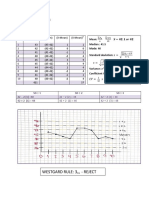
You might also like
- 68617302-Spermans-Rank-Correlation Solved ExamplesDocument23 pages68617302-Spermans-Rank-Correlation Solved ExamplesUmashankar GautamNo ratings yet
- CORRELATION and RegressionDocument6 pagesCORRELATION and RegressionMikee Jane Mapayo SabilloNo ratings yet
- Spearmen Corelation PDFDocument7 pagesSpearmen Corelation PDFneerupachauhanNo ratings yet
- Correlation and Regression NotesDocument14 pagesCorrelation and Regression NotesSwapnil OzaNo ratings yet
- Correlation Analysis - FinalDocument40 pagesCorrelation Analysis - FinalDr. POONAM KAUSHALNo ratings yet
- Inference Note DCS 219Document10 pagesInference Note DCS 219Michael T. BelloNo ratings yet
- AUTOKORELASIDocument18 pagesAUTOKORELASINurwinda RamadhaniNo ratings yet
- Activity Sheets in Statistics and Probability: Quarter 4, Week 8 Regression AnalysisDocument13 pagesActivity Sheets in Statistics and Probability: Quarter 4, Week 8 Regression AnalysisRaj Kervie ConiguenNo ratings yet
- CAPSM MAT 4 ModDocument34 pagesCAPSM MAT 4 ModRahul SinghNo ratings yet
- Measures ofDocument6 pagesMeasures ofVernam Ci9090No ratings yet
- Assesment in Learning I Variance and Standard DeviationDocument2 pagesAssesment in Learning I Variance and Standard DeviationFor BackupNo ratings yet
- Correlation & Regression NumericalsDocument4 pagesCorrelation & Regression Numericalsswati chawlaNo ratings yet
- CorrelationDocument5 pagesCorrelationMartin KobimboNo ratings yet
- Measures of Variation GE 104 MMWDocument26 pagesMeasures of Variation GE 104 MMWJulie EsmaNo ratings yet
- CorrelationDocument17 pagesCorrelationMa Antonetta Pilar SetiasNo ratings yet
- A Level Math Paper 2 Correlation and Scatter DiagramsDocument30 pagesA Level Math Paper 2 Correlation and Scatter DiagramsAyiko MorganNo ratings yet
- Sandeep Garg Economics Class 11 Solutions For Chapter 8 - Measures of CorrelationDocument5 pagesSandeep Garg Economics Class 11 Solutions For Chapter 8 - Measures of CorrelationRiddhiman JainNo ratings yet
- Linear Algebra (Lesson 02)Document15 pagesLinear Algebra (Lesson 02)Mr.XausuNo ratings yet
- Spearman Rank Order Correlation CoefficientDocument18 pagesSpearman Rank Order Correlation CoefficientFia JungNo ratings yet
- Marking Scheme Class-X, Session - 2021-22 Term Ii Subject - Mathematics (Standard)Document5 pagesMarking Scheme Class-X, Session - 2021-22 Term Ii Subject - Mathematics (Standard)Satyam KumarNo ratings yet
- Marking Scheme Class-X, Session - 2021-22 Term Ii Subject - Mathematics (Standard)Document5 pagesMarking Scheme Class-X, Session - 2021-22 Term Ii Subject - Mathematics (Standard)Aniket AryanNo ratings yet
- Macabingkel - Statistics On QC and QaDocument4 pagesMacabingkel - Statistics On QC and QaErica Mae MacabingkelNo ratings yet
- UntitledDocument8 pagesUntitledNICDAO, Christine JoyNo ratings yet
- Spearman Rank-Order CorrelationDocument16 pagesSpearman Rank-Order CorrelationNicoleNo ratings yet
- Geometric SeriesDocument9 pagesGeometric SeriesastralabozNo ratings yet
- 5 - DR - SAID SP 22 - ARCH 227 - DR. SAID - Lectture-4 - Statistical MethodsDocument16 pages5 - DR - SAID SP 22 - ARCH 227 - DR. SAID - Lectture-4 - Statistical MethodsLaith DermoshNo ratings yet
- Powering With Rational ExponentDocument1 pagePowering With Rational ExponentMilos KocicNo ratings yet
- Week1 2Document45 pagesWeek1 2Jonathan CasillaNo ratings yet
- Lesson 18 - CorrelationDocument3 pagesLesson 18 - CorrelationrinnagosakiNo ratings yet
- The Standard Deviation and VarianceDocument14 pagesThe Standard Deviation and VarianceCharlie BautistaNo ratings yet
- PsetDocument4 pagesPsetRalph Moses PadillaNo ratings yet
- 3a. WALLIS FORMULADocument8 pages3a. WALLIS FORMULAMildred Cardenas BañezNo ratings yet
- Multipl Icac I OnesDocument52 pagesMultipl Icac I OnesZeroCool McGregorNo ratings yet
- SLMNA4 11 EcoB 07 Correlation GoutamDocument33 pagesSLMNA4 11 EcoB 07 Correlation GoutamGoutam DasNo ratings yet
- Deciles and PercentilesDocument23 pagesDeciles and PercentilesPrecious Ingrid Dolor DenostaNo ratings yet
- 7.8 NotesDocument2 pages7.8 NotesZACKARY MCCOYNo ratings yet
- UDAU M6 Correlation & RegressionDocument26 pagesUDAU M6 Correlation & RegressionAlizah BucotNo ratings yet
- Chapter 6 - 2020Document62 pagesChapter 6 - 2020Nga Ying WuNo ratings yet
- Parametric AssignmentDocument75 pagesParametric Assignmentsundarismails544No ratings yet
- Grade 10 (Quartile)Document21 pagesGrade 10 (Quartile)Roqui M. Gonzaga100% (2)
- Spearman Rank Correlation Coefficient: Jennyrose Magbanua LacsintoDocument19 pagesSpearman Rank Correlation Coefficient: Jennyrose Magbanua LacsintoJennyrose Magbanua - LacsintoNo ratings yet
- Assignment 2 - 20376005 - BTC507Document13 pagesAssignment 2 - 20376005 - BTC507SIM ProteinNo ratings yet
- Exercise04 Statistics ANSWERSDocument2 pagesExercise04 Statistics ANSWERSAkhilaNo ratings yet
- Module 9 Module On Finding Derivatives Using Differentation RulesDocument28 pagesModule 9 Module On Finding Derivatives Using Differentation RulesFor sell account Pubg newstateNo ratings yet
- Num470s Assignment 1 MemoDocument2 pagesNum470s Assignment 1 MemogloryNo ratings yet
- QBookSolutionHead QueueingDocument248 pagesQBookSolutionHead QueueingOugni ChakrabortyNo ratings yet
- Index Laws Higher AnswersDocument5 pagesIndex Laws Higher AnswersFatuhu Abba dandagoNo ratings yet
- Unlike Horizontal Easy 1Document2 pagesUnlike Horizontal Easy 1MachelMDotAlexanderNo ratings yet
- Multiple Regression AnalysisDocument3 pagesMultiple Regression AnalysisAleenaNo ratings yet
- Pearson and CorrelationDocument8 pagesPearson and CorrelationEunice OrtileNo ratings yet
- Lecture 14B T Test IndDocument5 pagesLecture 14B T Test IndJane MorgateNo ratings yet
- Student ParticularsDocument12 pagesStudent ParticularsSashikala GarnaisonNo ratings yet
- Sociology 592 - Research Statistics I Exam 1 Answer Key September 28, 2001Document7 pagesSociology 592 - Research Statistics I Exam 1 Answer Key September 28, 2001stephen562001No ratings yet
- Geometric SequencesDocument5 pagesGeometric SequencesMarvin DizonNo ratings yet
- Class 1Document15 pagesClass 1eisha123No ratings yet
- Pak 6Document5 pagesPak 6Zahid ButtNo ratings yet
- 12 Stat2 Exercise Set 12 SolutionsDocument4 pages12 Stat2 Exercise Set 12 SolutionsVivek PoddarNo ratings yet
- Math Week 9 With Template1Document3 pagesMath Week 9 With Template1Ken De LeonNo ratings yet
- Multiplication Tables and Flashcards: Times Tables for ChildrenFrom EverandMultiplication Tables and Flashcards: Times Tables for ChildrenRating: 4 out of 5 stars4/5 (1)
- 81-03-0094-00ga General Assembly, X400-5D With FlangeDocument1 page81-03-0094-00ga General Assembly, X400-5D With FlangeMuthukumar RadhakrishnanNo ratings yet
- Systematic and Integrative Literature ReviewDocument6 pagesSystematic and Integrative Literature Reviewgw2cy6nx100% (1)
- Thermaline 4900 PDSDocument4 pagesThermaline 4900 PDSDuongthithuydungNo ratings yet
- 13.375 CASING Tally KH #C Wspace OutDocument14 pages13.375 CASING Tally KH #C Wspace OutnabiNo ratings yet
- Iec 61000-2-5-2017 TR PDFDocument150 pagesIec 61000-2-5-2017 TR PDFMehdi MakarovNo ratings yet
- MOT - Week 14 - Assignment - Group 7Document10 pagesMOT - Week 14 - Assignment - Group 7vian100% (2)
- Datasheet-LINX 100 101Document2 pagesDatasheet-LINX 100 101Guillermo Andres García MoraNo ratings yet
- G Force InstructionsDocument17 pagesG Force Instructions주형준No ratings yet
- Jones 1984 ReviewDocument3 pagesJones 1984 ReviewLucas MartinezNo ratings yet
- Lab 9 - Motion of FluidsDocument8 pagesLab 9 - Motion of Fluidsconstantine1106No ratings yet
- General Management: Professional Certificate Program in From IIM KozhikodeDocument9 pagesGeneral Management: Professional Certificate Program in From IIM KozhikodeNirmalya SenNo ratings yet
- PH Coagulation Tank Structural PDFDocument2 pagesPH Coagulation Tank Structural PDFBenderlip CortezNo ratings yet
- D73244GC20 SGDocument316 pagesD73244GC20 SGDjebrani AzizNo ratings yet
- VW (DTC) 968590155502 20221111202701Document2 pagesVW (DTC) 968590155502 20221111202701Abu BakkerNo ratings yet
- Ptrobot Api: Dll-Based Application Programming InterfaceDocument51 pagesPtrobot Api: Dll-Based Application Programming InterfaceDjvionico PerezNo ratings yet
- Specifications of Checkpoint VPNDocument1 pageSpecifications of Checkpoint VPNvijay6996No ratings yet
- Manual de Bop Doble RamDocument30 pagesManual de Bop Doble RamAndres Paul (paultgt)No ratings yet
- Complinace CBD Towers Scope (SM6)Document26 pagesComplinace CBD Towers Scope (SM6)Li LiuNo ratings yet
- Series N Hydro Pneumatic Press Cylinder PDFDocument11 pagesSeries N Hydro Pneumatic Press Cylinder PDFranjith sanNo ratings yet
- Induction Cooker PDFDocument2 pagesInduction Cooker PDFthienhayenNo ratings yet
- Business Analytics - The Science of Data Driven Decision MakingDocument55 pagesBusiness Analytics - The Science of Data Driven Decision Makingmathewsujith31No ratings yet
- DNV GL Transition Faster Webinar Series - Green HydrogenDocument54 pagesDNV GL Transition Faster Webinar Series - Green HydrogenPatricio NeffaNo ratings yet
- BSBLDR601 Project PortfolioDocument11 pagesBSBLDR601 Project PortfolioBhanu AUGMENT0% (2)
- COMPRO PT Elning Heksa Karya - 2021 UpdatedDocument24 pagesCOMPRO PT Elning Heksa Karya - 2021 UpdatedEngineering AstonNo ratings yet
- Unit 7 Manipulating Light: What Will Participants Learn?Document14 pagesUnit 7 Manipulating Light: What Will Participants Learn?sutebakoNo ratings yet
- Social Media Analytics AssignmentDocument9 pagesSocial Media Analytics AssignmentVarun SinhaNo ratings yet
- Tirth Hygiene Technology Private Limted 3Document1 pageTirth Hygiene Technology Private Limted 3PANKAJA KUMAR ROUTNo ratings yet
- Elegant Plants Research Poster by SlidesgoDocument26 pagesElegant Plants Research Poster by SlidesgoAfifah Nisa RahmadaniNo ratings yet
- Floating Windmill .Main File PDFDocument23 pagesFloating Windmill .Main File PDFmd inam ul hasan safwanNo ratings yet
- Practice Questions FinalDocument4 pagesPractice Questions FinaljameeshudsonNo ratings yet