You might also like
- Regression and Correlation Methods in Highway Maintenance OperationsDocument11 pagesRegression and Correlation Methods in Highway Maintenance OperationsLestor NaribNo ratings yet
- M11 Aerodynamcis, Structures and Instruments 2 Of2Document790 pagesM11 Aerodynamcis, Structures and Instruments 2 Of2kls070376No ratings yet
- Adobe Scan Jun 22, 2023Document1 pageAdobe Scan Jun 22, 2023vijay playsNo ratings yet
- McCullagh 1978 - Ch2Document13 pagesMcCullagh 1978 - Ch2Basundhara HaldarNo ratings yet
- The Architecture of DiagramsDocument83 pagesThe Architecture of DiagramsKholifahNo ratings yet
- Chain.-A Very Important Chain Is: Slider-Crank ChainsDocument44 pagesChain.-A Very Important Chain Is: Slider-Crank ChainsInam Ul HaqNo ratings yet
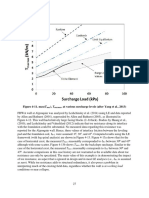
- Surcharge Load (Kpa) : R E O O LiDocument1 pageSurcharge Load (Kpa) : R E O O LiYassin Abd El AalNo ratings yet
- Main Campus Parking Map: University Hawai'IDocument1 pageMain Campus Parking Map: University Hawai'IWulfert IngliansNo ratings yet
- Paper No. 1262: by Prof. C. W. PROHASKA, D.SCDocument30 pagesPaper No. 1262: by Prof. C. W. PROHASKA, D.SCVebly MogantiNo ratings yet
- Hydrophore PumpDocument2 pagesHydrophore PumpMiky GavrilNo ratings yet
- Site / ID Type of Tower Proyek Kontrak No. Data Hasil Pengukuran Ketegakan MenaraDocument1 pageSite / ID Type of Tower Proyek Kontrak No. Data Hasil Pengukuran Ketegakan MenaraAljufri AhmadNo ratings yet
- Problem 5Document1 pageProblem 5Jewel Lhieme T. ArcillaNo ratings yet
- Speech Sound NormsDocument3 pagesSpeech Sound NormsJohn BennettNo ratings yet
- 1417 1951 BahDocument153 pages1417 1951 BahBarinder SamraNo ratings yet
- Required: Indicate Each Account's Classification and Normal Balance by Placing (/) Marks. TheDocument1 pageRequired: Indicate Each Account's Classification and Normal Balance by Placing (/) Marks. TheBebie Joy UrbanoNo ratings yet
- MMP Layout Comparison-1Document1 pageMMP Layout Comparison-1danish.1725417No ratings yet
- ML19094B846Document5 pagesML19094B846Nathan BlockNo ratings yet
- The Corvette: A Nathaniel Drinkwater NovelFrom EverandThe Corvette: A Nathaniel Drinkwater NovelRating: 4.5 out of 5 stars4.5/5 (14)
- Golden Ratio Coloring Book by Rafael AraujoDocument28 pagesGolden Ratio Coloring Book by Rafael AraujoTijana Stankovic67% (3)
- Golden Ratio Coloring Book by Rafael Araujo PDFDocument28 pagesGolden Ratio Coloring Book by Rafael Araujo PDFmisterno27100% (1)
- Golden Ratio Coloring Book by Rafael Araujo PDFDocument28 pagesGolden Ratio Coloring Book by Rafael Araujo PDFLuis ArancibiaNo ratings yet
- Frazetta Sketchbook 1 RsDocument54 pagesFrazetta Sketchbook 1 RsAtliaxRo - LOL100% (5)
- ws04 ph255Document1 pagews04 ph255Ben WrightNo ratings yet
- Chapter 12 - Practical Application of Interference and Pulse TestsDocument15 pagesChapter 12 - Practical Application of Interference and Pulse TestsmisterkoroNo ratings yet
- Danube River Basin District Managment Plan Update 2015Document192 pagesDanube River Basin District Managment Plan Update 2015RavenNo ratings yet
- Duplicate Degree Form - AIOUDocument2 pagesDuplicate Degree Form - AIOUBilal YounisNo ratings yet
- Exercise - Intro Report Writing (Syukur)Document2 pagesExercise - Intro Report Writing (Syukur)Syukur AdamNo ratings yet
- Rowley Conwy 2001 PDFDocument35 pagesRowley Conwy 2001 PDFBas's ReviewsNo ratings yet
- Web Based Application Development With PHPDocument8 pagesWeb Based Application Development With PHPMaitray WaniNo ratings yet
- Prepare For Iftar: You Can Find Us atDocument11 pagesPrepare For Iftar: You Can Find Us atHellen ChristineNo ratings yet
- DOB Change NewDocument2 pagesDOB Change NewDaim ButtNo ratings yet
- Kinetics of Ethylbenzene Hydrogenation On Ni-Al2O3 - 9Document1 pageKinetics of Ethylbenzene Hydrogenation On Ni-Al2O3 - 9Mourad kharbachNo ratings yet
- Bio-Expt. No. 9Document3 pagesBio-Expt. No. 9mankarravindra61No ratings yet
- 0653 s11 QP 22 PDFDocument20 pages0653 s11 QP 22 PDFmarryNo ratings yet
- Satellite Antenna Farm SiteDocument1 pageSatellite Antenna Farm SiteAnonymous fHFI5gUNo ratings yet
- Varification PDFDocument1 pageVarification PDFfarukh iqbalNo ratings yet
- Varification PDFDocument1 pageVarification PDFNiaz AsgharNo ratings yet
- Varification PDFDocument1 pageVarification PDFarbzaheerNo ratings yet
- Var If IcationDocument1 pageVar If IcationAsadNo ratings yet
- Sanity: Investigator Name: Birthplace: Gender: Age: Height: WeightDocument2 pagesSanity: Investigator Name: Birthplace: Gender: Age: Height: WeightjorgecrapNo ratings yet
- University of Cambridge International Examinations General Certificate of Education Ordinary LevelDocument20 pagesUniversity of Cambridge International Examinations General Certificate of Education Ordinary Levelmuhammad saleemNo ratings yet
- Oxford Activity Book For Children - 3Document36 pagesOxford Activity Book For Children - 3Наталія ПрисяжнюкNo ratings yet
- Hagbay - SBM 20-21Document9 pagesHagbay - SBM 20-21Shalee Carpio BalanquitNo ratings yet
- GAS PROCESSING - Gas Conditioning & Processing Vol 3Document438 pagesGAS PROCESSING - Gas Conditioning & Processing Vol 3Alejandra AriasNo ratings yet
- 0654 s06 QP 2Document20 pages0654 s06 QP 2S Ms.No ratings yet
- Avinashilingam Univeristy Question PapersDocument20 pagesAvinashilingam Univeristy Question PapersPhysics Mathematics SolutionsNo ratings yet
- Ltagamaran NG Filukaspon: Itrpublika n11 .Document2 pagesLtagamaran NG Filukaspon: Itrpublika n11 .Chard A. CañasNo ratings yet
- Three: The Student Must Be ToDocument10 pagesThree: The Student Must Be ToAnonymous dqbb02DUhNo ratings yet
- 3 Point Rule TT 04272017Document2 pages3 Point Rule TT 04272017dicksonkabrahamNo ratings yet
- Fluency InterventionsDocument1 pageFluency Interventionsapi-477891212No ratings yet
- SMK090 - Pencil Control Line Tracing Worksheets R2.1Document43 pagesSMK090 - Pencil Control Line Tracing Worksheets R2.17b75hhskhvNo ratings yet
- SMK090 - Pencil Control Line Tracing Worksheets R2.1Document43 pagesSMK090 - Pencil Control Line Tracing Worksheets R2.17b75hhskhvNo ratings yet
- Assignment 1 (LeungChiHei)Document7 pagesAssignment 1 (LeungChiHei)Lee Tin YanNo ratings yet
- ACI 117-10 Specification For Tolerances For Concrete Construction and Materials (ACI 117-10) and CommentaryDocument80 pagesACI 117-10 Specification For Tolerances For Concrete Construction and Materials (ACI 117-10) and Commentaryfostbarr100% (1)
- QF-08-SHS-007-G12 PRE-BAC Class-Attendance-Monitoring-Rev.-1Document2 pagesQF-08-SHS-007-G12 PRE-BAC Class-Attendance-Monitoring-Rev.-1Alfredo ModestoNo ratings yet
- Progress Chart Bread and Pastry Production NC Ii: Basic CompetenciesDocument4 pagesProgress Chart Bread and Pastry Production NC Ii: Basic CompetenciesLovely TaguasNo ratings yet
- Screenshot 2022-05-23 at 8.58.46 PMDocument42 pagesScreenshot 2022-05-23 at 8.58.46 PMChandramohan KaavyaNo ratings yet
- Cinefantastique v02n04 Summer (1973) PDFDocument48 pagesCinefantastique v02n04 Summer (1973) PDFAnonymous 04ARSHnCNl100% (1)
- PDU Lab#1Document9 pagesPDU Lab#1Mohsin ZubairNo ratings yet
- Midterm Notes 1Document11 pagesMidterm Notes 1Aryan GuptaNo ratings yet
- CS361 FA23 Lec5 PostDocument29 pagesCS361 FA23 Lec5 PostAryan GuptaNo ratings yet
- Acid Deposition - ChemDocument4 pagesAcid Deposition - ChemAryan GuptaNo ratings yet
- Solubility of Citric and Tartaric Acids WaterDocument3 pagesSolubility of Citric and Tartaric Acids WaterAryan GuptaNo ratings yet
- Hearts and HandsDocument2 pagesHearts and HandsAryan GuptaNo ratings yet
- Hearts and HandsDocument2 pagesHearts and HandsAryan GuptaNo ratings yet
- CS Cheat CodesDocument4 pagesCS Cheat CodesNicholas Owen M ChandraNo ratings yet
- Con ArtsDocument29 pagesCon Artssophia lizarondoNo ratings yet
- 04-04 ART How BPM Impacts Consulting Serv - PetrassiDocument4 pages04-04 ART How BPM Impacts Consulting Serv - PetrassidaxstarNo ratings yet
- MCQ - Nptel - Introduction To ResearchDocument34 pagesMCQ - Nptel - Introduction To Researchnalini50% (2)
- SWIFT Wireless AV Base: GeneralDocument3 pagesSWIFT Wireless AV Base: GeneralEliudNo ratings yet
- Lab 5-1 Develop Software Nios TimerDocument9 pagesLab 5-1 Develop Software Nios TimerVõ Quang Thanh NghĩaNo ratings yet
- Convolution Neural NetworkDocument74 pagesConvolution Neural Networktoon townNo ratings yet
- De on tap PE NWC203c so 2 - Đề ôn PE SU21: Networking (Trường Đại học FPT)Document11 pagesDe on tap PE NWC203c so 2 - Đề ôn PE SU21: Networking (Trường Đại học FPT)jakehauer1234No ratings yet
- Thermon VisTraceIntroDocument4 pagesThermon VisTraceIntroBill CaiNo ratings yet
- Madhapur Isthara Co-LivingDocument24 pagesMadhapur Isthara Co-LivingSharan GupthaNo ratings yet
- HPEDBaaSusing VREDocument54 pagesHPEDBaaSusing VRESatish MarupallyNo ratings yet
- Interview Questions For QA Tester-1Document31 pagesInterview Questions For QA Tester-1namrata kokateNo ratings yet
- Pitch Deck Pi Code Club NewDocument13 pagesPitch Deck Pi Code Club NewKannan JojodeNo ratings yet
- Phases - Level 3 - 2nd Edition - Student S Book - Unit 2Document14 pagesPhases - Level 3 - 2nd Edition - Student S Book - Unit 2Rodolfo MoyanoNo ratings yet
- Manual - CSP Calculation ToolDocument49 pagesManual - CSP Calculation ToolCaio AndradeNo ratings yet
- EMC XtremIO Simple Support MatrixDocument2 pagesEMC XtremIO Simple Support MatrixstewdapewNo ratings yet
- Planet Shadow MatchDocument4 pagesPlanet Shadow MatchRoxana Maria EneNo ratings yet
- Printable BatteriesDocument21 pagesPrintable BatteriesMukund MohanNo ratings yet
- Arbor Threat Mitigation System TmsDocument3 pagesArbor Threat Mitigation System TmsnovinickNo ratings yet
- Fact Sheet - Dublin CoreDocument2 pagesFact Sheet - Dublin CorespiderbrigadeNo ratings yet
- Global Certificate in Product ManagementDocument9 pagesGlobal Certificate in Product ManagementmemunuNo ratings yet
- 4 Vol 245 Oct 2020 ExtrasDocument16 pages4 Vol 245 Oct 2020 ExtrasSTAN MARIANo ratings yet
- Data Engineer - Roadmap and FREE Resources - Paper 2021Document7 pagesData Engineer - Roadmap and FREE Resources - Paper 2021svdNo ratings yet
- MehdiPourghaemi ResumeDocument2 pagesMehdiPourghaemi ResumeAnonymous cXtQk8kJtBNo ratings yet
- Microsoft PowerPoint 2016Document63 pagesMicrosoft PowerPoint 2016Timothy Lemuel GulapaNo ratings yet
- Alpeta Install QuickGuide (English)Document15 pagesAlpeta Install QuickGuide (English)kalkumarmNo ratings yet
- Exercise 1: Receiving AM Signals From Data Files: Part 1. Listening To An AM SignalDocument4 pagesExercise 1: Receiving AM Signals From Data Files: Part 1. Listening To An AM SignalandrovisckNo ratings yet
- Popcorn ExperimentDocument3 pagesPopcorn ExperimentNiraj AltekarNo ratings yet
- Audit Training ManualDocument15 pagesAudit Training ManualNilesh GhamNo ratings yet
- Lab 8 Final AWAISDocument9 pagesLab 8 Final AWAISULFAT HUSSAINNo ratings yet