You might also like
- Sarcasm Detection For Hindi English Code Mixed Twitter DataDocument8 pagesSarcasm Detection For Hindi English Code Mixed Twitter DataIJRASETPublicationsNo ratings yet
- Information Sciences: Li Kong, Chuanyi Li, Jidong Ge, Feifei Zhang, Yi Feng, Zhongjin Li, Bin LuoDocument17 pagesInformation Sciences: Li Kong, Chuanyi Li, Jidong Ge, Feifei Zhang, Yi Feng, Zhongjin Li, Bin LuoSabbir HossainNo ratings yet
- Sentimental Analysis On Live Twitter DataDocument7 pagesSentimental Analysis On Live Twitter DataIJRASETPublicationsNo ratings yet
- Context-Aware Tweet Enrichment For Sentiment Analysis: IAES International Journal of Artificial Intelligence (IJ-AI)Document9 pagesContext-Aware Tweet Enrichment For Sentiment Analysis: IAES International Journal of Artificial Intelligence (IJ-AI)Qossai TahaynaNo ratings yet
- Text Based Personality Prediction From Multiple SoDocument21 pagesText Based Personality Prediction From Multiple SopsgtelugoduNo ratings yet
- Negative Sentiment Analysis Hate Speech Detection and Cyber BullyingDocument9 pagesNegative Sentiment Analysis Hate Speech Detection and Cyber BullyingIJRASETPublicationsNo ratings yet
- Hate Speech Detection Using Machine LearningDocument5 pagesHate Speech Detection Using Machine LearningIJRASETPublicationsNo ratings yet
- Optimal Feature Extraction Based Machine Learning Approach For Sarcasm Type Detection in News HeadlinesDocument5 pagesOptimal Feature Extraction Based Machine Learning Approach For Sarcasm Type Detection in News HeadlinesGina Suastika SudibyoNo ratings yet
- A Survey On Sentimental Analysis Approaches Using Machine Learning AlgorithmsDocument12 pagesA Survey On Sentimental Analysis Approaches Using Machine Learning AlgorithmsIJRASETPublicationsNo ratings yet
- Sentiment Analysis of TwitterDocument9 pagesSentiment Analysis of TwitterIJRASETPublicationsNo ratings yet
- Named Entity Recognition in Social Media DataDocument23 pagesNamed Entity Recognition in Social Media DataIJRASETPublicationsNo ratings yet
- Improving Hate Speech Detection of Urdu Tweets Using Sentiment AnalysisDocument10 pagesImproving Hate Speech Detection of Urdu Tweets Using Sentiment AnalysisMessalti Ahmed zoubirNo ratings yet
- Analysis of Different Text Features Using NLPDocument7 pagesAnalysis of Different Text Features Using NLPIJRASETPublicationsNo ratings yet
- Sentiment Analysis Using CATAtoolsDocument10 pagesSentiment Analysis Using CATAtoolsMahmoud MahdyNo ratings yet
- Natural Language Processing Project Review-3: Cyber Bullying Detection System Using Sentiment AnalysisDocument30 pagesNatural Language Processing Project Review-3: Cyber Bullying Detection System Using Sentiment AnalysisPrayNo ratings yet
- Stemming Information Retrieval Research PaperDocument8 pagesStemming Information Retrieval Research Papercakvaw0q100% (1)
- Sentimental Analysis of Product Review Data Using Deep LearningDocument5 pagesSentimental Analysis of Product Review Data Using Deep LearningIJRASETPublicationsNo ratings yet
- WTI - An Approach To Enrich Users Personomy Using Semantic Recommendation of TagsDocument10 pagesWTI - An Approach To Enrich Users Personomy Using Semantic Recommendation of TagsMarcelo BorthNo ratings yet
- Discovering Emerging Topics in Social Streams Via Link-Anomaly DetectionDocument5 pagesDiscovering Emerging Topics in Social Streams Via Link-Anomaly DetectionSikkandhar JabbarNo ratings yet
- Knowledge-Based Systems: Oscar Araque, Ganggao Zhu, Carlos A. IglesiasDocument14 pagesKnowledge-Based Systems: Oscar Araque, Ganggao Zhu, Carlos A. IglesiasladduNo ratings yet
- Comparison of Sentiment Analysis Algorithms Using Twitter and Review DatasetDocument8 pagesComparison of Sentiment Analysis Algorithms Using Twitter and Review DatasetIJRASETPublicationsNo ratings yet
- Sentiment Prediction in Hindi and English LanguageDocument25 pagesSentiment Prediction in Hindi and English Languageasma.imtiaz2003No ratings yet
- Monkeylearn ThesisDocument19 pagesMonkeylearn ThesisvideepsinghalNo ratings yet
- Thesis Word CloudsDocument4 pagesThesis Word Cloudsk1lod0zolog3100% (2)
- A Hybrid Persian Sentiment Analysis Framework Integrating Dependency Grammar Based Rules and Deep Neural NetworksDocument10 pagesA Hybrid Persian Sentiment Analysis Framework Integrating Dependency Grammar Based Rules and Deep Neural NetworksLourdes B.D.No ratings yet
- Ontology-Based Software Engineering-Software Engineering 2.0Document11 pagesOntology-Based Software Engineering-Software Engineering 2.0K Krishna ChaitanyaNo ratings yet
- Study of Effective AI Algorithms in Natural Language Processing in Todays EraDocument8 pagesStudy of Effective AI Algorithms in Natural Language Processing in Todays EraIJRASETPublicationsNo ratings yet
- Ijet V3i6p32Document9 pagesIjet V3i6p32International Journal of Engineering and TechniquesNo ratings yet
- Twitter Sentiment Analysis Using NLTK and Machine LearningDocument8 pagesTwitter Sentiment Analysis Using NLTK and Machine LearningIJRASETPublicationsNo ratings yet
- Named Entity Recognition and Normalization in TweeDocument6 pagesNamed Entity Recognition and Normalization in TweeAngga SekarsanyNo ratings yet
- Sentiment Analysis To Handle Complex Linguistic Structures: A Review On Existing MethodologiesDocument7 pagesSentiment Analysis To Handle Complex Linguistic Structures: A Review On Existing MethodologiesRajkumar MishraNo ratings yet
- 1 s2.0 S0889159123000533 MainDocument4 pages1 s2.0 S0889159123000533 MainIrina TNo ratings yet
- Bda Mod5Document20 pagesBda Mod5sangamesh kNo ratings yet
- Computer Literature ReviewDocument8 pagesComputer Literature Reviewafdtywqae100% (1)
- Literature Review NetworkingDocument7 pagesLiterature Review Networkingfvhacvjd100% (1)
- The Importance of MultimodalityDocument5 pagesThe Importance of MultimodalityDarkNo ratings yet
- Abusive Language Detection in Speech DatasetDocument6 pagesAbusive Language Detection in Speech DatasetIJRASETPublicationsNo ratings yet
- Relative Advantage ChartDocument14 pagesRelative Advantage Chartcmills26No ratings yet
- Transforming Education with AI: Guide to Understanding and Using ChatGPT in the ClassroomFrom EverandTransforming Education with AI: Guide to Understanding and Using ChatGPT in the ClassroomNo ratings yet
- Project Prospectus-1Document7 pagesProject Prospectus-1api-538408600No ratings yet
- Da CH4 SlqaDocument4 pagesDa CH4 SlqaSushant ThiteNo ratings yet
- Language Variety Prediction Using Word Embeddings and Machine Leaning AlgorithmsDocument10 pagesLanguage Variety Prediction Using Word Embeddings and Machine Leaning AlgorithmsIJRASETPublicationsNo ratings yet
- Text Mining - Scope and Applications: Software Developer at ACSG, DelhiDocument6 pagesText Mining - Scope and Applications: Software Developer at ACSG, DelhiIpsita JenaNo ratings yet
- A Review On Emotion and Sentiment Analysis Using Learning TechniquesDocument13 pagesA Review On Emotion and Sentiment Analysis Using Learning TechniquesIJRASETPublicationsNo ratings yet
- Sentiment Analysis of Tweets Using Natural Language Processing (#1130188) - 2484168Document3 pagesSentiment Analysis of Tweets Using Natural Language Processing (#1130188) - 2484168yetsedawNo ratings yet
- A Method of Fine-Grained Short Text Sentiment Analysis Based On Machine LearningDocument20 pagesA Method of Fine-Grained Short Text Sentiment Analysis Based On Machine LearningShreyaskar SinghNo ratings yet
- Result Analysis of User Review For Sentiment ClassificationDocument8 pagesResult Analysis of User Review For Sentiment ClassificationIJRASETPublicationsNo ratings yet
- Applied Sciences: Gender Classification Using Sentiment Analysis and Deep Learning in A Health Web ForumDocument12 pagesApplied Sciences: Gender Classification Using Sentiment Analysis and Deep Learning in A Health Web ForumV.K. JoshiNo ratings yet
- Semester Project Report by QaiserDocument5 pagesSemester Project Report by QaiserxixaNo ratings yet
- Senticnet 4: A Semantic Resource For Sentiment Analysis Based On Conceptual PrimitivesDocument12 pagesSenticnet 4: A Semantic Resource For Sentiment Analysis Based On Conceptual PrimitivesCultural club IiitkotaNo ratings yet
- On The Semantic Patterns of Passwords and Their SeDocument17 pagesOn The Semantic Patterns of Passwords and Their SeskywalkerNo ratings yet
- A Review of Machine Learning and AI-Based Approaches To Detecting Cyberbullying On Social MediaDocument11 pagesA Review of Machine Learning and AI-Based Approaches To Detecting Cyberbullying On Social MediaIJRASETPublicationsNo ratings yet
- Sentiment Analysis of Informal Malay Tweets With Deep LearningDocument9 pagesSentiment Analysis of Informal Malay Tweets With Deep LearningIAES IJAINo ratings yet
- Sentiment Analysis of IMDb Movie ReviewsDocument9 pagesSentiment Analysis of IMDb Movie ReviewsIJRASETPublicationsNo ratings yet
- Project 2 1Document8 pagesProject 2 1api-538408600No ratings yet
- Emotion Detection On Social MediaDocument7 pagesEmotion Detection On Social MediaIJRASETPublicationsNo ratings yet
- Design of Traffic IntersectionDocument7 pagesDesign of Traffic IntersectionIJRASETPublicationsNo ratings yet
- CEA User Manual (NASA RP-1311) PDFDocument184 pagesCEA User Manual (NASA RP-1311) PDFAmer SmajkićNo ratings yet
- Google Pay (G Pay) : ContentDocument15 pagesGoogle Pay (G Pay) : ContentVharshiny SdNo ratings yet
- BCA LEAP Quick Guide v0 1Document9 pagesBCA LEAP Quick Guide v0 1Nigel AngNo ratings yet
- The KickbookDocument230 pagesThe KickbookreixelNo ratings yet
- Gcse Science Homework OnlineDocument4 pagesGcse Science Homework Onlinevxrtevhjf100% (1)
- 8086 Masm ManualDocument25 pages8086 Masm Manualsri_baba0988% (8)
- Panel Discussion Social Media Good or EvilDocument7 pagesPanel Discussion Social Media Good or Evilrcthakur0% (1)
- 2 Mbit / 3 Mbit / 4 Mbit LPC Firmware Flash: SST49LF002B / SST49LF003B / SST49LF004BDocument43 pages2 Mbit / 3 Mbit / 4 Mbit LPC Firmware Flash: SST49LF002B / SST49LF003B / SST49LF004BPayKa PastoryRiosNo ratings yet
- Ipython ManualDocument90 pagesIpython ManualFabiola Andrea Vergara GonzalezNo ratings yet
- ASMi 54Document8 pagesASMi 54JORGE ALICE ALEENo ratings yet
- Web Source For Website On WixDocument13 pagesWeb Source For Website On WixSharona jackNo ratings yet
- Dokumen - Tips Ericsson Rbs Ret Alarms Troubleshooting Guide Flow Chart v2Document1 pageDokumen - Tips Ericsson Rbs Ret Alarms Troubleshooting Guide Flow Chart v2Oscar GonzalezNo ratings yet
- Man0017563 Evos m5000 Imaging System UgDocument140 pagesMan0017563 Evos m5000 Imaging System UgRoNo ratings yet
- Functions CheatsheetDocument4 pagesFunctions CheatsheetPranay BagdeNo ratings yet
- It115 - U1l1Document35 pagesIt115 - U1l1Rico CombinidoNo ratings yet
- SoftwareDesignSpecification TemplateDocument7 pagesSoftwareDesignSpecification Templategiaphuc2004hgNo ratings yet
- An Analysis of The Cloud Computing Security ProblemDocument8 pagesAn Analysis of The Cloud Computing Security ProblemKarthik KrishnamurthiNo ratings yet
- Univariate Time Series Modelling and ForecastingDocument74 pagesUnivariate Time Series Modelling and ForecastingUploader_LLBBNo ratings yet
- Installer Preparation and Creating Bootable DevicesDocument17 pagesInstaller Preparation and Creating Bootable DevicesBenson Falco100% (4)
- Snake 101Document13 pagesSnake 101cryptobengsgNo ratings yet
- Event-Driven MicroservicesDocument25 pagesEvent-Driven MicroservicesKarthik KumarNo ratings yet
- Trbonet Swift A100: Radio-Over-Ip Gateway User ManualDocument34 pagesTrbonet Swift A100: Radio-Over-Ip Gateway User ManualWilfredo GarciaNo ratings yet
- Computer Ports - Cases Power Supply - MOBODocument97 pagesComputer Ports - Cases Power Supply - MOBONhoj Bener StreqsNo ratings yet
- Applicable To BPL/EWS/SC/ST/OBC-NCL/DA: Reply ?Document4 pagesApplicable To BPL/EWS/SC/ST/OBC-NCL/DA: Reply ?sambhudharmadevanNo ratings yet
- GPS Module For Arduino, Raspberry Pi and Intel GalileoDocument5 pagesGPS Module For Arduino, Raspberry Pi and Intel Galileoteen starNo ratings yet
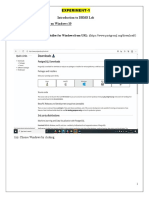
- Introduction To Dbms Lab Installation of Postgresql On Windows 10Document16 pagesIntroduction To Dbms Lab Installation of Postgresql On Windows 10Sriram RadheyNo ratings yet
- SHELL RECORD FullDocument23 pagesSHELL RECORD FullananthalaxmiNo ratings yet
- Iot Car FingerprintDocument97 pagesIot Car FingerprintPeace EmmanuelNo ratings yet
- RDP Event Log ForensicsDocument6 pagesRDP Event Log ForensicsAmrishuNo ratings yet
- MD - Mizanur RahmanDocument3 pagesMD - Mizanur RahmanSabuj EvergreenNo ratings yet