You might also like
- LegobaseDocument45 pagesLegobaseMoonNo ratings yet
- An Environment For Dynamic Component Composition For Efficient Co-DesignDocument8 pagesAn Environment For Dynamic Component Composition For Efficient Co-DesignLe'Anne LapidanteNo ratings yet
- Mambo - A Full System Simulator For The Powerpc ArchitectureDocument5 pagesMambo - A Full System Simulator For The Powerpc ArchitecturegarciamaxNo ratings yet
- Paper Title (Use Style: Paper Title) : Subtitle As Needed (Paper Subtitle)Document4 pagesPaper Title (Use Style: Paper Title) : Subtitle As Needed (Paper Subtitle)chow sajNo ratings yet
- Memory Model For Multithreaded C++: Andrei Alexandrescu Hans Boehm Kevlin Henney Doug Lea Bill PughDocument6 pagesMemory Model For Multithreaded C++: Andrei Alexandrescu Hans Boehm Kevlin Henney Doug Lea Bill PughAbhishek DubeyNo ratings yet
- Electricity Bill Management System: Software Description A. JavaDocument7 pagesElectricity Bill Management System: Software Description A. JavaShivansh ChauhanNo ratings yet
- Creating HWSW Co-Designed MPSoPCs From High Level Programming ModelsDocument7 pagesCreating HWSW Co-Designed MPSoPCs From High Level Programming ModelsRamon NepomucenoNo ratings yet
- Online Bus Ticket Reservation SystemDocument19 pagesOnline Bus Ticket Reservation Systemasvasanthkm63% (8)
- High-Level Languages For Low-Level Programming: Thesis Proposal First Year ReportDocument17 pagesHigh-Level Languages For Low-Level Programming: Thesis Proposal First Year ReportMohammed RammehNo ratings yet
- Wrapup: What Have We Learnt?Document5 pagesWrapup: What Have We Learnt?Zachry WangNo ratings yet
- Online Bus Ticket Reservation SystemDocument19 pagesOnline Bus Ticket Reservation SystemArpita Jaiswal100% (1)
- Sig: A Methodology For The Study of ArchitectureDocument6 pagesSig: A Methodology For The Study of ArchitectureAdamo GhirardelliNo ratings yet
- Inferno (1) .PsDocument4 pagesInferno (1) .PsAbdul DakkakNo ratings yet
- Pldi 16Document16 pagesPldi 16Shadow ElwellNo ratings yet
- Picothreads: Lightweight Threads in Java: 1.1 Event-Based Programming vs. Thread ProgrammingDocument8 pagesPicothreads: Lightweight Threads in Java: 1.1 Event-Based Programming vs. Thread Programminganon-679511No ratings yet
- Benchmarking Apache Kafka - 2 Million Writes Per Second (On Three Cheap Machines) - LinkedIn EngineeringDocument9 pagesBenchmarking Apache Kafka - 2 Million Writes Per Second (On Three Cheap Machines) - LinkedIn EngineeringFinigan JoyceNo ratings yet
- Oss - 2023 - Claimed - 2307.06824Document17 pagesOss - 2023 - Claimed - 2307.06824Jagadeesh MNo ratings yet
- Deep ArchitectureDocument65 pagesDeep ArchitectureSoham MullickNo ratings yet
- Scrap Your Boilerplate A Practical Design Pattern PDFDocument14 pagesScrap Your Boilerplate A Practical Design Pattern PDFBruno PaternostroNo ratings yet
- Amp ViiiDocument3 pagesAmp ViiiAnil Kumar GonaNo ratings yet
- Heyhyid: Emulation of Cache CoherenceDocument5 pagesHeyhyid: Emulation of Cache CoherenceAdamo GhirardelliNo ratings yet
- AMP Software Frameworks 01Document19 pagesAMP Software Frameworks 01Sayani PalNo ratings yet
- Ompss@Fpga Framework For High Performance Fpga ComputingDocument14 pagesOmpss@Fpga Framework For High Performance Fpga ComputingRamon NepomucenoNo ratings yet
- Optimization of Computer Programs in CDocument2 pagesOptimization of Computer Programs in CfraudianoneNo ratings yet
- GPU Programming in Rust: Implementing High-Level Abstractions in A Systems-Level LanguageDocument10 pagesGPU Programming in Rust: Implementing High-Level Abstractions in A Systems-Level Language13arvinNo ratings yet
- Task and Data Distribution in Hybrid Parallel SystemsDocument9 pagesTask and Data Distribution in Hybrid Parallel SystemsAlex AdamiteiNo ratings yet
- Chisel Dac 2012 CorrectedDocument10 pagesChisel Dac 2012 Correctedgoxomi7969No ratings yet
- How Do: Evolving Operating Systems and Architectures: Kernel Implementors Catch Up?Document4 pagesHow Do: Evolving Operating Systems and Architectures: Kernel Implementors Catch Up?Ibraheem FaheemNo ratings yet
- PG Diploma in Embedded Systems Design (PG-DESD) Course FocusDocument7 pagesPG Diploma in Embedded Systems Design (PG-DESD) Course Focusabhijeetv2No ratings yet
- Cloud Computing: Project WorkDocument34 pagesCloud Computing: Project WorkHoimanti DuttaNo ratings yet
- Dynamic Applications From The Ground Up: Don Stewart Manuel M. T. ChakravartyDocument12 pagesDynamic Applications From The Ground Up: Don Stewart Manuel M. T. ChakravartyosakagroupkaraNo ratings yet
- Lambda Vs Kappa3Document9 pagesLambda Vs Kappa3RajNo ratings yet
- Grid Computing: Techniques and Applications Barry Wilkinson: 6.1 6.2 Job SubmissionDocument30 pagesGrid Computing: Techniques and Applications Barry Wilkinson: 6.1 6.2 Job SubmissionKali DasNo ratings yet
- Chapter 1Document25 pagesChapter 1chinmayNo ratings yet
- 2004 Ncta Technical PapersDocument313 pages2004 Ncta Technical PapersPavel GurovNo ratings yet
- Low Latency JavaDocument5 pagesLow Latency Javarajesh2kNo ratings yet
- Recognizing The ImportanceDocument2 pagesRecognizing The ImportanceRadha GuptaNo ratings yet
- Network CICD Part 2 Automated Testing With Robot Framework Library For Arista DevicesDocument9 pagesNetwork CICD Part 2 Automated Testing With Robot Framework Library For Arista DevicesegondragonNo ratings yet
- Assignment 01Document2 pagesAssignment 01Rakibul Hasan Ridoy 1731339No ratings yet
- The Revolution in Database Architecture: Jim Gray Microsoft ResearchDocument5 pagesThe Revolution in Database Architecture: Jim Gray Microsoft ResearchvgopikNo ratings yet
- Doree A Methodology For The Investigation of IPv4Document6 pagesDoree A Methodology For The Investigation of IPv4Henry PabloNo ratings yet
- Wearable Modalities For Web Services: JackoDocument6 pagesWearable Modalities For Web Services: JackomaxxflyyNo ratings yet
- Xu Sosp09Document16 pagesXu Sosp09Mohit AgarwalNo ratings yet
- 037 Query Optimization in Oracle (9 Oldal)Document9 pages037 Query Optimization in Oracle (9 Oldal)Eid TahirNo ratings yet
- On The Study of B-TreesDocument5 pagesOn The Study of B-TreesAdamo GhirardelliNo ratings yet
- ProjectDocument15 pagesProjectiamanviNo ratings yet
- 1214 Newsletter Vol 2 V3Document50 pages1214 Newsletter Vol 2 V3Sahil ChauhanNo ratings yet
- Unit - 3Document42 pagesUnit - 3hejoj76652No ratings yet
- Developing Embedded Software in JavaDocument10 pagesDeveloping Embedded Software in JavalazarNo ratings yet
- Serverless Computing: Design, Implementation, and PerformanceDocument6 pagesServerless Computing: Design, Implementation, and Performanceabhishek4vishwakar-1No ratings yet
- How To Write Shared Libraries: Ulrich Drepper Red Hat, IncDocument45 pagesHow To Write Shared Libraries: Ulrich Drepper Red Hat, IncMehmet DemirNo ratings yet
- Scimakelatex 17734 Michael+JacksonDocument7 pagesScimakelatex 17734 Michael+JacksonmaxxflyyNo ratings yet
- J2 HWProgramUsingC Microproce Microprogr 94Document5 pagesJ2 HWProgramUsingC Microproce Microprogr 94Emejuru ChukwuemekaNo ratings yet
- Batch Processing With J2EE Design, Architecture and PerformanceDocument137 pagesBatch Processing With J2EE Design, Architecture and PerformanceRabi ShankarNo ratings yet
- Tristram FP 443Document6 pagesTristram FP 443sandokanaboliNo ratings yet
- FPGA Genreal PaperDocument7 pagesFPGA Genreal PaperParth SomkuwarNo ratings yet
- Evan Cabral Methods PaperDocument6 pagesEvan Cabral Methods PaperJohnNo ratings yet
- Java Theory and Practice:: Stick A Fork in It, Part 1Document8 pagesJava Theory and Practice:: Stick A Fork in It, Part 1Dipesh GuptaNo ratings yet
- Evaluating Online Algorithms and Virtual MachinesDocument5 pagesEvaluating Online Algorithms and Virtual MachinesAdamo GhirardelliNo ratings yet
- Penerapan Prinsip Rule of Reason Pada Putusan Perkara Nomor 08/KPPU-I/2020 Tentang Dugaan Praktik Diskriminasi Antara Telkom-Telkomsel Dan NetflixDocument14 pagesPenerapan Prinsip Rule of Reason Pada Putusan Perkara Nomor 08/KPPU-I/2020 Tentang Dugaan Praktik Diskriminasi Antara Telkom-Telkomsel Dan NetflixMarrauNo ratings yet
- Royal FamilyDocument38 pagesRoyal FamilyMarrauNo ratings yet
- Royal FamilyDocument18 pagesRoyal FamilyMarrauNo ratings yet
- Q. Exp.: A To NerveDocument10 pagesQ. Exp.: A To NerveMarrauNo ratings yet
- Toxins 14 00576 v2Document34 pagesToxins 14 00576 v2MarrauNo ratings yet
- Molecules TNTDocument9 pagesMolecules TNTMarrauNo ratings yet
- 2:4:6-Trinitrotoluene: 0-0114N-Ba (OH)Document16 pages2:4:6-Trinitrotoluene: 0-0114N-Ba (OH)MarrauNo ratings yet
- Treatment of PainDocument5 pagesTreatment of PainMarrauNo ratings yet
- Examining Explosives Handling Sensitivity of Trinitrotoluene (TNT) With Different Particle SizesDocument7 pagesExamining Explosives Handling Sensitivity of Trinitrotoluene (TNT) With Different Particle SizesMarrauNo ratings yet
- Aspirin: Damocles Gruppe C Daniel Deckenbach Bilal Danisman Benedict Depp Scotty CobbDocument7 pagesAspirin: Damocles Gruppe C Daniel Deckenbach Bilal Danisman Benedict Depp Scotty CobbMarrauNo ratings yet
- The Synthesis, Properties, & Application of Salicylic Acid in The Treatment of AcneDocument13 pagesThe Synthesis, Properties, & Application of Salicylic Acid in The Treatment of AcneMarrauNo ratings yet
- Effect Salicylic Acid To LettuceDocument6 pagesEffect Salicylic Acid To LettuceMarrauNo ratings yet
- Tetrodotoxin: TTX: BackgroundDocument12 pagesTetrodotoxin: TTX: BackgroundMarrauNo ratings yet
- Partial Characterization of Tetrodotoxin-Binding Component From Nerve MembraneDocument4 pagesPartial Characterization of Tetrodotoxin-Binding Component From Nerve MembraneMarrauNo ratings yet
- Vitamin B3 at A Glance: CancerDocument3 pagesVitamin B3 at A Glance: CancerMarrauNo ratings yet
- Niacinamide Salicylate ComplexDocument4 pagesNiacinamide Salicylate ComplexMarrauNo ratings yet
- Nutritional Medicine and Diet Care: ClinmedDocument5 pagesNutritional Medicine and Diet Care: ClinmedMarrauNo ratings yet
- Salicylic AcidDocument5 pagesSalicylic AcidMarrauNo ratings yet
- Retinol in CosmeticsDocument204 pagesRetinol in CosmeticsMarrauNo ratings yet
- Breast CancerDocument36 pagesBreast CancerMarrauNo ratings yet
- Sunscreen Market AnalysisDocument43 pagesSunscreen Market AnalysisMarrauNo ratings yet
- Biosyntesis of RetinolDocument5 pagesBiosyntesis of RetinolMarrauNo ratings yet
- Public Law 113-195 113th Congress An ActDocument18 pagesPublic Law 113-195 113th Congress An ActMarrauNo ratings yet
- Retinol Product InformationDocument3 pagesRetinol Product InformationMarrauNo ratings yet
- 2dot3 AgingSkin PhysRes1 BellemereGDocument10 pages2dot3 AgingSkin PhysRes1 BellemereGMarrauNo ratings yet
- It First Into Retinoic Acid. Retinyl Palmitate: Layers Up, It Is Safe To Use With AhasDocument2 pagesIt First Into Retinoic Acid. Retinyl Palmitate: Layers Up, It Is Safe To Use With AhasMarrauNo ratings yet
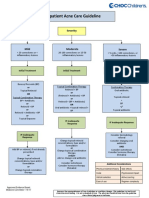
- Outpatient Acne Care Guideline: SeverityDocument5 pagesOutpatient Acne Care Guideline: SeverityMarrauNo ratings yet
- ICRI Sunscreen 2Document21 pagesICRI Sunscreen 2MarrauNo ratings yet
- System ProgramingDocument15 pagesSystem ProgramingManish YadavNo ratings yet
- ECE 250 Algorithms and Data StructuresDocument62 pagesECE 250 Algorithms and Data StructuresRubab AnamNo ratings yet
- CSE-SS Unit 3 QBDocument43 pagesCSE-SS Unit 3 QBJKNo ratings yet
- EulaDocument3 pagesEulaRista PardedeNo ratings yet
- ReadmeDocument4 pagesReadmeOmar RodriguezNo ratings yet
- Net Customisation User GuideDocument88 pagesNet Customisation User GuideAnant JadhavNo ratings yet
- PGDIT - Symbiosis (SCDL) ... Ents and Sample Papers.Document1 pagePGDIT - Symbiosis (SCDL) ... Ents and Sample Papers.Addy SandyNo ratings yet
- Java Source CodeDocument1,145 pagesJava Source CodeAlfredo EcoNo ratings yet
- Movie World Portal ReportDocument59 pagesMovie World Portal ReportAnonymous gEbaYSNo ratings yet
- Gs FontsDocument21 pagesGs FontscitracandikaNo ratings yet
- Java Coding Style by Achut ReddyDocument26 pagesJava Coding Style by Achut ReddyAdarsh100% (4)
- FlowchartsDocument24 pagesFlowchartsvladimiraccess86% (7)
- Ai Chess DocumentationDocument45 pagesAi Chess DocumentationCrazyYT Gaming channelNo ratings yet
- Introduction To C ProgrammingDocument27 pagesIntroduction To C ProgrammingHitesh SinghNo ratings yet
- Abstract Syntax Tree Based Clone Detection For Java ProjectsDocument3 pagesAbstract Syntax Tree Based Clone Detection For Java ProjectsIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNo ratings yet
- Mil STD 31000Document26 pagesMil STD 31000João RegoNo ratings yet
- Python Project ReportDocument15 pagesPython Project ReportSakshi SonavaneNo ratings yet
- 3-Introduction To Open Source Software - OSS-04-Dec-2018Reference Material I - Unit - 1 - Part - 1Document18 pages3-Introduction To Open Source Software - OSS-04-Dec-2018Reference Material I - Unit - 1 - Part - 1SantaNo ratings yet
- Java Code Conventions: September 12, 1997Document8 pagesJava Code Conventions: September 12, 1997Hoa PhuongNo ratings yet
- SmartRF Flash Programmer 2 SLADocument6 pagesSmartRF Flash Programmer 2 SLAblitzulNo ratings yet
- SolverSDK UserGuideV11Document315 pagesSolverSDK UserGuideV11Javier Burbano ValenciaNo ratings yet
- SIMPACK 代码输出功能Document17 pagesSIMPACK 代码输出功能loeliang100% (1)
- SAP Exchange Infrastructure 3.0 - Best Practices For Naming Conventions PDFDocument20 pagesSAP Exchange Infrastructure 3.0 - Best Practices For Naming Conventions PDFsubraiNo ratings yet
- Coverity Prevent On The Symbian OS (English)Document32 pagesCoverity Prevent On The Symbian OS (English)SymbianNo ratings yet
- Csi 3131 Assign 1Document3 pagesCsi 3131 Assign 1aaa1235No ratings yet
- Source Code Plagiarism Detection SCPDet ADocument9 pagesSource Code Plagiarism Detection SCPDet APles RamadarNo ratings yet
- Java Code ConventionsDocument27 pagesJava Code ConventionsJonNo ratings yet
- FAL (2019-20) - CSE1004 - ELA - 119 - AP2019201000445 - Reference Material I - Week-1-2Document32 pagesFAL (2019-20) - CSE1004 - ELA - 119 - AP2019201000445 - Reference Material I - Week-1-2abhay chaudharyNo ratings yet
- What Is "Open Source" and Why Is It Important For Cryptocurrency and Open Blockchain Projects - Coin CenterDocument8 pagesWhat Is "Open Source" and Why Is It Important For Cryptocurrency and Open Blockchain Projects - Coin CenternakulpadalkarNo ratings yet
- Avaya Sesion Border Controller DeploymentDocument110 pagesAvaya Sesion Border Controller Deploymentcharly_detaNo ratings yet
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceFrom EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNo ratings yet
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleFrom EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleRating: 4 out of 5 stars4/5 (16)
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.From EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Rating: 5 out of 5 stars5/5 (34)
- Python for Beginners: A Crash Course Guide to Learn Python in 1 WeekFrom EverandPython for Beginners: A Crash Course Guide to Learn Python in 1 WeekRating: 4.5 out of 5 stars4.5/5 (7)
- Once Upon an Algorithm: How Stories Explain ComputingFrom EverandOnce Upon an Algorithm: How Stories Explain ComputingRating: 4 out of 5 stars4/5 (43)
- Microsoft 365 Guide to Success: 10 Books in 1 | Kick-start Your Career Learning the Key Information to Master Your Microsoft Office Files to Optimize Your Tasks & Surprise Your Colleagues | Access, Excel, OneDrive, Outlook, PowerPoint, Word, Teams, etc.From EverandMicrosoft 365 Guide to Success: 10 Books in 1 | Kick-start Your Career Learning the Key Information to Master Your Microsoft Office Files to Optimize Your Tasks & Surprise Your Colleagues | Access, Excel, OneDrive, Outlook, PowerPoint, Word, Teams, etc.Rating: 5 out of 5 stars5/5 (2)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Understanding Software: Max Kanat-Alexander on simplicity, coding, and how to suck less as a programmerFrom EverandUnderstanding Software: Max Kanat-Alexander on simplicity, coding, and how to suck less as a programmerRating: 4.5 out of 5 stars4.5/5 (44)
- How to Make a Video Game All By Yourself: 10 steps, just you and a computerFrom EverandHow to Make a Video Game All By Yourself: 10 steps, just you and a computerRating: 5 out of 5 stars5/5 (1)
- Clean Code: A Handbook of Agile Software CraftsmanshipFrom EverandClean Code: A Handbook of Agile Software CraftsmanshipRating: 5 out of 5 stars5/5 (13)
- Python Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionFrom EverandPython Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionRating: 5 out of 5 stars5/5 (2)
- Microsoft Excel Guide for Success: Transform Your Work with Microsoft Excel, Unleash Formulas, Functions, and Charts to Optimize Tasks and Surpass Expectations [II EDITION]From EverandMicrosoft Excel Guide for Success: Transform Your Work with Microsoft Excel, Unleash Formulas, Functions, and Charts to Optimize Tasks and Surpass Expectations [II EDITION]Rating: 5 out of 5 stars5/5 (2)
- Python Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)From EverandPython Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)Rating: 5 out of 5 stars5/5 (1)
- Microsoft PowerPoint Guide for Success: Learn in a Guided Way to Create, Edit & Format Your Presentations Documents to Visual Explain Your Projects & Surprise Your Bosses And Colleagues | Big Four Consulting Firms MethodFrom EverandMicrosoft PowerPoint Guide for Success: Learn in a Guided Way to Create, Edit & Format Your Presentations Documents to Visual Explain Your Projects & Surprise Your Bosses And Colleagues | Big Four Consulting Firms MethodRating: 5 out of 5 stars5/5 (3)
- Software Engineering at Google: Lessons Learned from Programming Over TimeFrom EverandSoftware Engineering at Google: Lessons Learned from Programming Over TimeRating: 4 out of 5 stars4/5 (11)
- A Slackers Guide to Coding with Python: Ultimate Beginners Guide to Learning Python QuickFrom EverandA Slackers Guide to Coding with Python: Ultimate Beginners Guide to Learning Python QuickNo ratings yet
- What Algorithms Want: Imagination in the Age of ComputingFrom EverandWhat Algorithms Want: Imagination in the Age of ComputingRating: 3.5 out of 5 stars3.5/5 (41)
- Coders at Work: Reflections on the Craft of ProgrammingFrom EverandCoders at Work: Reflections on the Craft of ProgrammingRating: 4 out of 5 stars4/5 (151)
- Fun Games with Scratch 3.0: Learn to Design High Performance, Interactive Games in Scratch (English Edition)From EverandFun Games with Scratch 3.0: Learn to Design High Performance, Interactive Games in Scratch (English Edition)No ratings yet