ratings yet
- CS4273: Distributed System Technologies and Programming I: Lecture 8: Java Database Connection (JDBC)Document23 pagesCS4273: Distributed System Technologies and Programming I: Lecture 8: Java Database Connection (JDBC)Lethal11No ratings yet
- Developing web services using JAX-RPCDocument19 pagesDeveloping web services using JAX-RPCRavindra VangipuramNo ratings yet
- DataGrokr Technical Assignment - Data Engineering - InternshalaDocument5 pagesDataGrokr Technical Assignment - Data Engineering - InternshalaVinutha MNo ratings yet
- AWS Big DataDocument39 pagesAWS Big DataAditya Mehta100% (1)
- Class Presentations On Object Oriented Programming by Subhash Chand AgrawalDocument49 pagesClass Presentations On Object Oriented Programming by Subhash Chand AgrawalEshan RathoreNo ratings yet
- Installing Spark On Windows EnvironmentDocument16 pagesInstalling Spark On Windows EnvironmentDr Mohammed KamalNo ratings yet
- Apache CXF With JAX-RS: Declaring Movie ElementDocument8 pagesApache CXF With JAX-RS: Declaring Movie ElementkrkamaNo ratings yet
- Answers Java Part 1Document18 pagesAnswers Java Part 1Indranil PathakNo ratings yet
- Learning Apache Spark With PythonDocument10 pagesLearning Apache Spark With PythondalalroshanNo ratings yet
- Statement TypesDocument9 pagesStatement TypesHari Chandrudu MNo ratings yet
- Python PostgreSQL BasicsDocument19 pagesPython PostgreSQL BasicsbobosenthilNo ratings yet
- Hands On Lab Guide For Data Lake PDFDocument19 pagesHands On Lab Guide For Data Lake PDFPrasadValluraNo ratings yet
- Java Lab: Object Serialization and Currency ClassesDocument23 pagesJava Lab: Object Serialization and Currency ClassesRithika M NagendiranNo ratings yet
- JDBC Database ConnectivityDocument19 pagesJDBC Database ConnectivityKHUSHINo ratings yet
- Lab Experiment - 1: Objective: Create The Following Java Project Using IBM RAD 8.5Document25 pagesLab Experiment - 1: Objective: Create The Following Java Project Using IBM RAD 8.5Surbhi JainNo ratings yet
- Java Prin OutsDocument20 pagesJava Prin OutsRam KaleNo ratings yet
- 5 - Programming With RDDs and DataframesDocument32 pages5 - Programming With RDDs and Dataframesravikumar lankaNo ratings yet
- Ajp PRC 18Document4 pagesAjp PRC 18nstrnsdtnNo ratings yet
- (Big Data Analytics With PySpark) (CheatSheet)Document7 pages(Big Data Analytics With PySpark) (CheatSheet)Niwahereza DanNo ratings yet
- Final Print Py SparkDocument133 pagesFinal Print Py SparkShivaraj KNo ratings yet
- Build pico-sdk RF24 libraryDocument4 pagesBuild pico-sdk RF24 libraryChien Nguyen Van KhanhNo ratings yet
- JDBC Netbeans MysqlDocument18 pagesJDBC Netbeans Mysqlgrprasad1957No ratings yet
- Slide 2Document68 pagesSlide 2dejenedagime999No ratings yet
- Session - 2: SEED Infotech Pvt. LTDDocument42 pagesSession - 2: SEED Infotech Pvt. LTDAnonymous FKWVgNnSjoNo ratings yet
- 2Document6 pages2Ayush nemaNo ratings yet
- SparkDocument17 pagesSparkRavi KumarNo ratings yet
- CrudoDocument16 pagesCrudodavisxzNo ratings yet
- Create Database Using JDBC in JavaDocument23 pagesCreate Database Using JDBC in JavaArshdeep SinghNo ratings yet
- SparkDocument1 pageSparkJosue Rueda GarciaNo ratings yet
- Netbean Configuration For CSQLDocument10 pagesNetbean Configuration For CSQLBijaya Kumar SahuNo ratings yet
- Informatica2 PDFDocument200 pagesInformatica2 PDFAriel CupertinoNo ratings yet
- SPARK RDD PROCESSINGDocument7 pagesSPARK RDD PROCESSINGNagraj GoudNo ratings yet
- Appnote-Sample Workflow AgentsDocument17 pagesAppnote-Sample Workflow AgentsRoxanne SaucedoNo ratings yet
- SparkDocument12 pagesSparkPRAMOTH KJNo ratings yet
- Lecture-3.2.2Document31 pagesLecture-3.2.2gdgdNo ratings yet
- Creating RDDDocument2 pagesCreating RDDParveen MittalNo ratings yet
- Dynamic Code Generation With Java Compiler API in Java 6: by Swaminathan Bhaskar 10/10/2009Document14 pagesDynamic Code Generation With Java Compiler API in Java 6: by Swaminathan Bhaskar 10/10/2009M Anas MasoodNo ratings yet
- How To Write Plugins For BP2XDocument10 pagesHow To Write Plugins For BP2XHenoch Litha DandanNo ratings yet
- What Is CC Really Doing - The Condensed Version: NextDocument15 pagesWhat Is CC Really Doing - The Condensed Version: NextFredNo ratings yet
- PART8-SAP TO Internet CommunicationsDocument13 pagesPART8-SAP TO Internet Communicationsapi-3746151No ratings yet
- JDBC NotesDocument2 pagesJDBC Notessreekanth seelamNo ratings yet
- Solution MethodologyDocument5 pagesSolution MethodologyArnab DeyNo ratings yet
- 15 In-Depth Interviews With Data ScientistsDocument153 pages15 In-Depth Interviews With Data ScientistsSrini MNo ratings yet
- Data Science Infinity Transition RoadmapDocument34 pagesData Science Infinity Transition RoadmapArnab DeyNo ratings yet
- Lecture Notes - Introduction To EcommerceDocument6 pagesLecture Notes - Introduction To EcommerceHarshavardhiniNo ratings yet
- PAW Print PAW Print PAW Print PAW Print: Principal's Column Principal's Column Principal's Column Principal's ColumnDocument6 pagesPAW Print PAW Print PAW Print PAW Print: Principal's Column Principal's Column Principal's Column Principal's Columntica1118No ratings yet
- Tyranny DomainDocument1 pageTyranny DomainJoao Marcos de AquinoNo ratings yet
- GbatekDocument1,426 pagesGbatekWen HuaNo ratings yet
- Swing Machinery Motor and Mach PDFDocument2 pagesSwing Machinery Motor and Mach PDFalexander0% (1)
- Ducati Panigale Superbike 959 MY16 enDocument152 pagesDucati Panigale Superbike 959 MY16 enAdrian ChippendaleNo ratings yet
- Game of KingsDocument2 pagesGame of KingsRuqiyya QayyumNo ratings yet
- Woodsmen de Artois (Mousillon Setting) PDFDocument6 pagesWoodsmen de Artois (Mousillon Setting) PDFArgel_Tal100% (1)
- U3-01 - Rhino Pattern - ENDocument7 pagesU3-01 - Rhino Pattern - ENPamela Alejandra100% (4)
- Electric equipment price list 2017Document18 pagesElectric equipment price list 2017Halil GndzNo ratings yet
- Reviung41 LayoutDocument2 pagesReviung41 LayoutDananjaya Yogie HartantoNo ratings yet
- Đề Cương Giữa Kì Ii: I. Choose the correct answersDocument6 pagesĐề Cương Giữa Kì Ii: I. Choose the correct answersThị Huyền Trang NguyễnNo ratings yet
- PE 3 Module 4 Badminton Conditioning and Sport Specific DrillsDocument6 pagesPE 3 Module 4 Badminton Conditioning and Sport Specific DrillsMatthew ScarellaNo ratings yet
- Owner'S: ManualDocument19 pagesOwner'S: ManualValentin SerebrinskyNo ratings yet
- Radix Bruce LeeDocument1 pageRadix Bruce LeeDiogo TeixeiraNo ratings yet
- Goblin Rogue Level 1Document2 pagesGoblin Rogue Level 1Eryk WisniewskiNo ratings yet
- Historical Foundations of Physical EducationDocument4 pagesHistorical Foundations of Physical Educationamee flor b. relletaNo ratings yet
- Hyundai Tucson 2.0 Turbo Diesel 4X4Document2 pagesHyundai Tucson 2.0 Turbo Diesel 4X4Akhalaia BadriNo ratings yet
- Bach Violin Concerto in A Minor BWV 1041 - Lead SheetDocument34 pagesBach Violin Concerto in A Minor BWV 1041 - Lead SheetKelvin Olaiya100% (1)
- 1111111Document73 pages1111111deatzarNo ratings yet
- K 12 Template (Classrecord) 1sapagaDocument60 pagesK 12 Template (Classrecord) 1sapagaJobel Sibal CapunfuerzaNo ratings yet
- Lastexception 63821054770Document2 pagesLastexception 63821054770Ілля КондратюкNo ratings yet
- Technology Is Turning The Business of Culture Upside Down PDFDocument1 pageTechnology Is Turning The Business of Culture Upside Down PDFSophiaNo ratings yet
- Basketball Test PDFDocument2 pagesBasketball Test PDFAnonymous l2ryFD2i0% (1)
- TVQMA 2009 Race#4 ResultsDocument2 pagesTVQMA 2009 Race#4 ResultsMichaelNo ratings yet
- A240, A241, A243, A244, A245 (4 Speed FWD) Transmission Parts ListDocument2 pagesA240, A241, A243, A244, A245 (4 Speed FWD) Transmission Parts ListAlex Gonçalves de SouzaNo ratings yet
- CH Honeybunch (ROM)Document6 pagesCH Honeybunch (ROM)sallyfrankenwarte100% (2)