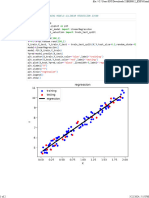
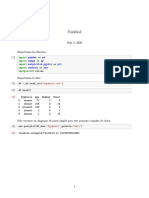
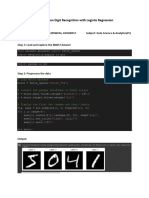
You might also like
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- Astm D 1196 PDFDocument3 pagesAstm D 1196 PDFSetyawan Chill Gates0% (1)
- Fluoride - Wide Range of Serious Health Problems"Document29 pagesFluoride - Wide Range of Serious Health Problems"zataullah100% (2)
- 03-F10 Planned Job ObservationDocument1 page03-F10 Planned Job ObservationSn Ahsan100% (1)
- What Is Denim? Why It's Called Denim?: Properties of Denim FabricDocument21 pagesWhat Is Denim? Why It's Called Denim?: Properties of Denim Fabricrahmanshanto623100% (1)
- Machine Learning Algorithms PDFDocument148 pagesMachine Learning Algorithms PDFjeff omangaNo ratings yet
- List of Modern Equipment and Farm ToolsDocument15 pagesList of Modern Equipment and Farm ToolsCarl Johnrich Quitain100% (2)
- 2011-11-09 Diana and AtenaDocument8 pages2011-11-09 Diana and AtenareluNo ratings yet
- BKNC3 - Activity 1 - Review ExamDocument3 pagesBKNC3 - Activity 1 - Review ExamDhel Cahilig0% (1)
- 19f0217 8B Assignment04Document12 pages19f0217 8B Assignment04Shahid Imran100% (1)
- ML 2.4 PrashantDocument3 pagesML 2.4 Prashantdeadm2996No ratings yet
- PS Project - Jupyter NotebookDocument6 pagesPS Project - Jupyter NotebookM. Mobeen KhattakNo ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- CV Assignment 2 Group02Document12 pagesCV Assignment 2 Group02Manash BarmanNo ratings yet
- ML Lab ProgramsDocument23 pagesML Lab ProgramsRoopa 18-19-36No ratings yet
- 2.3 Aiml RishitDocument7 pages2.3 Aiml Rishitheex.prosNo ratings yet
- ML Lab RecordDocument15 pagesML Lab Recordrr3870044No ratings yet
- ML Ex8Document2 pagesML Ex8yefigoh133No ratings yet
- Machine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionDocument22 pagesMachine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionKANTESH kantesh100% (1)
- 21bei0012 Exp10Document2 pages21bei0012 Exp10srujanNo ratings yet
- Import Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadDocument20 pagesImport Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadSaloni TuliNo ratings yet
- ML - Practical FileDocument15 pagesML - Practical FileJatin MathurNo ratings yet
- ML Lab6Document4 pagesML Lab6Pankaj MandloiNo ratings yet
- ML With Python PracticalDocument22 pagesML With Python Practicaln58648017No ratings yet
- Transfer Learning For Image Classification in PytorchDocument13 pagesTransfer Learning For Image Classification in PytorchMinusha TehaniNo ratings yet
- School of Engineering: Lab Manual On Machine Learning LabDocument23 pagesSchool of Engineering: Lab Manual On Machine Learning LabRavi KumawatNo ratings yet
- DNN ALL Practical 28Document34 pagesDNN ALL Practical 284073Himanshu PatleNo ratings yet
- SVM K NN MLP With Sklearn Jupyter NoteBoDocument22 pagesSVM K NN MLP With Sklearn Jupyter NoteBoAhm TharwatNo ratings yet
- Unit2 ML ProgramsDocument7 pagesUnit2 ML Programsdiroja5648No ratings yet
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- Plotting Decision Regions - MlxtendDocument5 pagesPlotting Decision Regions - Mlxtendakhi016733No ratings yet
- K-Nearest Neighbor On Python Ken OcumaDocument9 pagesK-Nearest Neighbor On Python Ken OcumaAliyha Dionio100% (2)
- FML File FinalDocument36 pagesFML File FinalKunal SainiNo ratings yet
- C1 W2 Lab05 Sklearn GD SolnDocument3 pagesC1 W2 Lab05 Sklearn GD SolnSrinidhi PNo ratings yet
- Bab 7Document3 pagesBab 7Hani Amany ElisadiNo ratings yet
- Lab7 Hameed 211086Document4 pagesLab7 Hameed 211086Abdul MoaidNo ratings yet
- Tugas Akhir Big DataDocument10 pagesTugas Akhir Big DataSaskya LidayaniNo ratings yet
- Pattern Recognition LabDocument24 pagesPattern Recognition LabPrashant KumarNo ratings yet
- Plotting Decision Regions - 1 - MlxtendDocument5 pagesPlotting Decision Regions - 1 - Mlxtendakhi016733No ratings yet
- Machine LearninDocument23 pagesMachine LearninManoj Kumar 1183100% (1)
- 20bce0872 VL2022230503441 Ast01 230122 204351Document10 pages20bce0872 VL2022230503441 Ast01 230122 204351Vishesh BhargavaNo ratings yet
- Week14 N9Document3 pagesWeek14 N920131A05N9 SRUTHIK THOKALANo ratings yet
- Worksheet - 2.3 20BCS7490Document6 pagesWorksheet - 2.3 20BCS7490Himanshu ThakurNo ratings yet
- ArbolesRF UNIDocument3 pagesArbolesRF UNIALISON ELIZABETH HUAPAYA CAYCHONo ratings yet
- Iva LabDocument55 pagesIva LabRAJAKARUPPAIAH SNo ratings yet
- Karmbir 19 MLDocument20 pagesKarmbir 19 MLdeepakyadavyadav987No ratings yet
- HDLR - K20SW016, K20SW002, K20SW017Document5 pagesHDLR - K20SW016, K20SW002, K20SW017Muteeb HashmiNo ratings yet
- Big Data MergedDocument7 pagesBig Data MergedIngame IdNo ratings yet
- 21BEC505 Exp2Document7 pages21BEC505 Exp2jayNo ratings yet
- Cancer Disease ClassificationDocument6 pagesCancer Disease ClassificationBARATH PNo ratings yet
- Daftar Lampiran Coding Python RecognizeDocument7 pagesDaftar Lampiran Coding Python RecognizeResha Noviane PutriNo ratings yet
- Using A Three Layer Deep Neural Network To Solve An Unsupervised Learning ProblemDocument13 pagesUsing A Three Layer Deep Neural Network To Solve An Unsupervised Learning ProblemShajon PaglaNo ratings yet
- Linear and Logistic RegressionDocument6 pagesLinear and Logistic RegressionMahevish FatimaNo ratings yet
- FML LabFile 7expsDocument37 pagesFML LabFile 7expsKunal SainiNo ratings yet
- CodesDocument6 pagesCodesVamshi KrishnaNo ratings yet
- Import As Import As Import As: # Importing The LibrariesDocument3 pagesImport As Import As Import As: # Importing The Libraries19-361 Sai PrathikNo ratings yet
- K Means AlgorithmDocument6 pagesK Means AlgorithmAsir Mosaddek SakibNo ratings yet
- SL Classification For Data Science..Document4 pagesSL Classification For Data Science..shivaybhargava33No ratings yet
- Data Modeling - CheatsheetDocument9 pagesData Modeling - CheatsheetUtku GurcuogluNo ratings yet
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- Arpan ML 2.1Document8 pagesArpan ML 2.1Harwinder KaurNo ratings yet
- B24 ML Exp-3Document10 pagesB24 ML Exp-3SAKSHI TUPSUNDARNo ratings yet
- Dhrumil AmlDocument14 pagesDhrumil AmlSAVALIYA FENNYNo ratings yet
- # Capture The Target Column ("Default") Into Separate Vectors For Training Set and Test SetDocument4 pages# Capture The Target Column ("Default") Into Separate Vectors For Training Set and Test SetRohit KumarNo ratings yet
- DL Lab ManualDocument35 pagesDL Lab Manuallavanya penumudi100% (1)
- WLeaf Disease Classification - ResNet50.ipynb - ColaboratoryDocument12 pagesWLeaf Disease Classification - ResNet50.ipynb - ColaboratoryTefeNo ratings yet
- Check e Bae PDFDocument28 pagesCheck e Bae PDFjogoram219No ratings yet
- Course DescriptionDocument54 pagesCourse DescriptionMesafint lisanuNo ratings yet
- Biscotti: Notes: The Sugar I Use in France, Is CalledDocument2 pagesBiscotti: Notes: The Sugar I Use in France, Is CalledMonica CreangaNo ratings yet
- Donnan Membrane EquilibriaDocument37 pagesDonnan Membrane EquilibriamukeshNo ratings yet
- Datos Adjuntos Sin Título 00013Document3 pagesDatos Adjuntos Sin Título 00013coyana9652No ratings yet
- Effect of Plant Growth RegulatorsDocument17 pagesEffect of Plant Growth RegulatorsSharmilla AshokhanNo ratings yet
- VLSI Implementation of Floating Point AdderDocument46 pagesVLSI Implementation of Floating Point AdderParamesh Waran100% (1)
- Percentage and Profit & Loss: Aptitude AdvancedDocument8 pagesPercentage and Profit & Loss: Aptitude AdvancedshreyaNo ratings yet
- Design Practical Eden Swithenbank Graded PeDocument7 pagesDesign Practical Eden Swithenbank Graded Peapi-429329398No ratings yet
- Case No. Class Action Complaint Jury Trial DemandedDocument43 pagesCase No. Class Action Complaint Jury Trial DemandedPolygondotcom50% (2)
- Beamng DxdiagDocument22 pagesBeamng Dxdiagsilvioluismoraes1No ratings yet
- Furnace Temperature & PCE ConesDocument3 pagesFurnace Temperature & PCE ConesAbdullrahman Alzahrani100% (1)
- Allegro Delivery Shipping Company Employment Application FormDocument3 pagesAllegro Delivery Shipping Company Employment Application FormshiveshNo ratings yet
- C++ Program To Create A Student Database - My Computer ScienceDocument10 pagesC++ Program To Create A Student Database - My Computer ScienceSareeya ShreNo ratings yet
- Remedy MidTier Guide 7-5Document170 pagesRemedy MidTier Guide 7-5martin_wiedmeyerNo ratings yet
- Learning TheoryDocument7 pagesLearning Theoryapi-568999633No ratings yet
- 1st Problem Solving Assignment - Barrels of Apples - M383 Sp22.docx-2Document4 pages1st Problem Solving Assignment - Barrels of Apples - M383 Sp22.docx-2Kor16No ratings yet
- Abc Uae Oil and GasDocument41 pagesAbc Uae Oil and GasajayNo ratings yet
- ATAL Selected FDPs AY 2023 24Document15 pagesATAL Selected FDPs AY 2023 24parthiban palanisamy100% (2)
- Nyamango Site Meeting 9 ReportDocument18 pagesNyamango Site Meeting 9 ReportMbayo David GodfreyNo ratings yet
- SAP HR - Legacy System Migration Workbench (LSMW)Document5 pagesSAP HR - Legacy System Migration Workbench (LSMW)Bharathk KldNo ratings yet
- Junos ErrorsDocument2 pagesJunos ErrorsrashidsharafatNo ratings yet
- ProjectDocument33 pagesProjectPiyush PatelNo ratings yet