You might also like
- Pattern Recognition Letters: C. Ferri, J. Hernández-Orallo, R. ModroiuDocument12 pagesPattern Recognition Letters: C. Ferri, J. Hernández-Orallo, R. ModroiuRaja Muhammad BasharatNo ratings yet
- Evaluation of Performance Measures For Classifiers ComparisonDocument14 pagesEvaluation of Performance Measures For Classifiers ComparisonUbiquitous Computing and Communication JournalNo ratings yet
- An experimental comparison of 18 classification performance measuresDocument12 pagesAn experimental comparison of 18 classification performance measuresdominic2299No ratings yet
- Factor Analysis Is An Interdependence Technique Whose Primary Purpose Is To Define The UnderlyingDocument3 pagesFactor Analysis Is An Interdependence Technique Whose Primary Purpose Is To Define The UnderlyingRema VanchhawngNo ratings yet
- Selecting The Right Objective Measure For Association AnalysisDocument21 pagesSelecting The Right Objective Measure For Association AnalysisAnonymous RrGVQjNo ratings yet
- Multivariate AnalysisDocument11 pagesMultivariate AnalysisCerlin PajilaNo ratings yet
- Evolution Strategies for Vector Optimization ProblemsDocument5 pagesEvolution Strategies for Vector Optimization ProblemsTao TaoNo ratings yet
- Creswell Et Al 2018Document9 pagesCreswell Et Al 2018moramaireNo ratings yet
- Assessing Unidimensionality: A Comparison of Rasch Modeling, Parallel Analysis, and TETRADDocument19 pagesAssessing Unidimensionality: A Comparison of Rasch Modeling, Parallel Analysis, and TETRADRina Dewi SetyowatiNo ratings yet
- Thomas L. SaatyDocument18 pagesThomas L. SaatyliafaurNo ratings yet
- 1987-Fuzzy Algorithm For Decision Making in Mining EngineeringDocument6 pages1987-Fuzzy Algorithm For Decision Making in Mining EngineeringmspleitNo ratings yet
- The Rise of India and China: Comparative Perspectives Assignment-CP EssayDocument5 pagesThe Rise of India and China: Comparative Perspectives Assignment-CP EssayYeswanth LVSNo ratings yet
- Dwnload Full Statistics For The Behavioral Sciences 10th Edition Gravetter Solutions Manual PDFDocument35 pagesDwnload Full Statistics For The Behavioral Sciences 10th Edition Gravetter Solutions Manual PDFmasonh7dswebb100% (12)
- 1 s2.0 0270025587904738 Main PDFDocument16 pages1 s2.0 0270025587904738 Main PDFBenjamin NaulaNo ratings yet
- Choosing Bankruptcy Predictors Using Discriminant Analysis, Logit Analysis, and Genetic AlgorithmsDocument20 pagesChoosing Bankruptcy Predictors Using Discriminant Analysis, Logit Analysis, and Genetic AlgorithmsŁukasz KarczewskiNo ratings yet
- Research Quality & ContentDocument7 pagesResearch Quality & Contentjohnalis22No ratings yet
- Lesson Plans in Urdu SubjectDocument10 pagesLesson Plans in Urdu SubjectNoor Ul AinNo ratings yet
- Col LinearityDocument14 pagesCol LinearityYosytha ParissingNo ratings yet
- 03-4-Manual For PVQDocument6 pages03-4-Manual For PVQyekbarmasrafNo ratings yet
- SEM Vs M RegressionDocument4 pagesSEM Vs M RegressionRISTAARISRIYANTONo ratings yet
- A Confirmatory Factor Analysis of The End-User Computing Satisfaction InstrumentDocument10 pagesA Confirmatory Factor Analysis of The End-User Computing Satisfaction InstrumentAbhishek Narain SinghNo ratings yet
- Weighted Mean Formula Used in ThesisDocument5 pagesWeighted Mean Formula Used in ThesisWendy Berg100% (2)
- Logico-Ontological Framework Validates Research MethodsDocument17 pagesLogico-Ontological Framework Validates Research Methodsyashashree barhateNo ratings yet
- Determining Appropriate Sample Size in Survey ResearchDocument8 pagesDetermining Appropriate Sample Size in Survey ResearchshkadryNo ratings yet
- Propensity Score Matching With SPSSDocument30 pagesPropensity Score Matching With SPSSPablo Sebastian GómezNo ratings yet
- Characteristics of SEM: Cov R SD SDDocument9 pagesCharacteristics of SEM: Cov R SD SDHans JonniNo ratings yet
- MCDM SensitivityAnalysis by Triantaphyllou1Document51 pagesMCDM SensitivityAnalysis by Triantaphyllou1shilpi0208No ratings yet
- Mislevy 1986Document30 pagesMislevy 1986Bulan BulawanNo ratings yet
- Criteria in AHP: A Systematic Review of Literature: Procedia Computer Science July 2015Document11 pagesCriteria in AHP: A Systematic Review of Literature: Procedia Computer Science July 2015Dubravka UžarNo ratings yet
- Theories Related To Tests and Measurement FinalDocument24 pagesTheories Related To Tests and Measurement FinalMargaret KimaniNo ratings yet
- Statistics For The Behavioral Sciences 10th Edition Gravetter Solutions ManualDocument13 pagesStatistics For The Behavioral Sciences 10th Edition Gravetter Solutions Manualjerryperezaxkfsjizmc100% (15)
- Discrete Choice Experiments Are Not Conjoint Analysis: Jordan J Louviere Terry N Flynn Richard T CarsonDocument16 pagesDiscrete Choice Experiments Are Not Conjoint Analysis: Jordan J Louviere Terry N Flynn Richard T CarsonYaronBabaNo ratings yet
- Psychology Research Paper Using AnovaDocument8 pagesPsychology Research Paper Using Anovaafnkhujzxbfnls100% (1)
- Item Parceling Strategies in SEM: Investigating The Subtle Effects of Unmodeled Secondary ConstructsDocument24 pagesItem Parceling Strategies in SEM: Investigating The Subtle Effects of Unmodeled Secondary ConstructsnalakacwNo ratings yet
- Correlation and ANOVA TechniquesDocument6 pagesCorrelation and ANOVA TechniquesHans Christer RiveraNo ratings yet
- BRM Unit 4 ExtraDocument10 pagesBRM Unit 4 Extraprem nathNo ratings yet
- Cluster Cat VarsDocument17 pagesCluster Cat Varsfab101No ratings yet
- Aspects of Multivariate AnalysisDocument4 pagesAspects of Multivariate AnalysisMarcos SilvaNo ratings yet
- Ahp Mathematical ModelsDocument10 pagesAhp Mathematical ModelsMuhammad Adeel AhsenNo ratings yet
- 10.2307@20152659 r2 - ShrinkageDocument23 pages10.2307@20152659 r2 - ShrinkagelimfoohoatNo ratings yet
- Abadie Et Al 2015Document16 pagesAbadie Et Al 2015Fausto BonavíaNo ratings yet
- Decision MakingDocument6 pagesDecision Makingshahriar firouzabadiNo ratings yet
- Conducting and Interpreting Canonical Correlation Analysis in Personality ResearchDocument13 pagesConducting and Interpreting Canonical Correlation Analysis in Personality ResearchElder SobrinhoNo ratings yet
- The Role of Factor Analysis in The DevelDocument44 pagesThe Role of Factor Analysis in The DevelSNo ratings yet
- Classifier Consensus Approach Improves Credit Scoring AccuracyDocument21 pagesClassifier Consensus Approach Improves Credit Scoring AccuracyEkoume Serges-ArmelNo ratings yet
- Factor Analysis of Adolescent Coping StrategiesDocument7 pagesFactor Analysis of Adolescent Coping StrategiesKhan SahabNo ratings yet
- Shanock Et Al., 2010Document12 pagesShanock Et Al., 2010Shuxian ZhangNo ratings yet
- Carson Becker Henderson 1998Document13 pagesCarson Becker Henderson 1998Nguyen Hoang Minh QuocNo ratings yet
- The Seven Pillars of The Analytic Hierarchy ProcesDocument16 pagesThe Seven Pillars of The Analytic Hierarchy ProcesDaniel FerrentinoNo ratings yet
- Illustrations From The Field of FinanceDocument19 pagesIllustrations From The Field of FinancePradipta BoraNo ratings yet
- Evaluation of Mathematics Achievement Test: A Comparison Between CTT and IRTDocument8 pagesEvaluation of Mathematics Achievement Test: A Comparison Between CTT and IRTFlorence AmarilleNo ratings yet
- Biostatistics and Computer-based Analysis of Health Data using StataFrom EverandBiostatistics and Computer-based Analysis of Health Data using StataNo ratings yet
- Decision MakingDocument6 pagesDecision Makingshahriar firouzabadiNo ratings yet
- Introduction To Rec Om Mender Systems, Algorithms and EvaluationDocument4 pagesIntroduction To Rec Om Mender Systems, Algorithms and EvaluationddeepakkumarNo ratings yet
- An Alternative Solution To The Analytic Hierarchy Process: Maria Teresa LamataDocument17 pagesAn Alternative Solution To The Analytic Hierarchy Process: Maria Teresa LamataGopala KrishnanNo ratings yet
- Understanding Variables in StatisticsDocument23 pagesUnderstanding Variables in StatisticsAme DamneeNo ratings yet
- Thesis On Scale DevelopmentDocument6 pagesThesis On Scale Developmentbsfp46eh100% (1)
- Examination of Data - WMSTDocument39 pagesExamination of Data - WMSTChetna RajNo ratings yet
- Kulynycz Drilling 3 20171Document12 pagesKulynycz Drilling 3 20171abebotalardyNo ratings yet
- Topej 12 1Document12 pagesTopej 12 1abebotalardyNo ratings yet
- Diversity Versus Multiplexing in Narrowband MIMO Channels: A Tradeoff Based On Euclidean DistanceDocument26 pagesDiversity Versus Multiplexing in Narrowband MIMO Channels: A Tradeoff Based On Euclidean DistanceabebotalardyNo ratings yet
- Garmin - What Is GPSDocument3 pagesGarmin - What Is GPSabebotalardyNo ratings yet
- Plane Table SurveyDocument48 pagesPlane Table SurveyabebotalardyNo ratings yet
- Drobne (2009) Analisis Multicriterio PDFDocument16 pagesDrobne (2009) Analisis Multicriterio PDFyeskandinoNo ratings yet
- What Is GISDocument2 pagesWhat Is GISabebotalardyNo ratings yet
- Block Plan Meters-ModelDocument11 pagesBlock Plan Meters-ModelIsaac Ekow MensahNo ratings yet
- AHPapls 1Document11 pagesAHPapls 1Raghu Vamsi PotukuchiNo ratings yet
- Matrix Products - CH - 5Document17 pagesMatrix Products - CH - 5abebotalardyNo ratings yet
- I.msstate - Edu - Publications - Docs - 2009 - 05 - 5939MCDM1 - Undestanding AHPDocument37 pagesI.msstate - Edu - Publications - Docs - 2009 - 05 - 5939MCDM1 - Undestanding AHPabebotalardyNo ratings yet
- Catchment Area Delineation Using GISDocument18 pagesCatchment Area Delineation Using GISashe zinabNo ratings yet
- Papers Vol 1 Issue 1 F011040051Document12 pagesPapers Vol 1 Issue 1 F011040051abebotalardyNo ratings yet
- Multi-Criteria Clinical Decision Support - A Primer On The Use of Multiple Criteria Decision Making Methods To Promote Evidence-Based, Patient-Centered HealthcareDocument17 pagesMulti-Criteria Clinical Decision Support - A Primer On The Use of Multiple Criteria Decision Making Methods To Promote Evidence-Based, Patient-Centered HealthcareabebotalardyNo ratings yet
- Water-03-00254-V2 ..USE THISDocument37 pagesWater-03-00254-V2 ..USE THISabebotalardyNo ratings yet
- Iajit PDF Vol.2, No.2 10-ElderandelyDocument6 pagesIajit PDF Vol.2, No.2 10-ElderandelyabebotalardyNo ratings yet
- 7801 9864 1 PBDocument18 pages7801 9864 1 PBabebotalardyNo ratings yet
- Textual Sermons by Mark A. CopelandDocument191 pagesTextual Sermons by Mark A. CopelandSerNo ratings yet
- Etd - Uovs.ac - Za ETD-db Theses Available Etd-07292008-094719 Unrestricted ThosoM... GOODDocument83 pagesEtd - Uovs.ac - Za ETD-db Theses Available Etd-07292008-094719 Unrestricted ThosoM... GOODabebotalardyNo ratings yet
- Introduction To Well Completion: (Part - IV)Document36 pagesIntroduction To Well Completion: (Part - IV)Mohamed MahmoudNo ratings yet
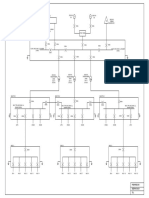
- Conceptual SLDDocument1 pageConceptual SLDakhilNo ratings yet
- DR 38312-011Document33 pagesDR 38312-011Julio Csar da SilvaNo ratings yet
- Official All Things Turmeric PPT GuidebookDocument14 pagesOfficial All Things Turmeric PPT Guidebookapi-507527047No ratings yet
- Methyl methacrylate allergy case study in dentistry studentDocument3 pagesMethyl methacrylate allergy case study in dentistry studentDaniela CapitanuNo ratings yet
- For Student-General Chemistry I - Module 6 - Phan Tai HuanDocument41 pagesFor Student-General Chemistry I - Module 6 - Phan Tai HuanEsat Goceri100% (1)
- Technical Plan For Roll Forming Machine: Model: WLFM40-250-1000Document5 pagesTechnical Plan For Roll Forming Machine: Model: WLFM40-250-1000ibrahimadiop1No ratings yet
- Overview of Metal Forming ProcessesDocument19 pagesOverview of Metal Forming ProcessesAnonymous 7yN43wjlNo ratings yet
- Detection Dogs Allow For Systematic Non-Invasive Collection of DNA Samples From Eurasian LynxDocument5 pagesDetection Dogs Allow For Systematic Non-Invasive Collection of DNA Samples From Eurasian Lynxsusey madelit apaza mamaniNo ratings yet
- Asme Section II A Sa-435 Sa-435mDocument4 pagesAsme Section II A Sa-435 Sa-435mAnonymous GhPzn1xNo ratings yet
- Siehl, Caitlyn-Whatweburied Digitaledition (2015)Document64 pagesSiehl, Caitlyn-Whatweburied Digitaledition (2015)Bahar Gaser100% (1)
- Cerebral PalsyDocument24 pagesCerebral PalsyUday Kumar100% (1)
- Max Out On Squats Every Day PDFDocument7 pagesMax Out On Squats Every Day PDFsamsung684No ratings yet
- EC538 LTspice IntroDocument10 pagesEC538 LTspice IntroTeferi LemmaNo ratings yet
- Series 9910 4-3/8" Sliding Glass Door (Cw30) : SectionDocument4 pagesSeries 9910 4-3/8" Sliding Glass Door (Cw30) : SectionAmro Ahmad AliNo ratings yet
- Saa6d170e-5 HPCR Egr Sen00190-04Document415 pagesSaa6d170e-5 HPCR Egr Sen00190-04Ahmad Mubarok100% (4)
- Subway's Fresh Look: CEO Suzanne Greco Is Taking The Company To A Whole New Level With The Fresh Forward RebrandDocument9 pagesSubway's Fresh Look: CEO Suzanne Greco Is Taking The Company To A Whole New Level With The Fresh Forward RebrandTanvir KhanNo ratings yet
- The Effectiveness of Food Labelling in Controlling Ones Calorie IntakeDocument33 pagesThe Effectiveness of Food Labelling in Controlling Ones Calorie IntakeKisha Ghay SudariaNo ratings yet
- Hooded Scarf Project From Warm Knits, Cool GiftsDocument4 pagesHooded Scarf Project From Warm Knits, Cool GiftsCrafterNews33% (3)
- Water Transport Studies in Stone Masonry With Soil Cement MortarDocument10 pagesWater Transport Studies in Stone Masonry With Soil Cement MortarTJPRC PublicationsNo ratings yet
- Jyotish - A Manual of Hindu Astrology - B.v.raman - 1992Document149 pagesJyotish - A Manual of Hindu Astrology - B.v.raman - 1992Ram RamNo ratings yet
- Aeroacoustic and Aerodynamic Optimization of Propeller BladesDocument14 pagesAeroacoustic and Aerodynamic Optimization of Propeller BladesWouterr GNo ratings yet
- 2021 SC Hurricane GuideDocument16 pages2021 SC Hurricane GuideWMBF News100% (1)
- DPS Nashik Class 12 Science SyllabusDocument18 pagesDPS Nashik Class 12 Science SyllabusSayali Morwal-KumawatNo ratings yet
- ICH Guidelines: Prsented By: Manish Shankarpure M.Pharm (Quality Assurances and Techniques)Document17 pagesICH Guidelines: Prsented By: Manish Shankarpure M.Pharm (Quality Assurances and Techniques)Manish shankarpureNo ratings yet
- UntitledDocument2 pagesUntitledbassky_368970698No ratings yet
- Decline of Controversy and the Catholic ChurchDocument3 pagesDecline of Controversy and the Catholic ChurchEugenio PalandriNo ratings yet
- Australian F1 SUBMACHINE GUNDocument4 pagesAustralian F1 SUBMACHINE GUNCaprikorn100% (4)
- SR-21 SniperDocument6 pagesSR-21 SniperBaba HeadquaterNo ratings yet
- CV Electrical Engineer 2.7 Yrs ExpDocument4 pagesCV Electrical Engineer 2.7 Yrs ExpShams Tabrez0% (1)