You might also like
- Global Economics Paper - A Quantamental Approach To EM Local Rates InvestingDocument31 pagesGlobal Economics Paper - A Quantamental Approach To EM Local Rates InvestingtinatessariNo ratings yet
- CSI 4107 - Winter 2016 - MidtermDocument10 pagesCSI 4107 - Winter 2016 - MidtermAmin Dhouib0% (1)
- Hands On Big DataDocument52 pagesHands On Big DatapratapNo ratings yet
- Hive Workshop PracticalDocument29 pagesHive Workshop Practicalvenkat yNo ratings yet
- Hadoop Interview Questions NewDocument9 pagesHadoop Interview Questions NewRupali ShettyNo ratings yet
- The Teradata Database - Part 3 Usage Fundamentals PDFDocument20 pagesThe Teradata Database - Part 3 Usage Fundamentals PDFshrikanchi rathiNo ratings yet
- IEEE STD 3004.11-2019Document63 pagesIEEE STD 3004.11-2019Alexandre PereiraNo ratings yet
- Exploring Bigdata With Hadoop: Dr.A.Bazila Banu Associate Professor Department of CseDocument23 pagesExploring Bigdata With Hadoop: Dr.A.Bazila Banu Associate Professor Department of CseMAMAN MYTHIEN SNo ratings yet
- Relational Database Management SystemDocument5 pagesRelational Database Management Systemsaroj1122No ratings yet
- Relational Object Oriented and Multi Dimensional DatabasesDocument13 pagesRelational Object Oriented and Multi Dimensional Databasesapi-297547878No ratings yet
- Unit 3 - OLAPDocument107 pagesUnit 3 - OLAPPARAZZINo ratings yet
- The Poster Child of Open Source BusinessDocument35 pagesThe Poster Child of Open Source BusinessSharath GhoshNo ratings yet
- Hadoop Interviews QDocument9 pagesHadoop Interviews QS KNo ratings yet
- SQL NoSQL NewSQLDocument12 pagesSQL NoSQL NewSQLganeshskmNo ratings yet
- Presentation ON RDBMS: Submitted By-Dilpreet Singh Joginder Singh Class - Mba (Bu) 3 SEMDocument11 pagesPresentation ON RDBMS: Submitted By-Dilpreet Singh Joginder Singh Class - Mba (Bu) 3 SEMnamdeeptoor100% (3)
- Oltp Olap RtapDocument53 pagesOltp Olap Rtapgoyalsb2682No ratings yet
- Pentaho Training Course CatalogDocument13 pagesPentaho Training Course CatalogAbdel AdimeNo ratings yet
- MahoutDocument6 pagesMahoutPappu KhanNo ratings yet
- Big Data and Spark DevelopersDocument5 pagesBig Data and Spark DevelopersBalaji ArunNo ratings yet
- NoSQL MongoDB HBase CassandraDocument142 pagesNoSQL MongoDB HBase Cassandrajustin maxtonNo ratings yet
- An Introduction To Big DataDocument31 pagesAn Introduction To Big DataDewi ArdianiNo ratings yet
- Map Reduce With Hadoop:: Presented by ANIVESHA-126 ARITRA-128 RIA-142 Shashvat - 150 SHEKHAR-151Document9 pagesMap Reduce With Hadoop:: Presented by ANIVESHA-126 ARITRA-128 RIA-142 Shashvat - 150 SHEKHAR-151Aritra Banerjee100% (1)
- Question: Dimension Modeling Types Along With Their SignificanceDocument27 pagesQuestion: Dimension Modeling Types Along With Their SignificanceAngajala AngajalaNo ratings yet
- Talend Quick BookDocument38 pagesTalend Quick Bookkailash yadavNo ratings yet
- Pig HiveDocument72 pagesPig HivesuhasspotifypvtNo ratings yet
- File Formats in Big DataDocument13 pagesFile Formats in Big DataMeghna SharmaNo ratings yet
- Unit - II Data PreprocessingDocument35 pagesUnit - II Data PreprocessingANITHA AMMUNo ratings yet
- BD - Unit - IV - Hive and PigDocument41 pagesBD - Unit - IV - Hive and PigPrem KumarNo ratings yet
- Big Data Syllabus For Theory and LabDocument4 pagesBig Data Syllabus For Theory and Labchetana tukkojiNo ratings yet
- Seminar Topic NosqlDocument73 pagesSeminar Topic NosqlAnish ARNo ratings yet
- 4.1 Divide and ConquerDocument21 pages4.1 Divide and Conquermadhu jhaNo ratings yet
- 3.1 Class Fundamentals: The General Form of A ClassDocument34 pages3.1 Class Fundamentals: The General Form of A ClassSrijana ShetNo ratings yet
- Unit I Introduction 1.1 What Motivated Data Mining? Why Is It Important?Document18 pagesUnit I Introduction 1.1 What Motivated Data Mining? Why Is It Important?ANITHA AMMUNo ratings yet
- My) SQL Cheat Sheet: Mysql Command-Line What How Example (S)Document3 pagesMy) SQL Cheat Sheet: Mysql Command-Line What How Example (S)netnitinNo ratings yet
- HDFS ArchitectureDocument47 pagesHDFS Architecturekrishan GoyalNo ratings yet
- Hadoop (Big Data) : Skills GainedDocument8 pagesHadoop (Big Data) : Skills GainedRambabu GiduturiNo ratings yet
- BigData Unit 2Document15 pagesBigData Unit 2Sreedhar ArikatlaNo ratings yet
- DBMS Vs RDBMS PDFDocument7 pagesDBMS Vs RDBMS PDFvikasNo ratings yet
- Impala and BigQueryDocument47 pagesImpala and BigQuerydurdurkNo ratings yet
- Hadoop Interview QuestionsDocument17 pagesHadoop Interview QuestionspatriciaNo ratings yet
- WT Unit-IDocument49 pagesWT Unit-IPauravi NagarkarNo ratings yet
- Oracle Fact Sheet 079219 PDFDocument2 pagesOracle Fact Sheet 079219 PDFGiovanni Serauto100% (1)
- Nosql Database: New Era of Databases For Big Data Analytics - Classification, Characteristics and ComparisonDocument17 pagesNosql Database: New Era of Databases For Big Data Analytics - Classification, Characteristics and Comparisonjames smithNo ratings yet
- Adbms Data Warehousing and Data MiningDocument169 pagesAdbms Data Warehousing and Data MiningPinkNo ratings yet
- Big DataDocument11 pagesBig DatawilsongadekarNo ratings yet
- Pywaw 80 Manageable Data Pipelines With Airflow and KubernetesDocument57 pagesPywaw 80 Manageable Data Pipelines With Airflow and Kubernetesbobquest33No ratings yet
- Mapreduce LabDocument36 pagesMapreduce LabNhơn PhạmNo ratings yet
- Course Contents of Hadoop and Big DataDocument11 pagesCourse Contents of Hadoop and Big DatarahulsseNo ratings yet
- 2 HDFS CommandsDocument7 pages2 HDFS CommandsVIPUL GUPTANo ratings yet
- Big Data Ana Unit - II Part - II (Hadoop Architecture)Document47 pagesBig Data Ana Unit - II Part - II (Hadoop Architecture)Mokshada YadavNo ratings yet
- Oltp VS OlapDocument9 pagesOltp VS OlapSikkandar Sha100% (1)
- OLTP (On-Line Transaction Processing) Is Characterized by A Large Number of Short On-Line TransactionsDocument10 pagesOLTP (On-Line Transaction Processing) Is Characterized by A Large Number of Short On-Line TransactionseazyNo ratings yet
- Unstructured Dataload Into Hive Database Through PySparkDocument9 pagesUnstructured Dataload Into Hive Database Through PySparksayhi2sudarshanNo ratings yet
- 2 Hadoop (Uploaded)Document82 pages2 Hadoop (Uploaded)Prateek PoleNo ratings yet
- Big Data: Business Intelligence, and AnalyticsDocument31 pagesBig Data: Business Intelligence, and AnalyticsKarthigai SelvanNo ratings yet
- Hadoop OverviewDocument16 pagesHadoop OverviewSunil D Patil100% (1)
- Bigdata 2016 Hands On 2891109Document96 pagesBigdata 2016 Hands On 2891109cesmarscribdNo ratings yet
- Unit VDocument51 pagesUnit V476No ratings yet
- Ron Clark ReflectionDocument3 pagesRon Clark Reflectionapi-376753605No ratings yet
- CAR-66 Aircraft Maintenance Licensing Requirements - FINAL - JNC v0.07 200220Document136 pagesCAR-66 Aircraft Maintenance Licensing Requirements - FINAL - JNC v0.07 200220Sagar KandelNo ratings yet
- Avaya CS 1000 HandbookDocument45 pagesAvaya CS 1000 HandbookyogeshchetanaNo ratings yet
- Teaching English As A Second LanguageDocument90 pagesTeaching English As A Second Languagefb-68124651499% (95)
- Terminologie TunsoareDocument8 pagesTerminologie TunsoareCostea AlinaNo ratings yet
- Oropharyngeal and Nasopharyngeal Suctioning (Rationale)Document3 pagesOropharyngeal and Nasopharyngeal Suctioning (Rationale)Jemina Rafanan Racadio100% (2)
- Unit-Ii: Job Design, Job Analysis and Human Resource PlanningDocument16 pagesUnit-Ii: Job Design, Job Analysis and Human Resource PlanningimadNo ratings yet
- Big Apple Franchise Development ProgrammeDocument4 pagesBig Apple Franchise Development ProgrammeAribah Aida JoharyNo ratings yet
- Quotation Format 01-05-2022Document2 pagesQuotation Format 01-05-2022m nickNo ratings yet
- Multiframe Connect Edition V21.14.00 Readme 03 October 2018: Side-By-Side Installation - Important ChangesDocument20 pagesMultiframe Connect Edition V21.14.00 Readme 03 October 2018: Side-By-Side Installation - Important ChangesElmer SullonNo ratings yet
- Veritas Volume Manager BasicsDocument8 pagesVeritas Volume Manager Basicsvishvendra1No ratings yet
- HP 20.04 Image InstallationDocument9 pagesHP 20.04 Image Installationjon san vicenteNo ratings yet
- SeleneDocument3 pagesSeleneshineygijoeNo ratings yet
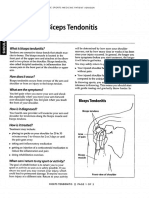
- Bicep TendonitisDocument2 pagesBicep Tendonitisjona_kineNo ratings yet
- Lesson Plan - Mechanical VibrationsDocument2 pagesLesson Plan - Mechanical Vibrationsrub786No ratings yet
- WV6 Official Questionnaire v4 June2012Document21 pagesWV6 Official Questionnaire v4 June2012Juan David CárdenasNo ratings yet
- Ethical and Social Responsibility of AmazonDocument17 pagesEthical and Social Responsibility of AmazonGraphic DesignersNo ratings yet
- ITT Digital Teacher PPT (M. Laili Hanafi)Document20 pagesITT Digital Teacher PPT (M. Laili Hanafi)M. Laili HanafiNo ratings yet
- Paper P6 Advanced Taxation Complete Text: Finance Act 2015 For September 2016 To March 2017 Examination SittingsDocument8 pagesPaper P6 Advanced Taxation Complete Text: Finance Act 2015 For September 2016 To March 2017 Examination SittingsShahbano BangashNo ratings yet
- Enzymology SyllabusDocument1 pageEnzymology SyllabusKamlesh SahuNo ratings yet
- PolyFlow BrochureDocument6 pagesPolyFlow BrochurejwochNo ratings yet
- Activating and Testing Satellite AbisDocument9 pagesActivating and Testing Satellite Abisnoer1304No ratings yet
- Tonsillitis and Adenoiditis: Islamic University Nursing CollegeDocument15 pagesTonsillitis and Adenoiditis: Islamic University Nursing CollegeNinaNo ratings yet
- Installation Manual Curtain WallDocument8 pagesInstallation Manual Curtain WallPrantik Adhar Samanta0% (1)
- DAFTAR PUSTAKA-Asri Nababan-H1C016022-Skripsi-2021 - 2Document3 pagesDAFTAR PUSTAKA-Asri Nababan-H1C016022-Skripsi-2021 - 2Johan Albert SembiringNo ratings yet
- Siemens FTGS BrochureDocument6 pagesSiemens FTGS BrochureJaime Rodríguez-Saavedra100% (1)
- Read "Customer Reviews" Before Buying Brilliance SF Avis!Document3 pagesRead "Customer Reviews" Before Buying Brilliance SF Avis!whdbkjnjklNo ratings yet
- Worksheet II: Statistics and Probability - Grade 11Document2 pagesWorksheet II: Statistics and Probability - Grade 11Nicomedes BanlaygasNo ratings yet