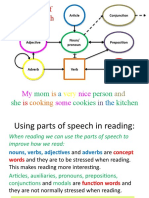
You might also like
- As 1428.1-2009, Design For Access and Mobility - Parte 1Document29 pagesAs 1428.1-2009, Design For Access and Mobility - Parte 1Arturo lopez abucharNo ratings yet
- Secret Codes-Ken BeattyDocument64 pagesSecret Codes-Ken BeattyElena ManeaNo ratings yet
- Design Technology and InnovationDocument52 pagesDesign Technology and InnovationAshriti Jain50% (2)
- Portfolio Ferril SamalDocument84 pagesPortfolio Ferril SamalFerril SamalNo ratings yet
- Edet300 At2Document12 pagesEdet300 At2Chloe NajemNo ratings yet
- Not Low-Resource Anymore: Aligner Ensembling, Batch Filtering, and New Datasets For Bengali-English Machine TranslationDocument12 pagesNot Low-Resource Anymore: Aligner Ensembling, Batch Filtering, and New Datasets For Bengali-English Machine TranslationAparajita AggarwalNo ratings yet
- Mridul 2021 Ijca 921582Document7 pagesMridul 2021 Ijca 921582windows masterNo ratings yet
- ICON-2013 Submission 36Document10 pagesICON-2013 Submission 36Aparajita AggarwalNo ratings yet
- Research PapersDocument5 pagesResearch PapersHarshit DhumalNo ratings yet
- Efficient Approach For ISL Using MLDocument4 pagesEfficient Approach For ISL Using MLsugar cubeNo ratings yet
- NMT Based Similar Language Translation For Hindi - MarathiDocument4 pagesNMT Based Similar Language Translation For Hindi - MarathiKrishna GuptaNo ratings yet
- 1 s2.0 S0957417423023151 MainDocument17 pages1 s2.0 S0957417423023151 MainBaba AliNo ratings yet
- Language To Language Translation System Using LSTMDocument5 pagesLanguage To Language Translation System Using LSTMWARSE JournalsNo ratings yet
- A Novel Approach To Paraphrase Hindi Sentences Using Natural Language ProcessingDocument6 pagesA Novel Approach To Paraphrase Hindi Sentences Using Natural Language ProcessingJuca CrispimNo ratings yet
- 2023 Banglalp-1 2Document11 pages2023 Banglalp-1 2data.ana18No ratings yet
- Hindi Text ClassificationDocument7 pagesHindi Text ClassificationKushagra BhatiaNo ratings yet
- A Study of Myanmar Word Segmentation Schemes For Statistical Machine TranslationDocument13 pagesA Study of Myanmar Word Segmentation Schemes For Statistical Machine TranslationHusien NaserNo ratings yet
- Parsing 2Document7 pagesParsing 2ስቶፕ ጀኖሳይድNo ratings yet
- Indian Sign Language Converter Using Convolutional Neural NetworksDocument5 pagesIndian Sign Language Converter Using Convolutional Neural NetworksGurudev YankanchiNo ratings yet
- Segmentation of Devanagari Handwritten Characters: Ankita Srivastav Neha SahuDocument4 pagesSegmentation of Devanagari Handwritten Characters: Ankita Srivastav Neha SahuRaghavendra RaoNo ratings yet
- Corpus Based Machine Translation System With Deep Neural Network For Sanskrit To Hindi Translation Corpus Based Machine Translation System With Deep Neural Network For Sanskrit To Hindi TranslationDocument11 pagesCorpus Based Machine Translation System With Deep Neural Network For Sanskrit To Hindi Translation Corpus Based Machine Translation System With Deep Neural Network For Sanskrit To Hindi TranslationhiraNo ratings yet
- Lattice Based Lexical Transfer in BengalDocument8 pagesLattice Based Lexical Transfer in BengalAparajita AggarwalNo ratings yet
- Dcnn-Bigru Text Classification Model Based On Bert EmbeddingDocument6 pagesDcnn-Bigru Text Classification Model Based On Bert EmbeddingLarissa FelicianaNo ratings yet
- Patoary 2020Document4 pagesPatoary 2020Nagaraj LutimathNo ratings yet
- Paraphrasing Hindi TextDocument22 pagesParaphrasing Hindi TextAnupam TeliNo ratings yet
- A Punjabi To Hindi Machine Translation System.: January 2008Document27 pagesA Punjabi To Hindi Machine Translation System.: January 2008Abhay DixitNo ratings yet
- Sharika Malayalam Speech Recognition System: Shyam.k MES College of Engineering, KuttipuramDocument4 pagesSharika Malayalam Speech Recognition System: Shyam.k MES College of Engineering, KuttipuramrenjithNo ratings yet
- Text To Speech Conversion ModuleDocument8 pagesText To Speech Conversion ModuleDoleanu Mihai-GabrielNo ratings yet
- Continuous Density Hidden Markov Model For Hindi Speech RecognitionDocument7 pagesContinuous Density Hidden Markov Model For Hindi Speech RecognitionAbdelkbir WsNo ratings yet
- Direct Speech-to-Image TranslationDocument13 pagesDirect Speech-to-Image TranslationanuNo ratings yet
- Word Based Statistical Machine Translation From English Text To Indian Sign LanguageDocument8 pagesWord Based Statistical Machine Translation From English Text To Indian Sign LanguagezemikeNo ratings yet
- Text To Speech System For KonkaniDocument6 pagesText To Speech System For Konkanivijayrebello4uNo ratings yet
- Text To SpeechDocument9 pagesText To SpeechDevansh SinghNo ratings yet
- Banlga Text To Bangla Sign Language Parvez For ConferenceDocument6 pagesBanlga Text To Bangla Sign Language Parvez For ConferenceDr. Muhammad Aminur RahamanNo ratings yet
- Speech To Image Translation Framework For Teacher-Student Learning - Using Ieee FormatDocument6 pagesSpeech To Image Translation Framework For Teacher-Student Learning - Using Ieee FormatanuNo ratings yet
- Paper 3Document6 pagesPaper 3mukundaspoorthiNo ratings yet
- Research Paper 2Document6 pagesResearch Paper 2ReshmaNo ratings yet
- Comparison of Urdu Text To Speech Synthesis Using Unit Selection and HMM Based Techniques PDFDocument5 pagesComparison of Urdu Text To Speech Synthesis Using Unit Selection and HMM Based Techniques PDFAkhtar AkbarNo ratings yet
- Amritha PDFDocument7 pagesAmritha PDFArshi BharadwajNo ratings yet
- A Punjabi To Hindi Machine Transliteration System: Gurpreet Singh Josan, and Gurpreet Singh LehalDocument26 pagesA Punjabi To Hindi Machine Transliteration System: Gurpreet Singh Josan, and Gurpreet Singh LehalAbcdNo ratings yet
- Parts of SpeechDocument31 pagesParts of Speechsergio alcazarNo ratings yet
- Grammar Teaching Tools For Tamil LanguageDocument4 pagesGrammar Teaching Tools For Tamil LanguagekaruldeepaNo ratings yet
- Neural Machine Translation For English-Tamil: Himanshu Choudhary Aditya Kumar PathakDocument7 pagesNeural Machine Translation For English-Tamil: Himanshu Choudhary Aditya Kumar PathakKibruyesfa MeseleNo ratings yet
- Deep Learning Based Multilingual Speech Synthesis Using Multi Feature Fusion MethodsDocument16 pagesDeep Learning Based Multilingual Speech Synthesis Using Multi Feature Fusion Methodszerihun nanaNo ratings yet
- A Solution For Line Segmentation Problems in Sindhi Character Recognition SystemDocument7 pagesA Solution For Line Segmentation Problems in Sindhi Character Recognition Systemਗੁਰਪ੍ਰੀਤ ਸਿੰਘ ਲਹਿਲNo ratings yet
- Applsci 13 04636 v3Document16 pagesApplsci 13 04636 v3stutinahujaNo ratings yet
- 2.2 Activity DiagramDocument18 pages2.2 Activity Diagramewanewan27No ratings yet
- Word Prediction Using Trie Data Structure: J Component Project ReportDocument81 pagesWord Prediction Using Trie Data Structure: J Component Project ReportSPANDAN KUMARNo ratings yet
- Comparison Analysis of Post - Processing Method For Punjabi FontDocument6 pagesComparison Analysis of Post - Processing Method For Punjabi FontAnonymous CUPykm6DZNo ratings yet
- Review of Text To Speech Conversion Methods: Poonam.S.Shetake, S.A.Patil, P. M JadhavDocument7 pagesReview of Text To Speech Conversion Methods: Poonam.S.Shetake, S.A.Patil, P. M Jadhavharshitha harshithaNo ratings yet
- Pretraining-Based Natural Language Generation For Text SummarizationDocument7 pagesPretraining-Based Natural Language Generation For Text SummarizationSyeda Anum FatimaNo ratings yet
- NLP Project Final Report1Document10 pagesNLP Project Final Report1hewepo4344No ratings yet
- OromignaDocument19 pagesOromignazerihun nanaNo ratings yet
- Assignment On Paraprasing in NLPDocument12 pagesAssignment On Paraprasing in NLPyaNo ratings yet
- A Data Driven Synthesis Approach For IndDocument7 pagesA Data Driven Synthesis Approach For IndVR IndaNo ratings yet
- Foreign Accent Conversion Through Voice MorphingDocument6 pagesForeign Accent Conversion Through Voice Morphingrachitapatel449No ratings yet
- ACL 2020 Proceedings Template 2 PDFDocument4 pagesACL 2020 Proceedings Template 2 PDFVijay ShankarNo ratings yet
- Referensi Levenshtein 5Document5 pagesReferensi Levenshtein 5rivaharny_878294630No ratings yet
- NLP Project Final Report1Document10 pagesNLP Project Final Report1Abhishek DhakaNo ratings yet
- Deep Learning Based TTS-STT Model With Transliteration For Indic LanguagesDocument9 pagesDeep Learning Based TTS-STT Model With Transliteration For Indic LanguagesIJRASETPublicationsNo ratings yet
- Bangla Text To Speech Using Festival: Firoj Alam S.M. Murtoza Habib Mumit KhanDocument8 pagesBangla Text To Speech Using Festival: Firoj Alam S.M. Murtoza Habib Mumit KhanAnonymous 75M6uB3OwNo ratings yet
- Word Spotting in Gray Scale Handwritten Pashto Documents: Muhammad Ismail Shah Ching Y. SuenDocument6 pagesWord Spotting in Gray Scale Handwritten Pashto Documents: Muhammad Ismail Shah Ching Y. SuencthjgfytvfnoNo ratings yet
- Machine Translation and Its Approaches: Vanlalmuansangi Khenglawt, Lal AnpuiaDocument5 pagesMachine Translation and Its Approaches: Vanlalmuansangi Khenglawt, Lal AnpuiaMatiyas GutemaNo ratings yet
- LEVEL 4 - WorksheetDocument42 pagesLEVEL 4 - WorksheetHEEEUN LEENo ratings yet
- IELTS Practice Tests PlusDocument15 pagesIELTS Practice Tests PlusPriyalNo ratings yet
- Types of Essays Length of An EssayDocument4 pagesTypes of Essays Length of An Essaysadhini lokuliyanaNo ratings yet
- Hassen SeidDocument88 pagesHassen Seidzelalem tamrieNo ratings yet
- How To Write An EssayDocument5 pagesHow To Write An EssayWane DavisNo ratings yet
- STA228459e 2022 ks2 Mathematics Administering Braille Paper2 ReasoningDocument4 pagesSTA228459e 2022 ks2 Mathematics Administering Braille Paper2 ReasoningYakshrajsinh JadejaNo ratings yet
- Colorado Accommodations ManualDocument81 pagesColorado Accommodations ManualJeannette DorfmanNo ratings yet
- Jheel Khuranja CWSN Ts ReadyDocument20 pagesJheel Khuranja CWSN Ts Readyassistant enginnerNo ratings yet
- Disability Inclusive Language GuidelinesDocument11 pagesDisability Inclusive Language GuidelinesΚυριακή ΠασχαλίδουNo ratings yet
- Jan To Nov Current Affairs 2022Document244 pagesJan To Nov Current Affairs 2022AfifaNo ratings yet
- اول وحدتين من كونكت بلس 4 ماى فريندDocument74 pagesاول وحدتين من كونكت بلس 4 ماى فريندmido_20067581No ratings yet
- Past Tense LOUIS BRAILLE (1809-1852)Document3 pagesPast Tense LOUIS BRAILLE (1809-1852)lolas 456No ratings yet
- IELTS Listening Practice Test 6 PrintableDocument10 pagesIELTS Listening Practice Test 6 PrintableHa ANo ratings yet
- Ethiopia - Sebeta School For The BlindDocument24 pagesEthiopia - Sebeta School For The BlindMike WalshNo ratings yet
- GESPv2024 01 06Document60 pagesGESPv2024 01 06MARICRIS SALUD100% (1)
- Arranged Braille Computer Display BoardDocument24 pagesArranged Braille Computer Display BoardPrasannaNo ratings yet
- Annex-I - HEC Policy For Students With Disabilities 2021 (Revised)Document11 pagesAnnex-I - HEC Policy For Students With Disabilities 2021 (Revised)Nasir HussainNo ratings yet
- How Do Information and Media Improve Life in Online Business?Document4 pagesHow Do Information and Media Improve Life in Online Business?Erica MarcosNo ratings yet
- Tactile Communication Design For Visually ImpairedDocument7 pagesTactile Communication Design For Visually ImpairedFaiqa NaeemNo ratings yet
- ICT Technologies To Carter To Needs of Children With Special NeedsDocument37 pagesICT Technologies To Carter To Needs of Children With Special NeedsSaba MominNo ratings yet
- Sense of Sight: Visual Impairment Is A Term Used To Describe Any Kind of VisionDocument5 pagesSense of Sight: Visual Impairment Is A Term Used To Describe Any Kind of VisionS NandaNo ratings yet
- Braille Patterns: Range: 2800-28FFDocument5 pagesBraille Patterns: Range: 2800-28FForlandoNo ratings yet
- SpedDocument6 pagesSpedMARICRIS LLANONo ratings yet
- Dr. Hussain - Teaching Learners Blind and Visual ImpairmentDocument46 pagesDr. Hussain - Teaching Learners Blind and Visual ImpairmentAnonymous okusLzNo ratings yet
- Barrier Free Environment: SignagesDocument30 pagesBarrier Free Environment: SignagesharshalNo ratings yet