You might also like
- Super Mario 3D Land Prima GuideDocument224 pagesSuper Mario 3D Land Prima Guideyann lopes100% (1)
- Fake News Detection Using Machine LearningDocument4 pagesFake News Detection Using Machine LearningEditor IJTSRDNo ratings yet
- Cost and Schedule Integration PDFDocument39 pagesCost and Schedule Integration PDFEbrenonNo ratings yet
- 2019 - 2 - Fake News Detection On Social Media Using Geometric Deep LearningDocument15 pages2019 - 2 - Fake News Detection On Social Media Using Geometric Deep LearningHassan AliNo ratings yet
- Fake News Detection Using Machine LearningDocument11 pagesFake News Detection Using Machine LearningIJARSCT Journal100% (1)
- Project Report On SonyDocument87 pagesProject Report On SonyManish Sharma68% (37)
- Fake Information Detection by Gaining Knowledge of The Usage of Machine LearningDocument5 pagesFake Information Detection by Gaining Knowledge of The Usage of Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Fake News Classification Using Machine Learning TechniquesDocument12 pagesFake News Classification Using Machine Learning TechniquesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Fake News Detection System Using Machine LearningDocument4 pagesFake News Detection System Using Machine LearningVelumani sNo ratings yet
- How Algorithms Create and Prevent Fake News: Exploring the Impacts of Social Media, Deepfakes, GPT-3, and MoreFrom EverandHow Algorithms Create and Prevent Fake News: Exploring the Impacts of Social Media, Deepfakes, GPT-3, and MoreNo ratings yet
- Fake News Detection Using Machine Learning: A ReviewDocument6 pagesFake News Detection Using Machine Learning: A ReviewIjaems JournalNo ratings yet
- 05 Alcatel 1660SM OperationDocument272 pages05 Alcatel 1660SM OperationChim Con100% (4)
- Fake News - 01Document5 pagesFake News - 01sudulagunta aksharaNo ratings yet
- Opening Report Final - 9 - 4 - 2020Document25 pagesOpening Report Final - 9 - 4 - 2020BENKEMCHI OussamaNo ratings yet
- Detection of Fake News Using Machine Learning AlgorithmsDocument7 pagesDetection of Fake News Using Machine Learning AlgorithmsIJRASETPublicationsNo ratings yet
- Transformer-Based Approach Fake News Detection Based On News Content and Social ContextsDocument28 pagesTransformer-Based Approach Fake News Detection Based On News Content and Social Contextsyazhini shanmugamNo ratings yet
- Advancements in Machine Learning For Combatting Misinformation: A Comprehensive Analysis of Fake News Detection StrategiesDocument4 pagesAdvancements in Machine Learning For Combatting Misinformation: A Comprehensive Analysis of Fake News Detection StrategiesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Zhang2019 PDFDocument17 pagesZhang2019 PDFVatsal PatelNo ratings yet
- Fake News Detection Based On Word and Document Embedding Using Machine Learning ClassifiersDocument11 pagesFake News Detection Based On Word and Document Embedding Using Machine Learning ClassifiersFarid Ali MousaNo ratings yet
- A Literature Survey On Misinformation Flagging SystemDocument9 pagesA Literature Survey On Misinformation Flagging SystemIJRASETPublicationsNo ratings yet
- 1 s2.0 S2405844024012751 MainDocument12 pages1 s2.0 S2405844024012751 Maintheboringboy5972No ratings yet
- An Enhanced Method For Detecting Fake NeDocument19 pagesAn Enhanced Method For Detecting Fake Nealperen.unal89No ratings yet
- 2-Convolutional Neural Network With Margin Loss For Fake News DetectionDocument12 pages2-Convolutional Neural Network With Margin Loss For Fake News DetectionMr. Saqib UbaidNo ratings yet
- Fake News Detection Based On Word and Document Embedding Using Machine Learning ClassifiersDocument12 pagesFake News Detection Based On Word and Document Embedding Using Machine Learning ClassifiersMahrukh ZubairNo ratings yet
- Aimll Report Fake News DetectionDocument27 pagesAimll Report Fake News DetectionKarna JaswanthNo ratings yet
- Classification and Analysis On Fake News in Social Media Using Machine LearningDocument10 pagesClassification and Analysis On Fake News in Social Media Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Fake News Detection Using NLPDocument9 pagesFake News Detection Using NLPIJRASETPublicationsNo ratings yet
- Fake News Detection Using Deep LearningDocument10 pagesFake News Detection Using Deep LearningIJRASETPublicationsNo ratings yet
- ICDM WorkshopDocument10 pagesICDM WorkshopJordan FernandezNo ratings yet
- Detection of Hyperpartisan News Articles - 2022 - International Journal of InfoDocument10 pagesDetection of Hyperpartisan News Articles - 2022 - International Journal of Infoᕮᖇᓰᔕ ᕮᙀᗩNo ratings yet
- Santhosh Kumar 2021 J. Phys. Conf. Ser. 1916 012235Document10 pagesSanthosh Kumar 2021 J. Phys. Conf. Ser. 1916 012235Kk DataNo ratings yet
- Prevention of Spreading Fake News by Using Two-Point Processes Based InterventionDocument6 pagesPrevention of Spreading Fake News by Using Two-Point Processes Based InterventionKeshav BhumarajuNo ratings yet
- Identifying Fake News Using Real Time AnalyticsDocument9 pagesIdentifying Fake News Using Real Time AnalyticsIJRASETPublicationsNo ratings yet
- Fake News Detection JournalDocument10 pagesFake News Detection JournalAkhilaNo ratings yet
- Face Mask Detection Using Deep LearningDocument31 pagesFace Mask Detection Using Deep Learningfathima thNo ratings yet
- News Summarization and AuthenticationDocument3 pagesNews Summarization and AuthenticationShashaNo ratings yet
- SynopsisDocument8 pagesSynopsisTina ShahNo ratings yet
- Title:: Fake News Detection Techniques On Social Media: A SurveyDocument1 pageTitle:: Fake News Detection Techniques On Social Media: A Surveysehrish safdarNo ratings yet
- Multi-Label Classification of Fake News On Social-MediaDocument5 pagesMulti-Label Classification of Fake News On Social-MediaInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- A Benchmark Study On Machine Learning Methods For Fake News DetectionDocument14 pagesA Benchmark Study On Machine Learning Methods For Fake News DetectionTouqeer Ul IslamNo ratings yet
- Fake News DetetcionDocument16 pagesFake News DetetcionnishaNo ratings yet
- Multi-Class Fake News Detection Using Online Learning ApproachDocument10 pagesMulti-Class Fake News Detection Using Online Learning ApproachIJRASETPublicationsNo ratings yet
- Evaluating Deep Learning Approaches For Covid19 Fake News DetectionDocument11 pagesEvaluating Deep Learning Approaches For Covid19 Fake News DetectionShubham N/ANo ratings yet
- Fake News Detection Using Python and Machine LearningDocument6 pagesFake News Detection Using Python and Machine Learningharini tNo ratings yet
- "Fake News" Is Not Simply False Information: A Concept Explication and Taxonomy of Online ContentDocument33 pages"Fake News" Is Not Simply False Information: A Concept Explication and Taxonomy of Online Contentفاطمة هاشم الأمينNo ratings yet
- Irjet V6i154 PDFDocument2 pagesIrjet V6i154 PDFANSHUL SHARMANo ratings yet
- Fake News Detection Using Source Information and Bayes ClassifierDocument7 pagesFake News Detection Using Source Information and Bayes ClassifierNafisa SadafNo ratings yet
- Analysis of Rumour Detection Using Deep Learning Methods On Social MediaDocument10 pagesAnalysis of Rumour Detection Using Deep Learning Methods On Social MediaInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Mathematics 11 01992 v2Document21 pagesMathematics 11 01992 v2Mohammed SultanNo ratings yet
- Machine Learning For The Classification of Fake NewsDocument4 pagesMachine Learning For The Classification of Fake NewsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Hybrid Deep Learning Model For Automatic Fake News DetectionDocument11 pagesHybrid Deep Learning Model For Automatic Fake News Detectionrushendra.umbNo ratings yet
- Kuwait CSDocument8 pagesKuwait CSErhueh Kester AghoghoNo ratings yet
- Fake News Detection Using Machine Learning AlgorithmsDocument10 pagesFake News Detection Using Machine Learning Algorithms121710306055 THAPPETA ASHOK KUMAR REDDYNo ratings yet
- I Jeter 0210122022Document5 pagesI Jeter 0210122022WARSE JournalsNo ratings yet
- CR.10.Misinformation in Social Media - FinalDocument11 pagesCR.10.Misinformation in Social Media - Finalaist.eNo ratings yet
- TARPDocument21 pagesTARPadityaNo ratings yet
- A Novel Approach For Detection of Fake News Using Long Short Term Memory (LSTM)Document5 pagesA Novel Approach For Detection of Fake News Using Long Short Term Memory (LSTM)WARSE JournalsNo ratings yet
- Reseach Paper-G3Document4 pagesReseach Paper-G3Pråshãnt ShärmãNo ratings yet
- Fake News Classification Using Transformer Based Enhanced LSTM and BERTDocument8 pagesFake News Classification Using Transformer Based Enhanced LSTM and BERTDonlot AjaNo ratings yet
- Unlink The Link Between COVID-19 and 5G Networks: An NLP and SNA Based ApproachDocument11 pagesUnlink The Link Between COVID-19 and 5G Networks: An NLP and SNA Based Approachshilpeepatil21_69188No ratings yet
- Automated COVID-19 Misinformation Checking System Using Encoder Representation With Deep Learning ModelsDocument8 pagesAutomated COVID-19 Misinformation Checking System Using Encoder Representation With Deep Learning ModelsIAES IJAINo ratings yet
- Fake News Detection Using Naïve Bayes and Long Short Term Memory AlgorithmsDocument7 pagesFake News Detection Using Naïve Bayes and Long Short Term Memory AlgorithmsIAES IJAINo ratings yet
- Fake Content DetectionDocument18 pagesFake Content DetectionTommy VercettiNo ratings yet
- FND Naive Bayes ClassifierDocument7 pagesFND Naive Bayes ClassifierShifanaNo ratings yet
- Narula Institute of Technology: TitleDocument55 pagesNarula Institute of Technology: TitleBasant Kumar PanditNo ratings yet
- Ebook Ebook PDF Practice of Computing Using Python The 3rd Edition PDFDocument41 pagesEbook Ebook PDF Practice of Computing Using Python The 3rd Edition PDFbarbara.coakley46697% (35)
- Sri Paramakalyani College: AlwarkurichiDocument18 pagesSri Paramakalyani College: AlwarkurichiSindhuja SNo ratings yet
- Movie Ticket Booking SystemDocument15 pagesMovie Ticket Booking Systemsr8703101No ratings yet
- INB 400 (GOOGLE Case - Mid Assignment)Document21 pagesINB 400 (GOOGLE Case - Mid Assignment)Sohel AhmedNo ratings yet
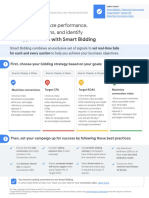
- (One-Sheeter) (External) Smart Bidding - Best Practices, Optimization, and Troubleshooting Q2'19 (En - US), Go - Sb-Bestpractices-1sDocument4 pages(One-Sheeter) (External) Smart Bidding - Best Practices, Optimization, and Troubleshooting Q2'19 (En - US), Go - Sb-Bestpractices-1sShoobaNo ratings yet
- Diya Shaji S7 Ece Roll No: 22Document8 pagesDiya Shaji S7 Ece Roll No: 22Diya ShajiNo ratings yet
- Bo de 200 Cau Hoi On Thi ISTQB FoundationDocument85 pagesBo de 200 Cau Hoi On Thi ISTQB FoundationHoài HàNo ratings yet
- 1P108-00 02 E2215cs062 20160311 PDFDocument29 pages1P108-00 02 E2215cs062 20160311 PDFRachele DaniNo ratings yet
- Tubebuddy Affiliate Handbook: Welcome To The Team!Document20 pagesTubebuddy Affiliate Handbook: Welcome To The Team!cecep encepNo ratings yet
- Lexar DataShield Quick Start Guide For WindowsDocument44 pagesLexar DataShield Quick Start Guide For WindowsAnonymous pNhxK0FKNo ratings yet
- New GT02 (MT61) USER MANUALDocument11 pagesNew GT02 (MT61) USER MANUALCarlos CastilloNo ratings yet
- Intro Buddy Session 2023 - EBE, IB BA EOR and BA - PDF - 0Document19 pagesIntro Buddy Session 2023 - EBE, IB BA EOR and BA - PDF - 0Syed Adib IslamNo ratings yet
- DX DiagDocument37 pagesDX DiagcepdanieNo ratings yet
- Teledyne FLIR Product Returns ProcessDocument3 pagesTeledyne FLIR Product Returns ProcessYeung Chau HoNo ratings yet
- Oracle 19c RAC Step by Step Part 1 Installation of RHEL 7.8Document9 pagesOracle 19c RAC Step by Step Part 1 Installation of RHEL 7.8praveenkumarappsdbNo ratings yet
- Configuring BIG IP ASM ApplicationSecurityManager1Document7 pagesConfiguring BIG IP ASM ApplicationSecurityManager1sureshNo ratings yet
- Installation of VIGODocument11 pagesInstallation of VIGOAhmedhassan KhanNo ratings yet
- Unit 2 (C++) - Data Types and VariablesDocument43 pagesUnit 2 (C++) - Data Types and VariablesAlex ogNo ratings yet
- CCS (CCA) RULES, 1965 - Department of Personnel & TrainingDocument126 pagesCCS (CCA) RULES, 1965 - Department of Personnel & TrainingBhargavNo ratings yet
- Unit 1 Computer Applications: Picture 1.1Document10 pagesUnit 1 Computer Applications: Picture 1.1Faris IkhlasulNo ratings yet
- Z01410040120174171KSI-PT09-10-E-Business and E-Commerce (L)Document34 pagesZ01410040120174171KSI-PT09-10-E-Business and E-Commerce (L)kristabella stNo ratings yet
- Divide-and-Conquer Technique:: Maximum Subarray ProblemDocument16 pagesDivide-and-Conquer Technique:: Maximum Subarray ProblemFaria Farhad MimNo ratings yet
- Iot Technology Disruptions A Gartner Trend Insight Report 331334Document17 pagesIot Technology Disruptions A Gartner Trend Insight Report 331334DebanandNo ratings yet
- SPPU High Performance ComputingDocument12 pagesSPPU High Performance ComputingGovind RajputNo ratings yet
- DocumentationDocument3,516 pagesDocumentationJoseAvilesNo ratings yet