You might also like
- Da Archive 2021-12-01Document114 pagesDa Archive 2021-12-01Stephen Ferry100% (3)
- Fall of The Lich King DND 5e - Assault On Icecrown CitadelDocument28 pagesFall of The Lich King DND 5e - Assault On Icecrown CitadelАлександр ГерасимовNo ratings yet
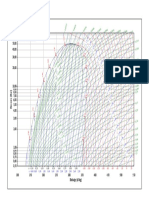
- Grafico R404Document1 pageGrafico R404Cristian EncinaNo ratings yet
- Swords & Wizardry Quick StartDocument28 pagesSwords & Wizardry Quick Startfernando_jesus_58No ratings yet
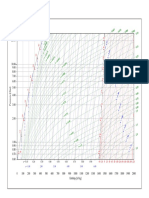
- R744 PDFDocument1 pageR744 PDFCristian EncinaNo ratings yet
- Moody PDFDocument1 pageMoody PDFEduardo Fernández CoronadoNo ratings yet
- OD&TDocument40 pagesOD&TNelson TeixeiraNo ratings yet
- DTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 19-09-04 Ref:W.C.Reynolds: Thermodynamic Properties in SIDocument1 pageDTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 19-09-04 Ref:W.C.Reynolds: Thermodynamic Properties in SITrần ViệtNo ratings yet
- R23 SI Units PDFDocument1 pageR23 SI Units PDFFarhan Nur RizkiNo ratings yet
- Steel Grating Layout Plan: STA. 0+000 STA. 0+050 STA. 0+100 STA. 0+150 STA. 0+200 STA. 0+211Document1 pageSteel Grating Layout Plan: STA. 0+000 STA. 0+050 STA. 0+100 STA. 0+150 STA. 0+200 STA. 0+211James Ryan del CarmenNo ratings yet
- DTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 17-04-10 Ref:R.Döring. Klima+Kälte Ingenieur Ki-Extra 5, 1978Document1 pageDTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 17-04-10 Ref:R.Döring. Klima+Kälte Ingenieur Ki-Extra 5, 1978cbdk71No ratings yet
- Distribution of Assets: Construction in ProgressDocument12 pagesDistribution of Assets: Construction in ProgressAngelNo ratings yet
- Sprue Bush M.659: 180 (145) Material MecavalDocument1 pageSprue Bush M.659: 180 (145) Material Mecavalryu prasetyaNo ratings yet
- DTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 19-01-21 Ref:W.C.Reynolds: Thermodynamic Properties in SIDocument1 pageDTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 19-01-21 Ref:W.C.Reynolds: Thermodynamic Properties in SIJose LuisNo ratings yet
- R 732 PDFDocument1 pageR 732 PDFJose LuisNo ratings yet
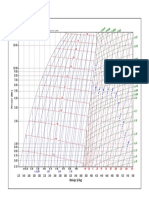
- R717 PDFDocument1 pageR717 PDFDiego RamirezNo ratings yet
- NH3 PDFDocument1 pageNH3 PDFvi văn tâmNo ratings yet
- Topografico Rumorosa-27Document1 pageTopografico Rumorosa-27alex.medina2krNo ratings yet
- Schema R717Document1 pageSchema R717KenosaNo ratings yet
- Pieza AirtecDocument1 pagePieza AirtecFaustoNo ratings yet
- Sap Windy LoadDocument1 pageSap Windy LoadAbdullah NajjarNo ratings yet
- Drainase BLOK 3 ModelDocument1 pageDrainase BLOK 3 ModelFirnanda PutraNo ratings yet
- DTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 19-09-04 Ref:W.C.Reynolds: Thermodynamic Properties in SIDocument1 pageDTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 19-09-04 Ref:W.C.Reynolds: Thermodynamic Properties in SITrần ViệtNo ratings yet
- R600 ADocument1 pageR600 ATrần ViệtNo ratings yet
- 7981 Agency Wide Budget TemplateDocument12 pages7981 Agency Wide Budget TemplaterohNo ratings yet
- Alarm: Mobile R EceptionDocument1 pageAlarm: Mobile R Eceptionapi-18389817No ratings yet
- Locating Jig DrawingDocument1 pageLocating Jig DrawingNick BuccinoNo ratings yet
- Template - GAD Accomplishment ReportDocument1 pageTemplate - GAD Accomplishment ReportRegie CarinoNo ratings yet
- QF-105 Time CardDocument1 pageQF-105 Time CardSYED ARSHADULLAHNo ratings yet
- LAMINASDocument3 pagesLAMINASJonnathan Taipe OlsonNo ratings yet
- R717 DijagramDocument1 pageR717 DijagramminaNo ratings yet
- Employee ReimbursementDocument2 pagesEmployee ReimbursementPratima ChavanNo ratings yet
- Circulo 03Document1 pageCirculo 03MASSIMO PALIZA PINTONo ratings yet
- BTC Mep DM KH 01 001Document1 pageBTC Mep DM KH 01 001suleiman004No ratings yet
- Dtu, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/Kg) - T in (ºc) M.J. Skovrup & H.J.H Knudsen. 19-11-29 Ref:Peng-Robinson-Stryjek-Vera Equation and Dupont Suva Ac9000Document1 pageDtu, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/Kg) - T in (ºc) M.J. Skovrup & H.J.H Knudsen. 19-11-29 Ref:Peng-Robinson-Stryjek-Vera Equation and Dupont Suva Ac9000raul correaNo ratings yet
- Biba PoDocument1 pageBiba PoJagritiNo ratings yet
- TER TemplateDocument2 pagesTER TemplateRheneir MoraNo ratings yet
- National Qualifiers 2015Document1 pageNational Qualifiers 2015Gundhi AsmoroNo ratings yet
- Kikoko RoadDocument15 pagesKikoko Roadkizito deusNo ratings yet
- Detail B: Material: WeightDocument1 pageDetail B: Material: WeightAmir ShNo ratings yet
- Monitoring Quantity Embankment Dike A Sta - 0+000 Sta - 0+700 74122Document28 pagesMonitoring Quantity Embankment Dike A Sta - 0+000 Sta - 0+700 74122Bagoes Fajar PutraNo ratings yet
- Diagrama NH3 - 10/+35 ºCDocument1 pageDiagrama NH3 - 10/+35 ºCalbertopaganNo ratings yet
- Por Example 11Document2 pagesPor Example 11rui annNo ratings yet
- VD For Water at 20: Moody DiagramDocument1 pageVD For Water at 20: Moody DiagramLoc van NguyenNo ratings yet
- Denah TamanDocument2 pagesDenah Tamanmizroni agungNo ratings yet
- Abamoo PDFDocument1 pageAbamoo PDFAxo Pijo CopónNo ratings yet
- Abaco Moody PDFDocument1 pageAbaco Moody PDFAxo Pijo CopónNo ratings yet
- AbacoMoody02 PDFDocument1 pageAbacoMoody02 PDFAxo Pijo CopónNo ratings yet
- Moody Si PDFDocument1 pageMoody Si PDFJavier GiraldoNo ratings yet
- Jitorres moodySI PDFDocument1 pageJitorres moodySI PDFYaiza MoscoteNo ratings yet
- VD For Water at 20: Moody DiagramDocument1 pageVD For Water at 20: Moody DiagramMayckolNo ratings yet
- Diagrama Moody - SI TomDavis PDFDocument1 pageDiagrama Moody - SI TomDavis PDFMaycol Carrion ChallcoNo ratings yet
- VD For Water at 20: Moody DiagramDocument1 pageVD For Water at 20: Moody DiagramSebastián Aguilera MadariagaNo ratings yet
- Moody Si PDFDocument1 pageMoody Si PDFShamirNo ratings yet
- Moody Si PDFDocument1 pageMoody Si PDFArturo Suarez TaypeNo ratings yet
- Diagrama de ModdyDocument1 pageDiagrama de ModdypatoqlNo ratings yet
- moodySI PDFDocument1 pagemoodySI PDFJairo Andres García GallónNo ratings yet
- Moody SiDocument1 pageMoody SiLuz NuñezNo ratings yet
- Ratios Maximos - 1Document1 pageRatios Maximos - 1proyectistanuevoNo ratings yet
- Standar Perencanaan Irigasi 408: Situasi Bangunan SituationDocument1 pageStandar Perencanaan Irigasi 408: Situasi Bangunan SituationDanni Arman, STNo ratings yet
- REX Power BoardDocument1 pageREX Power BoardNikolay PenevNo ratings yet
- Boxer Gifts Usa 2023 CatalogDocument68 pagesBoxer Gifts Usa 2023 CatalogshopwellrsNo ratings yet
- 15th August Rotary Upstep Rapid RatingDocument5 pages15th August Rotary Upstep Rapid RatingkunjuNo ratings yet
- Hhhjjjkko Rasa Asf K Ok Lifzzdhhkob Ay UjhzxDocument1 pageHhhjjjkko Rasa Asf K Ok Lifzzdhhkob Ay UjhzxxrayNo ratings yet
- Today's Puzzles: The MiniDocument5 pagesToday's Puzzles: The Minihemanth_85No ratings yet
- Probabilty: Test Series CourseDocument12 pagesProbabilty: Test Series Courseshubh9190No ratings yet
- 4 3 Wiring Diagram: Da 1 0 Transmission I-Shift 2Document1 page4 3 Wiring Diagram: Da 1 0 Transmission I-Shift 2Juan Jose Hernandez JimenezNo ratings yet
- Activity 1 - Teams SportsDocument2 pagesActivity 1 - Teams SportsRockheart 18No ratings yet
- Apiary AutomaRulebook r4Document12 pagesApiary AutomaRulebook r4tilak ratanparaNo ratings yet
- Night of MUmmyDocument16 pagesNight of MUmmyEduardo Cavalcante da SilvaNo ratings yet
- Errata & Notes Blue Rose Narrator's JournalDocument2 pagesErrata & Notes Blue Rose Narrator's JournalT DarbNo ratings yet
- G. K. Kasparov-How Life Imitates Chess. by Garry Kasparov With MIG Greengard-Arrow Books (2008)Document1 pageG. K. Kasparov-How Life Imitates Chess. by Garry Kasparov With MIG Greengard-Arrow Books (2008)Namık MehmetbeyliNo ratings yet
- Naruto 5e Full Document 22Document1 pageNaruto 5e Full Document 22Herbert David Lopes dos SantosNo ratings yet
- #115903 Difficulty: Hard #178993 Difficulty: ModerateDocument20 pages#115903 Difficulty: Hard #178993 Difficulty: Moderateravishi77No ratings yet
- Red Sox Offseason PlansDocument1 pageRed Sox Offseason Plansapi-583037485No ratings yet
- Oep ADA ListDocument6 pagesOep ADA ListLion KenanNo ratings yet
- Blood Bowl - Dark Elves Edition ManualDocument48 pagesBlood Bowl - Dark Elves Edition ManualJeff ScottNo ratings yet
- Tabel Dimensi Saluran IrigasiDocument1 pageTabel Dimensi Saluran IrigasiMell TahoniNo ratings yet
- Badminton PDF FreeDocument5 pagesBadminton PDF FreeZedy GullesNo ratings yet
- Jadwal Vaksin - PT Rekayasa Engineering 01 April 2021 - Tennis Indoor Senayan (Jakarta Pusat)Document5 pagesJadwal Vaksin - PT Rekayasa Engineering 01 April 2021 - Tennis Indoor Senayan (Jakarta Pusat)zikrillah1No ratings yet
- Traditional Children Games of Andhra PradeshDocument5 pagesTraditional Children Games of Andhra PradeshBhavika VermaNo ratings yet
- Earthium Brochure EN - CPDocument24 pagesEarthium Brochure EN - CPwhatsapp statusNo ratings yet
- Yuvardha VI - PreinviteDocument13 pagesYuvardha VI - Preinviterohit meenaNo ratings yet
- Online Gaming As A Factor Affects The Academic Performance of Selected Students of Phinma CocDocument8 pagesOnline Gaming As A Factor Affects The Academic Performance of Selected Students of Phinma CocKarell Faye BatulanNo ratings yet
- Literature Review Violent Video Games AggressionDocument5 pagesLiterature Review Violent Video Games AggressionafmabhxbudpljrNo ratings yet
- History Timeline of BadmintonDocument3 pagesHistory Timeline of BadmintonAllen KateNo ratings yet