You might also like
- Procedures For Developing and Validation of Achievement TestDocument3 pagesProcedures For Developing and Validation of Achievement TesterutujirogoodluckNo ratings yet
- ISTQB Certified Tester Advanced Level Test Manager (CTAL-TM): Practice Questions Syllabus 2012From EverandISTQB Certified Tester Advanced Level Test Manager (CTAL-TM): Practice Questions Syllabus 2012No ratings yet
- Methods For Setting Cut Scors in Criterion-Referenced InstrumentsDocument170 pagesMethods For Setting Cut Scors in Criterion-Referenced InstrumentsANKUR BARUANo ratings yet
- Stages of Test DevelopmentDocument15 pagesStages of Test DevelopmentMohammad Asgar Mangulamas Guialil0% (2)
- Chalhoub-Deville 2000 What To Look For in ESL Admission Tests Cambridge Certificate Exams, IELTS, Nad TOEFLDocument17 pagesChalhoub-Deville 2000 What To Look For in ESL Admission Tests Cambridge Certificate Exams, IELTS, Nad TOEFLjin zhuoNo ratings yet
- MA Proposal in Applied Linguistics on Error Analysis Research Using English Proficiency TestDocument32 pagesMA Proposal in Applied Linguistics on Error Analysis Research Using English Proficiency Testمحمد سعدNo ratings yet
- Question Paper Production Process PDFDocument4 pagesQuestion Paper Production Process PDFFie ZainNo ratings yet
- ELA Mt3Document17 pagesELA Mt3Fadhlur RahmanNo ratings yet
- What To Look For in ESL Admission Tests Cambridge Certificate Exams IELTS and TOEFLDocument17 pagesWhat To Look For in ESL Admission Tests Cambridge Certificate Exams IELTS and TOEFLVeronica ChanNo ratings yet
- Driven To Distraction AS1.10 Practice Assessment Ver2 PDFDocument13 pagesDriven To Distraction AS1.10 Practice Assessment Ver2 PDFRup SamNo ratings yet
- Running Head: Evaluation of Technical Quality 1Document7 pagesRunning Head: Evaluation of Technical Quality 1Okoth OluochNo ratings yet
- Unit Guide: Mat102 Statistics For Business Trimester 3 2021Document12 pagesUnit Guide: Mat102 Statistics For Business Trimester 3 2021JeremyNo ratings yet
- ETA CPP Study GuideDocument64 pagesETA CPP Study Guidesoothsayer144100% (1)
- Test Review SampleDocument7 pagesTest Review SampleÖmer TezerNo ratings yet
- Standardized TestingDocument34 pagesStandardized TestingHanna FairussaniaNo ratings yet
- Frequently Asked Questions Equating of Scores On Multiple FormsDocument6 pagesFrequently Asked Questions Equating of Scores On Multiple FormsDeveshKumarNo ratings yet
- Research Assignment (Term-1-2021-22)Document5 pagesResearch Assignment (Term-1-2021-22)Nowrin IslamNo ratings yet
- Criterion-Referenced Test (CRT) and Norm-Referenced Test (NRT)Document13 pagesCriterion-Referenced Test (CRT) and Norm-Referenced Test (NRT)Uday Kumar100% (1)
- Technical Report CH 10Document58 pagesTechnical Report CH 10lunoripNo ratings yet
- GAT Guide: Test OverviewDocument6 pagesGAT Guide: Test OverviewMujeeb RehmanNo ratings yet
- Student Unit Assessment - ICTPRG501 - Apply Advanced Object-Oriented Language Skills - VersionDocument55 pagesStudent Unit Assessment - ICTPRG501 - Apply Advanced Object-Oriented Language Skills - VersionManawNo ratings yet
- PTE (Pearson Test of English) : Mehr Chand Polytechnic College (MCPC)Document5 pagesPTE (Pearson Test of English) : Mehr Chand Polytechnic College (MCPC)Kunal AroraNo ratings yet
- Standardized TestDocument20 pagesStandardized Testveronica magayNo ratings yet
- 11 Scoring MethodDocument26 pages11 Scoring MethodhmdniltfiNo ratings yet
- The Testing ProgramRUBY C. BAGON MAED EMDocument11 pagesThe Testing ProgramRUBY C. BAGON MAED EMFloreza Mae MengulloNo ratings yet
- Group 3 (Standardized Testing)Document16 pagesGroup 3 (Standardized Testing)Aufal MaramNo ratings yet
- "Development of Large Scale Student Assessment Test": Chapter 13)Document24 pages"Development of Large Scale Student Assessment Test": Chapter 13)Brittaney BatoNo ratings yet
- GAT2Document6 pagesGAT2tgokulprasad3656No ratings yet
- Steps in Developing English TestDocument1 pageSteps in Developing English TestSintaliaNo ratings yet
- Items PapersDocument8 pagesItems PapersMarissa FedereNo ratings yet
- Expressive One Word Vocabulary Test ReviewDocument4 pagesExpressive One Word Vocabulary Test Reviewemmpeethree100% (1)
- Ilm - Module 5 - Organization and Interpretation of Test DataDocument34 pagesIlm - Module 5 - Organization and Interpretation of Test DataWayne LipataNo ratings yet
- Quantitative 2Document6 pagesQuantitative 2Arba AfdzalNo ratings yet
- Episode8 170202092249Document16 pagesEpisode8 170202092249Jan-Jan A. ValidorNo ratings yet
- General Steps of Test Construction in Psychological TestingDocument13 pagesGeneral Steps of Test Construction in Psychological Testingkamil sheikhNo ratings yet
- Development of Mathematics Diagnostic TestsDocument24 pagesDevelopment of Mathematics Diagnostic TestskaskaraitNo ratings yet
- Pub13 Barchino2011 EngineeringEducation AssessmentDesignDocument7 pagesPub13 Barchino2011 EngineeringEducation AssessmentDesignostojic007No ratings yet
- International Gcse (9 - 1) Pearson Edexcel: Information and TechnologyDocument43 pagesInternational Gcse (9 - 1) Pearson Edexcel: Information and TechnologyMansur MansurNo ratings yet
- Section 1: Description of The ProjectDocument3 pagesSection 1: Description of The ProjectEljohn Louie A. ComidoyNo ratings yet
- BSBMGT608 Assessment Manual V5.0-2Document13 pagesBSBMGT608 Assessment Manual V5.0-2Cindy HuangNo ratings yet
- Mat102 - Statistics For Business - S1-2022-2023Document14 pagesMat102 - Statistics For Business - S1-2022-2023Anh Tran HoangNo ratings yet
- Empirical InvestigationDocument31 pagesEmpirical Investigationhantamu esubalewNo ratings yet
- Chapter No 4 5 8Document16 pagesChapter No 4 5 8Syeda Naz Ish NaqviNo ratings yet
- Group 3 La Fix Pake BangetDocument34 pagesGroup 3 La Fix Pake BangetHanna FairussaniaNo ratings yet
- Student Unit Assessment - ICTPRG503Document53 pagesStudent Unit Assessment - ICTPRG503ManawNo ratings yet
- Fluidized Beds TechnicalDocument20 pagesFluidized Beds TechnicalManu KumarNo ratings yet
- Student Unit Assessment - ICTPRG501 - Apply Advanced Object-Oriented Language Skills - VersionDocument53 pagesStudent Unit Assessment - ICTPRG501 - Apply Advanced Object-Oriented Language Skills - VersionManawNo ratings yet
- Subject:Theories of Test Development: Final Term ExaminationDocument9 pagesSubject:Theories of Test Development: Final Term ExaminationShoaib GondalNo ratings yet
- Project Chapter 1Document4 pagesProject Chapter 1raheemahmad276No ratings yet
- Development of Large-Scale Student Assessment TestDocument14 pagesDevelopment of Large-Scale Student Assessment TestElla MaglunobNo ratings yet
- Validity and Reliability of Classroom TestDocument32 pagesValidity and Reliability of Classroom TestDeAnneZapanta0% (1)
- Analysis of Grammar Test-Langguage AssessmentDocument24 pagesAnalysis of Grammar Test-Langguage AssessmentIndriRBNo ratings yet
- Scoring and Interpreting The Test ScoreDocument10 pagesScoring and Interpreting The Test ScoreEka FitrianaNo ratings yet
- Q2 GPT3 Research Instrument Data Gathering Methods and Data AnalysisDocument15 pagesQ2 GPT3 Research Instrument Data Gathering Methods and Data AnalysisChlzy ArdienteNo ratings yet
- Comparing Paper and Pencil Tests (PPT) with Computer Based Tests (CBTDocument8 pagesComparing Paper and Pencil Tests (PPT) with Computer Based Tests (CBTKrizna Dingding Dotillos100% (2)
- 31725H Unit6 Pef20200318Document25 pages31725H Unit6 Pef20200318hello1737828No ratings yet
- BSC Final Year Project-Teachers CBT Testing Centre ApplicationDocument128 pagesBSC Final Year Project-Teachers CBT Testing Centre ApplicationRennie Ramlochan100% (1)
- Command Words GuidelinesDocument25 pagesCommand Words Guidelinesആദിത്യ ആകാശ്No ratings yet
- CISA EXAM-Testing Concept-Knowledge of Compliance & Substantive Testing AspectsFrom EverandCISA EXAM-Testing Concept-Knowledge of Compliance & Substantive Testing AspectsRating: 3 out of 5 stars3/5 (4)
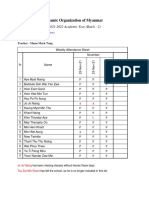
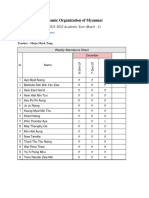
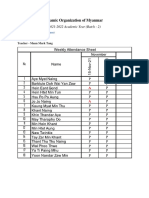
- Section 4 English Class - Attendance Report 8th WeekDocument1 pageSection 4 English Class - Attendance Report 8th WeekLaw NaungNo ratings yet
- Section 4 English Class - Attendance Report 10th WeekDocument1 pageSection 4 English Class - Attendance Report 10th WeekLaw NaungNo ratings yet
- Section 4 English Class - Attendance Report 10th WeekDocument1 pageSection 4 English Class - Attendance Report 10th WeekLaw NaungNo ratings yet
- Month Week Date Lesson Periods/Remarks: SeptemberDocument2 pagesMonth Week Date Lesson Periods/Remarks: SeptemberLaw NaungNo ratings yet
- Section 4 English Class - Attendance Report 7th WeekDocument1 pageSection 4 English Class - Attendance Report 7th WeekLaw NaungNo ratings yet
- Section 4 English Class - Attendance Report 4th WeekDocument1 pageSection 4 English Class - Attendance Report 4th WeekLaw NaungNo ratings yet
- Section 4 English Class - Attendance Report 1st WeekDocument1 pageSection 4 English Class - Attendance Report 1st WeekLaw NaungNo ratings yet
- Section 4 English Class - Attendance Report 3rd WeekDocument1 pageSection 4 English Class - Attendance Report 3rd WeekLaw NaungNo ratings yet
- Section 4 English Class - Attendance Report 5th WeekDocument1 pageSection 4 English Class - Attendance Report 5th WeekLaw NaungNo ratings yet
- Section 4 English Class - Attendance Report 4th WeekDocument1 pageSection 4 English Class - Attendance Report 4th WeekLaw NaungNo ratings yet
- Year 4 - Christmas Eve & The Two ClausesDocument6 pagesYear 4 - Christmas Eve & The Two ClausesLaw NaungNo ratings yet
- Section 4 English Class - Attendance Report 10th WeekDocument1 pageSection 4 English Class - Attendance Report 10th WeekLaw NaungNo ratings yet
- English TensesDocument9 pagesEnglish TensesLaw NaungNo ratings yet
- Section 4 English Class - Attendance Report 2nd WeekDocument1 pageSection 4 English Class - Attendance Report 2nd WeekLaw NaungNo ratings yet
- Modal Verbs May, Might, Will ExplainedDocument4 pagesModal Verbs May, Might, Will ExplainedLaw NaungNo ratings yet
- Phonetic Symbols - Mark TangDocument18 pagesPhonetic Symbols - Mark TangLaw NaungNo ratings yet
- FP PDFDocument13 pagesFP PDFjagjitsinghNo ratings yet
- Modal VerbsDocument14 pagesModal VerbsLaw NaungNo ratings yet
- Ielts ListeningDocument6 pagesIelts ListeningLaw NaungNo ratings yet
- Weekly Schedule: Monday Tuesday Wednesday Thursday Friday Saturday SundayDocument1 pageWeekly Schedule: Monday Tuesday Wednesday Thursday Friday Saturday SundayLaw NaungNo ratings yet
- THE Nine Parts OF Speech: Tr. Mann Mark TangDocument19 pagesTHE Nine Parts OF Speech: Tr. Mann Mark TangLaw NaungNo ratings yet
- 4000 IELTS Academic Words List (1) : AbandonDocument30 pages4000 IELTS Academic Words List (1) : AbandonVijay RaghavanNo ratings yet
- IELTS Speaking: Tr. Mann Mark TangDocument9 pagesIELTS Speaking: Tr. Mann Mark TangLaw NaungNo ratings yet
- Make Education Matter Pre-intermediate ClassDocument1 pageMake Education Matter Pre-intermediate ClassLaw NaungNo ratings yet
- 4000 IELTS Academic Words ListDocument41 pages4000 IELTS Academic Words ListEbook 1No ratings yet
- 500 IELTS Vocabulary 3Document15 pages500 IELTS Vocabulary 3lilyNo ratings yet
- MEM - Preintermediate Batch 31Document1 pageMEM - Preintermediate Batch 31Law NaungNo ratings yet
- 500 IELTS Vocabulary 2: ConceptDocument15 pages500 IELTS Vocabulary 2: ConceptHaiNo ratings yet
- SPSSDocument46 pagesSPSSDeepika VijayakumarNo ratings yet
- Project On Statistical Methods For Decision Making: by Ameya UdapureDocument32 pagesProject On Statistical Methods For Decision Making: by Ameya UdapureAmey UdapureNo ratings yet
- Chapter 3Document3 pagesChapter 3DevlinKeyNo ratings yet
- Group 1 Research Paper FinalDocument19 pagesGroup 1 Research Paper FinalAndrea Gwyneth Vinoya100% (1)
- Parental Attachment & Academic AchievementDocument26 pagesParental Attachment & Academic AchievementTrizie PerezNo ratings yet
- Datainbrief TemplateDocument3 pagesDatainbrief TemplateKhalis MahmudahNo ratings yet
- Online Learning's Impact on Developing Entrepreneurial SkillsDocument110 pagesOnline Learning's Impact on Developing Entrepreneurial SkillsYheneth PoquitaNo ratings yet
- Presentation On Snowball SamplingDocument7 pagesPresentation On Snowball Samplingmandefu chanshi100% (1)
- Research Learning StylesDocument21 pagesResearch Learning Stylesanon_843340593100% (1)
- 10.4324 9781315626932 PreviewpdfDocument86 pages10.4324 9781315626932 PreviewpdfantgalwayNo ratings yet
- Chapter 1Document7 pagesChapter 1phingoctuNo ratings yet
- Hollifield 10 Worst Performing Alarm System in IndustryDocument15 pagesHollifield 10 Worst Performing Alarm System in IndustryGirish JhaNo ratings yet
- Module 5 ResearchDocument7 pagesModule 5 ResearchKJ JonesNo ratings yet
- Sure440 Lect NotesDocument102 pagesSure440 Lect NotesDeniz BaşarNo ratings yet
- Proposal - GROUP 2Document10 pagesProposal - GROUP 2Nash CasunggayNo ratings yet
- Introduction To Mass Media ResearchDocument13 pagesIntroduction To Mass Media ResearchfelixNo ratings yet
- Pump MixerDocument31 pagesPump MixerPrashant MalveNo ratings yet
- A Study On Performance Appraisal System in Stanley Material and Metallurgical Pipe and Tube Manufacturing Industry at CoimbatoreDocument36 pagesA Study On Performance Appraisal System in Stanley Material and Metallurgical Pipe and Tube Manufacturing Industry at Coimbatorek eswariNo ratings yet
- Impact of Hard TQM Practices on Manufacturing PerformanceDocument33 pagesImpact of Hard TQM Practices on Manufacturing PerformanceEka Panji SaptaprasetyaNo ratings yet
- Chloropleth 2Document2 pagesChloropleth 2Aditya R. AchitoNo ratings yet
- Archaeology Dissertation ExamplesDocument5 pagesArchaeology Dissertation ExamplesBuyALiteratureReviewPaperCanada100% (1)
- Management Micro ProjectDocument15 pagesManagement Micro ProjectRutuja Pote100% (1)
- History IA Guide SectionDocument5 pagesHistory IA Guide SectionHex MARTINEZNo ratings yet
- Action Plan RubricsDocument5 pagesAction Plan RubricsJuan ObiernaNo ratings yet
- STA 2101 Assignment 1 ReviewDocument8 pagesSTA 2101 Assignment 1 ReviewdflamsheepsNo ratings yet
- Amul ChocolateDocument55 pagesAmul Chocolateashish100% (1)
- PSY 313 - 4781 - Agbayani and Sotto - Outline 1 EDITEDDocument32 pagesPSY 313 - 4781 - Agbayani and Sotto - Outline 1 EDITEDJey Vee SottoNo ratings yet
- Journal 4 - Management of Logistics AlbaniaDocument7 pagesJournal 4 - Management of Logistics AlbaniaRuhul HilyatiNo ratings yet
- The 7 Phases of Community ImmersionDocument9 pagesThe 7 Phases of Community ImmersionNobody but youNo ratings yet
- Scheme of Work Mkt646Document5 pagesScheme of Work Mkt646Micheal PruittNo ratings yet