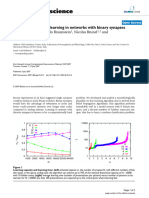
You might also like
- IV Memory: 4.1 Nature and DefinitionDocument6 pagesIV Memory: 4.1 Nature and DefinitionAbel AmareNo ratings yet
- Chapter 4 Memory & LearningDocument32 pagesChapter 4 Memory & Learninghvactrg1100% (1)
- Optimization of Welding Process ParameterDocument62 pagesOptimization of Welding Process ParameteraktekshareNo ratings yet
- Sentiment Analysis Using Deep LearningDocument10 pagesSentiment Analysis Using Deep LearningA PourrezaNo ratings yet
- Recursive Routing Networks: Learning To Compose Modules For Language UnderstandingDocument18 pagesRecursive Routing Networks: Learning To Compose Modules For Language UnderstandingLovedeepNo ratings yet
- A Novel Edge-Based Multi-Layer Hierarchical Architecture For Federated LearningDocument5 pagesA Novel Edge-Based Multi-Layer Hierarchical Architecture For Federated LearningAmardip Kumar SinghNo ratings yet
- Nsdi17 Alipourfard PDFDocument15 pagesNsdi17 Alipourfard PDFasNo ratings yet
- Encryption Mechanism Software Requirement Specifications Changed To Dokumentation Version 1.3.0Document13 pagesEncryption Mechanism Software Requirement Specifications Changed To Dokumentation Version 1.3.0Akshat JainNo ratings yet
- Fully Convolutional Networks For Semantic Segmentation: Jonathan Long Evan Shelhamer Trevor Darrell UC BerkeleyDocument10 pagesFully Convolutional Networks For Semantic Segmentation: Jonathan Long Evan Shelhamer Trevor Darrell UC BerkeleyUnaixa KhanNo ratings yet
- Poria 2017Document6 pagesPoria 20172K20 B3 11 Arun KumarNo ratings yet
- Consumer Behavior PP Chapter 4Document36 pagesConsumer Behavior PP Chapter 4tuongvyvyNo ratings yet
- Advanced Database SystemDocument54 pagesAdvanced Database Systemzaibakhan8No ratings yet
- Psychology JoDocument13 pagesPsychology JoteddyNo ratings yet
- Multimodal Deep Learning: Seminar Report OnDocument34 pagesMultimodal Deep Learning: Seminar Report OnRaj JhaNo ratings yet
- Gradient Starvation - A Learning Proclivity in Neural NetworksDocument26 pagesGradient Starvation - A Learning Proclivity in Neural Networkstimsmith1081574No ratings yet
- Human-Centered Design: Human Factors Within Interactive Digital Media Design & SoftwareDocument41 pagesHuman-Centered Design: Human Factors Within Interactive Digital Media Design & SoftwareNick ClarkeNo ratings yet
- Deep Leakage From GradientsDocument11 pagesDeep Leakage From Gradientsli zihaoNo ratings yet
- BMC Neuroscience: Efficient Supervised Learning in Networks With Binary SynapsesDocument2 pagesBMC Neuroscience: Efficient Supervised Learning in Networks With Binary Synapsesvehaxo6855No ratings yet
- CicarellimemoryDocument17 pagesCicarellimemoryMishikaNo ratings yet
- Applied Cognitive Informatics and Cognitive Computing On Data ManagementDocument2 pagesApplied Cognitive Informatics and Cognitive Computing On Data ManagementMuthuram RNo ratings yet
- Module 2 Cog PsyDocument19 pagesModule 2 Cog PsyDaphneNo ratings yet
- Zhou Conditional Prompt Learning For Vision-Language Models CVPR 2022 PaperDocument10 pagesZhou Conditional Prompt Learning For Vision-Language Models CVPR 2022 PaperreghecampflucaNo ratings yet
- Seminar - Report Iit BmbayDocument42 pagesSeminar - Report Iit Bmbayakshat sharmaNo ratings yet
- Feed Forward Neural Networks: Supervised Learning - IDocument30 pagesFeed Forward Neural Networks: Supervised Learning - IindiraNo ratings yet
- FileIO in O/SDocument28 pagesFileIO in O/Snofiya yousufNo ratings yet
- 04-2022 WIFS Y BelousovDocument6 pages04-2022 WIFS Y BelousovRémi CogranneNo ratings yet
- Human Computer InteractionDocument4 pagesHuman Computer InteractionMNaveedsdkNo ratings yet
- 2015 Lecun DeeplearnDocument10 pages2015 Lecun Deeplearncs888dnNo ratings yet
- Lin Hierarchy CACMDocument9 pagesLin Hierarchy CACMJosé Damián López DíazNo ratings yet
- A Deep Neural Network-Based Approach For Sentiment Analysis of Movie ReviewsDocument9 pagesA Deep Neural Network-Based Approach For Sentiment Analysis of Movie ReviewsSaad TayefNo ratings yet
- IT0005-Laboratory-Exercise-6 - Backup Data To External StorageDocument4 pagesIT0005-Laboratory-Exercise-6 - Backup Data To External StorageRhea KimNo ratings yet
- Towards An Episodic Memory For Companion DialogueDocument7 pagesTowards An Episodic Memory For Companion DialogueRandom UserNo ratings yet
- Module 1 - Bio SyllabusDocument12 pagesModule 1 - Bio SyllabusChamsNo ratings yet
- AlgorithmDocument17 pagesAlgorithmMahamad AliNo ratings yet
- A Study On Associative Neural MemoriesDocument10 pagesA Study On Associative Neural MemoriesEditor IJACSANo ratings yet
- Publi 6615Document5 pagesPubli 6615Bhargav ChiruNo ratings yet
- Introduction To Java LanguageDocument2 pagesIntroduction To Java LanguagerajuNo ratings yet
- Introduction To Machine Learning: February 2010Document9 pagesIntroduction To Machine Learning: February 2010Ermias MesfinNo ratings yet
- An Efficient Presentation-Architecture For Personalized ContentDocument10 pagesAn Efficient Presentation-Architecture For Personalized ContentCarsten UllrichNo ratings yet
- Part One The Nature of Approaches and MethodsDocument1 pagePart One The Nature of Approaches and Methodsbertaniamine7No ratings yet
- Aangan by Khadija Mastoor PDFDocument29 pagesAangan by Khadija Mastoor PDFAnam QureshiNo ratings yet
- The 6 Science Process SkillsDocument1 pageThe 6 Science Process SkillsCarl JesterNo ratings yet
- Sentimental Analysis of Product Review Data Using Deep LearningDocument5 pagesSentimental Analysis of Product Review Data Using Deep LearningIJRASETPublicationsNo ratings yet
- Abhijit Ghatak - Deep Learning With R-Springer (2019)Document259 pagesAbhijit Ghatak - Deep Learning With R-Springer (2019)JLALNo ratings yet
- The Role of Memory in Learning: How Important IsDocument8 pagesThe Role of Memory in Learning: How Important Ismousti84No ratings yet
- Lecun 2015Document10 pagesLecun 2015spanishbear75No ratings yet
- Research Paper On Memory ManagementDocument8 pagesResearch Paper On Memory Managementeghkq0wf100% (1)
- Neural TuringDocument194 pagesNeural TuringIamINNo ratings yet
- Conv TransformerDocument17 pagesConv TransformerPedro PietrafesaNo ratings yet
- C4 Memory and ForgottenDocument9 pagesC4 Memory and ForgottenHanan FuadNo ratings yet
- Smart Assistance For CampusDocument8 pagesSmart Assistance For CampusabtobikNo ratings yet
- Speech Recognition Using Deep Neural Networks: A Systematic ReviewDocument23 pagesSpeech Recognition Using Deep Neural Networks: A Systematic ReviewYashaswini U.BhatNo ratings yet
- TCY Chapter 7Document12 pagesTCY Chapter 7Tan Cheng YeeNo ratings yet
- Inform TechnologyDocument58 pagesInform TechnologyFlorentin SmarandacheNo ratings yet
- Deep-Sentiment: Sentiment Analysis Using Ensemble of CNN and Bi-LSTM ModelsDocument6 pagesDeep-Sentiment: Sentiment Analysis Using Ensemble of CNN and Bi-LSTM Modelsjon starkNo ratings yet
- BEADS Blockchain-Empowered Auction in Decentralized StorageDocument6 pagesBEADS Blockchain-Empowered Auction in Decentralized StoragexNo ratings yet
- Memcache FB PDFDocument14 pagesMemcache FB PDFnutandevjoshiNo ratings yet
- LSTM Based Music Generation System: Medi-Caps University Medi-Caps University Medi-Caps UniversityDocument6 pagesLSTM Based Music Generation System: Medi-Caps University Medi-Caps University Medi-Caps UniversityRaj DhakalNo ratings yet
- Practical Artificial Intelligence: Machine Learning, Bots, and Agent Solutions Using C#From EverandPractical Artificial Intelligence: Machine Learning, Bots, and Agent Solutions Using C#No ratings yet
- Deep Learning Pipeline: Building a Deep Learning Model with TensorFlowFrom EverandDeep Learning Pipeline: Building a Deep Learning Model with TensorFlowNo ratings yet
- 4 ECE EC 2255 Control SystemDocument2 pages4 ECE EC 2255 Control SystemBIBIN CHIDAMBARANATHANNo ratings yet
- Học viện ngân hàng Banking Academy of Vietnam International School of BusinessDocument9 pagesHọc viện ngân hàng Banking Academy of Vietnam International School of BusinessTrần XuânNo ratings yet
- Fault Detection in Wireless Sensor Network Based On Deep Learning AlgorithmsDocument8 pagesFault Detection in Wireless Sensor Network Based On Deep Learning AlgorithmsAnanthi MehaaNo ratings yet
- III Test DsaDocument50 pagesIII Test DsaRituparna Roy ChowdhuryNo ratings yet
- REC A10 - Encryption v1Document9 pagesREC A10 - Encryption v1Imam halim mursyidinNo ratings yet
- Linear Applications To Power Economics, Planning and OperationsDocument9 pagesLinear Applications To Power Economics, Planning and OperationsWang SolNo ratings yet
- Digital Signal ProcessingDocument3 pagesDigital Signal ProcessingRagahv chhabraNo ratings yet
- Stock Expected Return DailyDocument35 pagesStock Expected Return DailyJustin NguyenNo ratings yet
- 374 HW2Document2 pages374 HW2anreigioNo ratings yet
- 4 Review Response Arbitrary ExcitationDocument17 pages4 Review Response Arbitrary ExcitationTanay ChoudharyNo ratings yet
- A Hybrid Genetic Algorithm For Integrated Process Planning and Scheduling Problem With Precedence ConstraintsDocument15 pagesA Hybrid Genetic Algorithm For Integrated Process Planning and Scheduling Problem With Precedence ConstraintsJohn RichardsonNo ratings yet
- Selection ConstructDocument13 pagesSelection Constructapi-297910907No ratings yet
- W (S) V (S) : Automatic Control System Quiz (IEE-552)Document1 pageW (S) V (S) : Automatic Control System Quiz (IEE-552)Ankit SrivastavaNo ratings yet
- BSC Part 3Document29 pagesBSC Part 3Rishabh GuptaNo ratings yet
- SSL and Tls 2Document22 pagesSSL and Tls 2Anonymous L3zAMqRlzUNo ratings yet
- Tutorial 1 Report: Digital Signal Processing LabDocument13 pagesTutorial 1 Report: Digital Signal Processing LabTuấnMinhNguyễnNo ratings yet
- Neat Diophantine EquationDocument3 pagesNeat Diophantine EquationAngelAgueroNo ratings yet
- Signals and Systems - Chapter 2Document27 pagesSignals and Systems - Chapter 2altwirqiNo ratings yet
- Advanced Encryption Standard (AES) And: Finite FieldsDocument47 pagesAdvanced Encryption Standard (AES) And: Finite FieldsbhargavNo ratings yet
- MDSP 1Document48 pagesMDSP 1Soundarya SvsNo ratings yet
- A Finite Element Approach Using An Augmented Lagrangian Method To Simulate Impact Problems Under Large 3D Elastoplastic DeformationDocument9 pagesA Finite Element Approach Using An Augmented Lagrangian Method To Simulate Impact Problems Under Large 3D Elastoplastic DeformationleivajNo ratings yet
- Simulación en Multisim - Control de PosiciónDocument3 pagesSimulación en Multisim - Control de PosiciónLuis CJNo ratings yet
- Model StokastikDocument6 pagesModel StokastikMaimun RizalihadiNo ratings yet
- Aria D. HaghighiDocument1 pageAria D. Haghighiaria42No ratings yet
- 15CS73 Dec18-Jan19 PDFDocument2 pages15CS73 Dec18-Jan19 PDFPradyumna A KubearNo ratings yet
- Types of KrigingDocument9 pagesTypes of KrigingFeduz L Near100% (1)
- CS 501 TOC Student 'S Lab Manual ODD Experiment 1 & 2 (1) - 1563252281Document5 pagesCS 501 TOC Student 'S Lab Manual ODD Experiment 1 & 2 (1) - 1563252281Tanay Patil0% (1)
- AWID For IntrusionCISS2019Document6 pagesAWID For IntrusionCISS2019Quý TùngNo ratings yet
- AssignmentDocument3 pagesAssignmentAwol AbduNo ratings yet