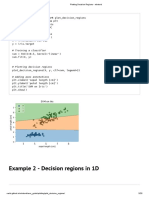
You might also like
- CodesDocument6 pagesCodesVamshi KrishnaNo ratings yet
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- Machine LearninDocument23 pagesMachine LearninManoj Kumar 1183100% (1)
- Appendix PDFDocument5 pagesAppendix PDFRamaNo ratings yet
- Cancer Disease ClassificationDocument6 pagesCancer Disease ClassificationBARATH PNo ratings yet
- 2020 CS 95.pyDocument1 page2020 CS 95.pyQazi MaazNo ratings yet
- CorrectionDocument3 pagesCorrectionbougmazisoufyaneNo ratings yet
- 2020 CS 64Document1 page2020 CS 64Qazi MaazNo ratings yet
- Texte ClassificationDocument9 pagesTexte ClassificationAla ArbounNo ratings yet
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- ML Ex8Document2 pagesML Ex8yefigoh133No ratings yet
- Quick StatementDocument7 pagesQuick StatementHarshit ChudiwalNo ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- Import Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadDocument20 pagesImport Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadSaloni TuliNo ratings yet
- Aries ProjectDocument6 pagesAries ProjectDivyansh BhadauriaNo ratings yet
- Exp 6Document6 pagesExp 6jayNo ratings yet
- Machine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionDocument22 pagesMachine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionKANTESH kantesh100% (1)
- SL Classification For Data Science..Document4 pagesSL Classification For Data Science..shivaybhargava33No ratings yet
- CIDocument1 pageCISanwarie GunaratneNo ratings yet
- Experiment No.:1: ProgramDocument7 pagesExperiment No.:1: ProgramDhiraj ShahNo ratings yet
- DA3MLDocument3 pagesDA3MLshreyas kumarNo ratings yet
- Big Data MergedDocument7 pagesBig Data MergedIngame IdNo ratings yet
- Deep Learning PerceptronDocument10 pagesDeep Learning PerceptronAvinash KumarNo ratings yet
- ML 1-10Document53 pagesML 1-1022128008No ratings yet
- Binary MulticlassDocument3 pagesBinary MulticlassNikhil PNo ratings yet
- Plotting Decision Regions - MlxtendDocument5 pagesPlotting Decision Regions - Mlxtendakhi016733No ratings yet
- CodeDocument6 pagesCodeKeerti GulatiNo ratings yet
- malharDL 2 .Ipynb - ColabDocument6 pagesmalharDL 2 .Ipynb - Colabcsae99No ratings yet
- FA NotesDocument2 pagesFA NotesShreya GargNo ratings yet
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- EXP 08 (ML) - ShriDocument2 pagesEXP 08 (ML) - ShriDSE 04. Chetana BhoirNo ratings yet
- Practicle6 (Code)Document4 pagesPracticle6 (Code)Pallavi GaikwadNo ratings yet
- TreeDocument7 pagesTreeindigalakishoreNo ratings yet
- ML Lab ProgramsDocument23 pagesML Lab ProgramsRoopa 18-19-36No ratings yet
- Support Vector Machine A) ClassificationDocument3 pagesSupport Vector Machine A) Classification4NM20IS003 ABHISHEK ANo ratings yet
- Supervised Learning For Data Science...Document14 pagesSupervised Learning For Data Science...shivaybhargava33No ratings yet
- Plotting Decision Regions - 1 - MlxtendDocument5 pagesPlotting Decision Regions - 1 - Mlxtendakhi016733No ratings yet
- Ai Kode Pert 12Document2 pagesAi Kode Pert 12Pidut 02No ratings yet
- Linearregression 4Document3 pagesLinearregression 4api-559045701No ratings yet
- Az Her and TahirDocument2 pagesAz Her and Tahirsyedosmanali040No ratings yet
- Estiven - Hurtado.Santos - Regresión Con Varios AlgoritmosDocument16 pagesEstiven - Hurtado.Santos - Regresión Con Varios AlgoritmosEstiven Hurtado SantosNo ratings yet
- QLSTMvs LSTMDocument7 pagesQLSTMvs LSTMmohamedaligharbi20No ratings yet
- Laboratorio Regresión Logística - Colaboratory Grupo 2Document7 pagesLaboratorio Regresión Logística - Colaboratory Grupo 2Priscila FloresNo ratings yet
- Untitled2.ipynb - ColaboratoryDocument2 pagesUntitled2.ipynb - ColaboratoryrvvnbraoNo ratings yet
- 20-SE-66 ML Assign 2Document4 pages20-SE-66 ML Assign 2Muhammad Ali EjazNo ratings yet
- Daftar Lampiran Coding Python RecognizeDocument7 pagesDaftar Lampiran Coding Python RecognizeResha Noviane PutriNo ratings yet
- ArbolesRF UNIDocument3 pagesArbolesRF UNIALISON ELIZABETH HUAPAYA CAYCHONo ratings yet
- FML File FinalDocument36 pagesFML File FinalKunal SainiNo ratings yet
- ML - LAB - 7 - Jupyter NotebookDocument7 pagesML - LAB - 7 - Jupyter Notebooksuman100% (1)
- Machinelearning - Alisya Athirah Binti Mohd Huzzainny (Updated)Document26 pagesMachinelearning - Alisya Athirah Binti Mohd Huzzainny (Updated)Alisya AthirahNo ratings yet
- Is Lab Aman Agarwal PDFDocument8 pagesIs Lab Aman Agarwal PDFAman BansalNo ratings yet
- Import As Import As Import As: # Importing The LibrariesDocument3 pagesImport As Import As Import As: # Importing The Libraries19-361 Sai PrathikNo ratings yet
- Practical File of Machine Learning 1905388Document42 pagesPractical File of Machine Learning 1905388DevanshNo ratings yet
- Assignment10 3Document4 pagesAssignment10 3dashNo ratings yet
- SampleDocument2 pagesSampleMAHAKAL (Tushar)No ratings yet
- Mercedes-Benz Greener Manufacturing AiDocument16 pagesMercedes-Benz Greener Manufacturing AiPuji0% (1)
- Machine Learning Notes: 2. All The Commands For EdaDocument5 pagesMachine Learning Notes: 2. All The Commands For Edanaveen katta100% (1)
- Tous Les Algo de MLDocument7 pagesTous Les Algo de MLJadlaoui AsmaNo ratings yet
- 23MCA1104 - EX10 - KMEANS - Ipynb - ColabDocument1 page23MCA1104 - EX10 - KMEANS - Ipynb - ColabPiyush VermaNo ratings yet
- 01 - How To Image A Windows System Using A Bootable WinPE UFD and ImageX - RDocument6 pages01 - How To Image A Windows System Using A Bootable WinPE UFD and ImageX - RJusto FigueroaNo ratings yet
- Setup Prometheus Monitoring On KubernetesDocument6 pagesSetup Prometheus Monitoring On KubernetesAymenNo ratings yet
- Th42px74ea PDFDocument48 pagesTh42px74ea PDFJuan GutierrezNo ratings yet
- Resources For Rero - Micro Lessons 1 To 10Document11 pagesResources For Rero - Micro Lessons 1 To 10hj waladcute100% (3)
- Cybersecurity and Physical Security ConvergenceDocument4 pagesCybersecurity and Physical Security ConvergenceDavid F MartinezNo ratings yet
- Predicting The Stock Market Using Machine Learning and Deep Learning PDFDocument58 pagesPredicting The Stock Market Using Machine Learning and Deep Learning PDFPrakash PokhrelNo ratings yet
- A10 Thunder Vlan Bridging + VRRPDocument328 pagesA10 Thunder Vlan Bridging + VRRPWaldino TurraNo ratings yet
- Pitney BowesDocument15 pagesPitney BowesPeter Sen Gupta100% (1)
- Downloads Pqsine S 1 16 16Document1 pageDownloads Pqsine S 1 16 16SANDRO RAUL HUAMANI PIZARRONo ratings yet
- Lec 5Document23 pagesLec 5Sama Atif Abdel-LatifNo ratings yet
- General Science & Ability - Past Papers AnalysisDocument22 pagesGeneral Science & Ability - Past Papers AnalysisAmeena AimenNo ratings yet
- Disk MagicDocument4 pagesDisk MagicMuhammad Javed SajidNo ratings yet
- Instructor Materials Chapter 3: Computer Assembly: IT Essentials v6.0Document28 pagesInstructor Materials Chapter 3: Computer Assembly: IT Essentials v6.0opsssNo ratings yet
- Tower of HanoiDocument2 pagesTower of Hanoiapi-281272453No ratings yet
- Ict Form 2Document12 pagesIct Form 2farah7No ratings yet
- Project Communication PlanDocument5 pagesProject Communication PlanCraig VanceNo ratings yet
- PT Simulation 1 - Intro To Cisco Packet TracerDocument6 pagesPT Simulation 1 - Intro To Cisco Packet TracerRaymond NocheteNo ratings yet
- DCS A-10C Keyboard LayoutDocument7 pagesDCS A-10C Keyboard LayoutMichiel Erasmus100% (2)
- Sip Series PDocument69 pagesSip Series PSyed Rahmath AliNo ratings yet
- Cyberbullying BrochureDocument2 pagesCyberbullying Brochureapi-614083099No ratings yet
- OCL TutorialDocument3 pagesOCL Tutorialshahid_abdullahNo ratings yet
- ME100 Draft Report Evaluation, Group 2 Final ReportDocument2 pagesME100 Draft Report Evaluation, Group 2 Final ReportDavid WheatleNo ratings yet
- C# Dot NetDocument25 pagesC# Dot NetShubham YadavNo ratings yet
- Analysis of Online Retail Business Development Using Business Model CanvasDocument10 pagesAnalysis of Online Retail Business Development Using Business Model CanvasInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Online Photography Management System 1Document4 pagesOnline Photography Management System 1kamalshrish100% (1)
- VW 0027Document7 pagesVW 0027Ĵames-Ĕddìne BaîaNo ratings yet
- WK 3 PE 3032 TF Signal Flow Graphs Mason Ed0314Document38 pagesWK 3 PE 3032 TF Signal Flow Graphs Mason Ed0314gashawletaNo ratings yet
- TMA4215 Report (10056,10047,10023)Document5 pagesTMA4215 Report (10056,10047,10023)EvacuolNo ratings yet
- Sm-Sinamics S120Document55 pagesSm-Sinamics S120preferredcustomerNo ratings yet
- PHP MySQLDocument85 pagesPHP MySQLDevendraNo ratings yet