You might also like
- Operant ConditioningDocument32 pagesOperant ConditioningShulaman Graphics DesignNo ratings yet
- A319 - AWM - IntroductionDocument76 pagesA319 - AWM - Introductionklallali31100% (3)
- Disadvantage of Cash FlowDocument29 pagesDisadvantage of Cash FlowSoham DattaNo ratings yet
- Kumpulan 100 Soal TOEFL Written ExpressiDocument8 pagesKumpulan 100 Soal TOEFL Written ExpressiPuji AmbarNo ratings yet
- Understanding Culture, Society, and Politics Quarter 2 - Module 6 Social and Political StratificationDocument14 pagesUnderstanding Culture, Society, and Politics Quarter 2 - Module 6 Social and Political Stratificationaliza crisostomo100% (2)
- Personal Nursing Leadership PaperDocument7 pagesPersonal Nursing Leadership Paperapi-625175559No ratings yet
- EEG Brain Signal Classification for Epileptic Seizure Disorder DetectionFrom EverandEEG Brain Signal Classification for Epileptic Seizure Disorder DetectionNo ratings yet
- Warehouse Order ProcessingDocument67 pagesWarehouse Order ProcessingYogitha BalasubramanianNo ratings yet
- 4 Artificial Intelligence in Clinical MedicineDocument13 pages4 Artificial Intelligence in Clinical Medicineshirish gundalaNo ratings yet
- Pblished Paper 3771 - PDFDocument5 pagesPblished Paper 3771 - PDFHema Latha Krishna NairNo ratings yet
- Animal Detection Using Deep Learning AlgorithmDocument6 pagesAnimal Detection Using Deep Learning AlgorithmGhazal BilalNo ratings yet
- Symmetry: Identification of Apple Leaf Diseases Based On Deep Convolutional Neural NetworksDocument16 pagesSymmetry: Identification of Apple Leaf Diseases Based On Deep Convolutional Neural NetworksPradeep KumarNo ratings yet
- Thesis Report On Iris RecognitionDocument4 pagesThesis Report On Iris Recognitionafloaaffbkmmbx100% (2)
- Detection of Attention DeficitHyperactivity Disorder (ADHD)Document12 pagesDetection of Attention DeficitHyperactivity Disorder (ADHD)IJRASETPublicationsNo ratings yet
- Early Stage Alzheimer's Disease Diagnosis Method-2019Document4 pagesEarly Stage Alzheimer's Disease Diagnosis Method-2019divyaNo ratings yet
- Irjet V6i31160Document7 pagesIrjet V6i31160Ananya DhuriaNo ratings yet
- A New Weakly Supervised Deep Neural Network For Recognizing Alzheimer's DiseaseDocument12 pagesA New Weakly Supervised Deep Neural Network For Recognizing Alzheimer's DiseasepelodepuyaNo ratings yet
- A Hybrid Deep Spatio-Temporal Attention-Based Model For Parkinson's Disease Diagnosis Using Resting State EEG SignalsDocument21 pagesA Hybrid Deep Spatio-Temporal Attention-Based Model For Parkinson's Disease Diagnosis Using Resting State EEG SignalsJayant JhangianiNo ratings yet
- Parkinson's Disease Detection Using Machine Learning AlgorithmsDocument7 pagesParkinson's Disease Detection Using Machine Learning AlgorithmsIJRASETPublicationsNo ratings yet
- Real-Time Fine-Grained Air Quality Sensing Networks in Smart City: Design, Implementation and OptimizationDocument4 pagesReal-Time Fine-Grained Air Quality Sensing Networks in Smart City: Design, Implementation and OptimizationRoshan MNo ratings yet
- Deep Convolutional Neural Network Framework With Multi-Modal Fusion For Alzheimer's DetectionDocument13 pagesDeep Convolutional Neural Network Framework With Multi-Modal Fusion For Alzheimer's DetectionIJRES teamNo ratings yet
- Detection of Eye Contact With Deep Neural Networks Is As Accurate As Human ExpertsDocument28 pagesDetection of Eye Contact With Deep Neural Networks Is As Accurate As Human ExpertsZaidggg ggg GgitNo ratings yet
- Detecting Self-Stimulatory Behaviours For Autism Diagnosis: January 2015Document6 pagesDetecting Self-Stimulatory Behaviours For Autism Diagnosis: January 2015Ainna AldayNo ratings yet
- Ingénierie Des Systèmes D'information: Received: 18 March 2020 Accepted: 25 May 2020Document9 pagesIngénierie Des Systèmes D'information: Received: 18 March 2020 Accepted: 25 May 2020abirrazaNo ratings yet
- Activity Recognition in The Home Using A Hierarchal Framework With Object Usage DataDocument16 pagesActivity Recognition in The Home Using A Hierarchal Framework With Object Usage DataAmit GokhaleNo ratings yet
- Comparative Study of Machine Learning Algorithms For DiabetesDocument11 pagesComparative Study of Machine Learning Algorithms For DiabetesVivek DeshmukhNo ratings yet
- RUS Boost Tree Ensemble Classifiers For ODDocument7 pagesRUS Boost Tree Ensemble Classifiers For ODEsma ÖzelNo ratings yet
- Classification of Heart Disease Using K-Nearest Neighbor and Genetic AlgorithmDocument10 pagesClassification of Heart Disease Using K-Nearest Neighbor and Genetic AlgorithmZeeshan KhursheedNo ratings yet
- IEEE Project AbstractDocument78 pagesIEEE Project AbstractswapnaNo ratings yet
- TSP Csse 31761Document17 pagesTSP Csse 31761Arul NNo ratings yet
- Top JournalsDocument12 pagesTop Journalsrikaseo rikaNo ratings yet
- Early Detection of Eye Disease Using CNNDocument10 pagesEarly Detection of Eye Disease Using CNNIJRASETPublicationsNo ratings yet
- Machine Learning For Health Services ResearchersDocument8 pagesMachine Learning For Health Services ResearchersFaraz KhanNo ratings yet
- Deep Reinforcement Learning For DTRDocument13 pagesDeep Reinforcement Learning For DTRStabak NandiNo ratings yet
- Chronic Kidney Disease Detection With Appropriate Diet PlanDocument9 pagesChronic Kidney Disease Detection With Appropriate Diet PlanIJRASETPublicationsNo ratings yet
- Improved The Performance of The K-Means Cluster Using The Sum of Squared Error (SSE) Optimized by Using The Elbow MethodDocument7 pagesImproved The Performance of The K-Means Cluster Using The Sum of Squared Error (SSE) Optimized by Using The Elbow MethodRyann DarnisNo ratings yet
- JPSP - 2022 - 388Document7 pagesJPSP - 2022 - 388Dr. Peer Azmat ShahNo ratings yet
- Computers in Biology and Medicine: D.P. Dogra, A.K. Majumdar, S. Sural, J. Mukherjee, S. Mukherjee, A. SinghDocument10 pagesComputers in Biology and Medicine: D.P. Dogra, A.K. Majumdar, S. Sural, J. Mukherjee, S. Mukherjee, A. Singhalexis3aguilarNo ratings yet
- Plant Disease Detection Using Convolutional Neural NetworkDocument14 pagesPlant Disease Detection Using Convolutional Neural NetworkVaibhav MandhareNo ratings yet
- 1 s2.0 S0031320322003065 MainDocument10 pages1 s2.0 S0031320322003065 MainWided HechkelNo ratings yet
- 19MCB0010 Paper - 130321Document6 pages19MCB0010 Paper - 130321Godwin EmmanuelNo ratings yet
- Garg 2021 IOP Conf. Ser. Mater. Sci. Eng. 1022 012046Document10 pagesGarg 2021 IOP Conf. Ser. Mater. Sci. Eng. 1022 012046Mohshin KhanNo ratings yet
- A Vision-Based Transfer Learning Approach For Recognizing Behavioral Symptoms in People With DementiaDocument6 pagesA Vision-Based Transfer Learning Approach For Recognizing Behavioral Symptoms in People With DementiasushanprazNo ratings yet
- Unbalanced and Small Sample Deep Learning For COVID X-Ray ClassificationDocument13 pagesUnbalanced and Small Sample Deep Learning For COVID X-Ray ClassificationS. SreeRamaVamsidharNo ratings yet
- Effective Analysis of Multilayer Perceptron and Sequential Minimal Optimization in Prediction of Dyscalculia Among Primary School ChildrenDocument5 pagesEffective Analysis of Multilayer Perceptron and Sequential Minimal Optimization in Prediction of Dyscalculia Among Primary School ChildrenIqbal HapidNo ratings yet
- A Hybrid Posture Detection Framework: Integrating Machine Learning and Deep Neural NetworksDocument8 pagesA Hybrid Posture Detection Framework: Integrating Machine Learning and Deep Neural NetworksSatnam SinghNo ratings yet
- A Fruits Recognition System Based On A Modern Deep Learning TechniqueDocument6 pagesA Fruits Recognition System Based On A Modern Deep Learning TechniqueQuantanics InNo ratings yet
- Machine Learning Approach For Acute Respiratory Infections (ISPA) Prediction: Case Study IndonesiaDocument5 pagesMachine Learning Approach For Acute Respiratory Infections (ISPA) Prediction: Case Study IndonesiaSasmita DewiNo ratings yet
- 02 Projct - ParkinsonDocument32 pages02 Projct - ParkinsonPriyadharshiniNo ratings yet
- Predicting and Classifing The Levels of Autism Spectrum DisorderDocument53 pagesPredicting and Classifing The Levels of Autism Spectrum DisorderVedha TechnologiesNo ratings yet
- Vijayalakshmi 2020Document6 pagesVijayalakshmi 2020akshatguptaec20.rvitmNo ratings yet
- A Personalized Model For Monitoring Vital Signs Using Camera of The Smart PhoneDocument6 pagesA Personalized Model For Monitoring Vital Signs Using Camera of The Smart PhonefediNo ratings yet
- Patient Monitoring System Based On Internet of ThingsDocument15 pagesPatient Monitoring System Based On Internet of ThingsSiddhi PatilNo ratings yet
- New Paper Brain TumorDocument8 pagesNew Paper Brain TumorZeeshanNo ratings yet
- A Deep Feature-Based Real-Time System For Alzheimer Disease Stage DetectionDocument19 pagesA Deep Feature-Based Real-Time System For Alzheimer Disease Stage Detectionmozhganeutoop1998No ratings yet
- Ijcse - Based Automatic Personality Recognition Used in Asynchronous Video InterviewsDocument8 pagesIjcse - Based Automatic Personality Recognition Used in Asynchronous Video Interviewsiaset123No ratings yet
- 2 1525686185 - 07-05-2018 PDFDocument6 pages2 1525686185 - 07-05-2018 PDFAnonymous Tg2ypWjlNMNo ratings yet
- Machine Learning in Biomedical EngineeringDocument3 pagesMachine Learning in Biomedical EngineeringSebastianNo ratings yet
- Zhang 2018Document17 pagesZhang 2018Victor Flores BenitesNo ratings yet
- Deep Learning in OphthalmologyDocument24 pagesDeep Learning in Ophthalmologyneroma3217No ratings yet
- Electronics 11 03591 v4Document12 pagesElectronics 11 03591 v4SanderNo ratings yet
- Transfer Learning For Cancer Diagnosis in Histopathological ImagesDocument8 pagesTransfer Learning For Cancer Diagnosis in Histopathological ImagesIAES IJAINo ratings yet
- An Intelligent Alzheimer's Disease Diagnosis Method Using Unsupervised Feature LearningDocument16 pagesAn Intelligent Alzheimer's Disease Diagnosis Method Using Unsupervised Feature LearningKamran AhmedNo ratings yet
- Pneumonia Detection Using CNN PublishedDocument10 pagesPneumonia Detection Using CNN Publishednikita BhargavaNo ratings yet
- Visualizing Convolutional: The Indicators of Diabetic Retinopathy Learnt by Neural NetworksDocument7 pagesVisualizing Convolutional: The Indicators of Diabetic Retinopathy Learnt by Neural NetworksGulshan VermaNo ratings yet
- Decision Making IVDocument20 pagesDecision Making IVashutosh18690No ratings yet
- Exer4 CabugnasonDocument5 pagesExer4 Cabugnasonjohnvincent.cabugnasonNo ratings yet
- DRL NewDocument12 pagesDRL NewSoham DattaNo ratings yet
- 2023csm007 DBMS 1Document6 pages2023csm007 DBMS 1Soham DattaNo ratings yet
- Hashing Important TheoremsDocument26 pagesHashing Important TheoremsSoham DattaNo ratings yet
- Final Term Paper Draft 2Document33 pagesFinal Term Paper Draft 2Soham DattaNo ratings yet
- J. Sil 1Document6 pagesJ. Sil 1Soham DattaNo ratings yet
- NeuralDocument33 pagesNeuralSoham DattaNo ratings yet
- Inter Hospital Alzheimer's Disease Detection CNNDocument12 pagesInter Hospital Alzheimer's Disease Detection CNNSoham DattaNo ratings yet
- Multimodal Deep Learning ApproachDocument11 pagesMultimodal Deep Learning ApproachSoham DattaNo ratings yet
- The Promise of Convolutional Neural NetworksDocument13 pagesThe Promise of Convolutional Neural NetworksSoham DattaNo ratings yet
- Leveraging Electronic Records and Knowledge NetworksDocument34 pagesLeveraging Electronic Records and Knowledge NetworksSoham DattaNo ratings yet
- Souk Menu 2022Document8 pagesSouk Menu 2022Soham DattaNo ratings yet
- CMINDS AdmissionTest - SYLLABUS Apr22Document4 pagesCMINDS AdmissionTest - SYLLABUS Apr22Soham DattaNo ratings yet
- ETRI Journal - 2024 - Bang - Alzheimer S Disease Recognition From Spontaneous Speech Using Large Language ModelsDocument10 pagesETRI Journal - 2024 - Bang - Alzheimer S Disease Recognition From Spontaneous Speech Using Large Language ModelsSoham DattaNo ratings yet
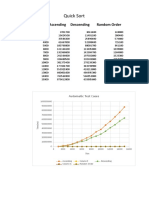
- Quick Sort: Size Ascending Descending Random OrderDocument5 pagesQuick Sort: Size Ascending Descending Random OrderSoham DattaNo ratings yet
- Common Record Sheet ModifiedDocument5 pagesCommon Record Sheet ModifiedSoham DattaNo ratings yet
- Da Jo: Auareccurrence JoeeDocument5 pagesDa Jo: Auareccurrence JoeeSoham DattaNo ratings yet
- Eigenvalues and EigenvectorsDocument33 pagesEigenvalues and EigenvectorsSoham DattaNo ratings yet
- CommerceDocument25 pagesCommerceSoham DattaNo ratings yet
- DartonismDocument4 pagesDartonismSoham DattaNo ratings yet
- Project Programs FinalDocument16 pagesProject Programs FinalSoham DattaNo ratings yet
- Anirban Mukherjee Resume.Document2 pagesAnirban Mukherjee Resume.Soham DattaNo ratings yet
- ICP Course Outline PDFDocument3 pagesICP Course Outline PDFIjlal NasirNo ratings yet
- A Level Chemistry Paper 1 Set 1Document20 pagesA Level Chemistry Paper 1 Set 1RUBANGAKENE DENISNo ratings yet
- TroubleshootingDocument28 pagesTroubleshootingRisoSilvaNo ratings yet
- 06 Introduction To Philosophy PDFDocument8 pages06 Introduction To Philosophy PDFRhue DadorNo ratings yet
- Learning Outcomes RaDocument11 pagesLearning Outcomes Raapi-349210703No ratings yet
- The Steps How To Use Theodolite For SurveyingDocument2 pagesThe Steps How To Use Theodolite For Surveyinglong bottomNo ratings yet
- PartsDocument4 pagesPartsburakkkkkkkkNo ratings yet
- CV Adinda Putri MDocument1 pageCV Adinda Putri MVeena GamingNo ratings yet
- Government of India: WWW - Infracon.nic - inDocument2 pagesGovernment of India: WWW - Infracon.nic - inViraj PatelNo ratings yet
- LG Machine SpecDocument1 pageLG Machine SpecMohd AffiqNo ratings yet
- 1 PTI Introduction1Document29 pages1 PTI Introduction1Creation YourNo ratings yet
- ManualDocument50 pagesManualmohan2380% (1)
- Inset Narrative ReportDocument4 pagesInset Narrative ReportJuvy Vale BustamanteNo ratings yet
- Lion Air Eticket Itinerary / Receipt: Putra/Wirawan Lohisto MRDocument3 pagesLion Air Eticket Itinerary / Receipt: Putra/Wirawan Lohisto MRNo NameNo ratings yet
- Project Report On Business Eco Magazine - Vivek Kumar ShawDocument36 pagesProject Report On Business Eco Magazine - Vivek Kumar ShawAnand shawNo ratings yet
- ECE 4316: Digital Signal Processing: Dr. Hany M. ZamelDocument19 pagesECE 4316: Digital Signal Processing: Dr. Hany M. ZamellovelearnNo ratings yet
- Solution Manual For Introductory Econometrics A Modern Approach 6Th Edition Wooldridge 130527010X 9781305270107 Full Chapter PDFDocument29 pagesSolution Manual For Introductory Econometrics A Modern Approach 6Th Edition Wooldridge 130527010X 9781305270107 Full Chapter PDFlois.payne328100% (18)
- Crizal RX and Stock Lens Availability ChartDocument9 pagesCrizal RX and Stock Lens Availability ChartArvind HanaNo ratings yet
- C-4DS & C-4DL Electric Bed User Manual-Rev180810Document30 pagesC-4DS & C-4DL Electric Bed User Manual-Rev180810hector raffaNo ratings yet
- Midwich Cuckoos EssayDocument2 pagesMidwich Cuckoos EssayVasuda MukundanNo ratings yet
- BRANIGAN - Eduard - A Point of View in The CinemaDocument6 pagesBRANIGAN - Eduard - A Point of View in The CinemaSonia RochaNo ratings yet
- Exercise Solution - I Software Testing Chapter 4Document4 pagesExercise Solution - I Software Testing Chapter 4Fatima AsadNo ratings yet
- Extended Essay TimelineDocument2 pagesExtended Essay TimelineMertcanNo ratings yet
- Climate Change Scheme of Work For KS2Document13 pagesClimate Change Scheme of Work For KS2Zoe AlsumaitNo ratings yet