You might also like
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Elegant Web TypographyDocument130 pagesElegant Web TypographyRobert Guiscard100% (33)
- Large Scale Data PipelinesDocument91 pagesLarge Scale Data PipelinesgopinathmaruthachalaNo ratings yet
- IBM DB2 Interview Questions and AnswersDocument2 pagesIBM DB2 Interview Questions and AnswersSweta SinghNo ratings yet
- L06 - RISCV Datapath DesignDocument78 pagesL06 - RISCV Datapath DesignMishkaat100% (1)
- Presented by - Vidip Malhotra With AWS Toronto User GroupDocument38 pagesPresented by - Vidip Malhotra With AWS Toronto User GroupVidipNo ratings yet
- Demystfying Container Networking2 190915040315Document82 pagesDemystfying Container Networking2 190915040315vamsiram99No ratings yet
- 20761B 02Document28 pages20761B 02Abdul-alim Bhnsawy100% (1)
- Java Cryptography Extensions: Practical Guide for ProgrammersFrom EverandJava Cryptography Extensions: Practical Guide for ProgrammersRating: 5 out of 5 stars5/5 (1)
- Lecture4+ +Service+Oriented+ArchitectureDocument75 pagesLecture4+ +Service+Oriented+ArchitectureAmontos Edjie KentNo ratings yet
- Microsoft SDL Threat Modeling: Michael HowardDocument43 pagesMicrosoft SDL Threat Modeling: Michael Howardanon_320877389No ratings yet
- Mapa de Memoria Trackers Artech - Communication BoxDocument25 pagesMapa de Memoria Trackers Artech - Communication Boxjavier escobarNo ratings yet
- Leveraging Consistent Hashing in Your Python ApplicationsDocument39 pagesLeveraging Consistent Hashing in Your Python ApplicationsHemant JainNo ratings yet
- Flexible Rollback Recovery in Dynamic Heterogeneous Grid ComputingDocument9 pagesFlexible Rollback Recovery in Dynamic Heterogeneous Grid ComputingSai Krishna PNo ratings yet
- Analysis Synthesis: Chap7 Semantic ProcessingDocument43 pagesAnalysis Synthesis: Chap7 Semantic ProcessingKhanNo ratings yet
- Formal Models of Concurrency and Communication: Based On The Slides of Gottfried Vossen, Univ. of Münster, GermanyDocument37 pagesFormal Models of Concurrency and Communication: Based On The Slides of Gottfried Vossen, Univ. of Münster, Germanymariab1989No ratings yet
- TL-Verilog For BARC 2021Document30 pagesTL-Verilog For BARC 2021aditya kumarNo ratings yet
- Chapter 7Document47 pagesChapter 7indhuja rNo ratings yet
- ResearchDocument11 pagesResearchTrain SlowNo ratings yet
- Pavel Sustr My Favourite Db2 Problem Determination TricksDocument43 pagesPavel Sustr My Favourite Db2 Problem Determination TricksDmitryNo ratings yet
- A Client-Centric Grid Knowledgebase: George Kola, and Miron LivnyDocument22 pagesA Client-Centric Grid Knowledgebase: George Kola, and Miron LivnyrajashekarpulaNo ratings yet
- Introduction To Distributed Systems: Slides For CSCI 3171 Lectures E. W. GrundkeDocument26 pagesIntroduction To Distributed Systems: Slides For CSCI 3171 Lectures E. W. GrundkeANDRESNo ratings yet
- COA Unit 1 Lecture 4Document35 pagesCOA Unit 1 Lecture 4Pratibha SNo ratings yet
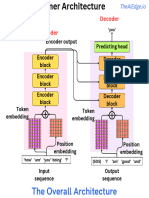
- The Transformer ArchitectureDocument9 pagesThe Transformer Architecturealexandre albalustroNo ratings yet
- In-Memory Backdoors (A.k.a In-Memory "Rootkits") in Oracle: ConsultingDocument30 pagesIn-Memory Backdoors (A.k.a In-Memory "Rootkits") in Oracle: Consultingdsu205No ratings yet
- Performance Analysis of CORBA Performance Analysis of CORBA: by S.Venkatesan S.VenkatesanDocument22 pagesPerformance Analysis of CORBA Performance Analysis of CORBA: by S.Venkatesan S.VenkatesanSrinidhi Tumkur Nagaraja RaoNo ratings yet
- 07 Basic ROS ProgrammingDocument77 pages07 Basic ROS ProgrammingaDun iDeiNo ratings yet
- Intro AppendixDocument22 pagesIntro AppendixRavi ChythanyaNo ratings yet
- SV TB Example 1671687516Document30 pagesSV TB Example 1671687516Sumanish SharmaNo ratings yet
- Domain Name System Server Round-Robin Functionality For The Cisco AS5800Document6 pagesDomain Name System Server Round-Robin Functionality For The Cisco AS5800Bui Hong MyNo ratings yet
- Port Network - Smart Contracts Security Audit Report - REVISEDDocument22 pagesPort Network - Smart Contracts Security Audit Report - REVISEDMychel MendesNo ratings yet
- Computer Organisation & DesignDocument132 pagesComputer Organisation & DesignVivek YadavNo ratings yet
- Register Transfer and Microoperations2017-3-5Document20 pagesRegister Transfer and Microoperations2017-3-5qwertyNo ratings yet
- Remote Procedure Calls: Network Transfer ProtocolsDocument21 pagesRemote Procedure Calls: Network Transfer ProtocolspermasaNo ratings yet
- Parallel Programming Session 1Document27 pagesParallel Programming Session 1cilango1No ratings yet
- Microsoft AccessDocument14 pagesMicrosoft AccessManzoor ElahiNo ratings yet
- Assignment 4: Implementing RPC/RMI: Operating SystemsDocument6 pagesAssignment 4: Implementing RPC/RMI: Operating Systemsጋሻዬ አዱኛNo ratings yet
- Application Level Protocol Design: Concurrent & Distributed Software SystemsDocument11 pagesApplication Level Protocol Design: Concurrent & Distributed Software SystemsMuthukrishnan NNo ratings yet
- Compiler Design 2Document14 pagesCompiler Design 2ayanNo ratings yet
- SL - No Topic: Sensitivity: Internal RestrictedDocument35 pagesSL - No Topic: Sensitivity: Internal RestrictedSUSHRUT MOHTURENo ratings yet
- Assignment 2 SolutionDocument5 pagesAssignment 2 SolutionRaza KazmiNo ratings yet
- Computer Organization and Design: Lecture: 3 Tutorial: 1 Practical: 0 Credit: 4Document123 pagesComputer Organization and Design: Lecture: 3 Tutorial: 1 Practical: 0 Credit: 4siddharthaNo ratings yet
- Data Flow Diagra Ms (DFDS)Document23 pagesData Flow Diagra Ms (DFDS)crack NDA Dehra dunNo ratings yet
- 05.ADO.NETDocument32 pages05.ADO.NETVicky JainNo ratings yet
- Distributed Architecture With A Multi-Master Approach: Available in Version 1.0Document41 pagesDistributed Architecture With A Multi-Master Approach: Available in Version 1.0tornatNo ratings yet
- Big Data Infrastructure: Week 2: Mapreduce Algorithm Design (2/2)Document55 pagesBig Data Infrastructure: Week 2: Mapreduce Algorithm Design (2/2)Lindsey HoffmanNo ratings yet
- Bill Process: Scan Product Enter No of Units Calc Bill: Dept Store Billing System DiscountDocument13 pagesBill Process: Scan Product Enter No of Units Calc Bill: Dept Store Billing System DiscountMir Mohammed AliNo ratings yet
- Lab 02Document7 pagesLab 02Ahmed Razi UllahNo ratings yet
- Creating A Component (Recap) : Interface and Process BoundaryDocument5 pagesCreating A Component (Recap) : Interface and Process Boundarylabamba_123No ratings yet
- Secure Password Storage @OWASPChicagoDocument34 pagesSecure Password Storage @OWASPChicagoChloé O BryanNo ratings yet
- 1009 - SQL TuningDocument24 pages1009 - SQL TuningJulio Cuevas CasanovaNo ratings yet
- Register Transfer and Microoperations2017-3-5Document21 pagesRegister Transfer and Microoperations2017-3-5abenezer g/kirstosNo ratings yet
- Middleware: Seminar Web Services"Document37 pagesMiddleware: Seminar Web Services"Navigator VickyNo ratings yet
- DEF CON 23 - Sean-Metcalf-Red-vs-Blue-AD-Attack-and-DefenseDocument81 pagesDEF CON 23 - Sean-Metcalf-Red-vs-Blue-AD-Attack-and-DefensebaderNo ratings yet
- Accawhatiscryptio 1659471254758Document22 pagesAccawhatiscryptio 1659471254758ElvaNo ratings yet
- Conversion FunctionsDocument4 pagesConversion FunctionsBruno GuedesNo ratings yet
- Lec05 Introduction To Macros and SRAM LintDocument48 pagesLec05 Introduction To Macros and SRAM Lintyanjia8161100No ratings yet
- Subject: Database Management System CODE: 4CS4 - 05 UNIT: 04 Transaction ProcessingDocument62 pagesSubject: Database Management System CODE: 4CS4 - 05 UNIT: 04 Transaction ProcessingAyush JainNo ratings yet
- DSP 5050Document5 pagesDSP 5050Iván GonzálezNo ratings yet
- ProInspect Registry KeysDocument45 pagesProInspect Registry KeyspippomartelloNo ratings yet
- LEA A 128-Bit Block Cipher Datasheets-KoreanDocument26 pagesLEA A 128-Bit Block Cipher Datasheets-Koreanamal_dika5032No ratings yet
- Mission-Critical Microsoft Exchange 2003: Designing and Building Reliable Exchange ServersFrom EverandMission-Critical Microsoft Exchange 2003: Designing and Building Reliable Exchange ServersRating: 4 out of 5 stars4/5 (1)
- Wikipedia: Site Internals (Workbook 2007)Document30 pagesWikipedia: Site Internals (Workbook 2007)anon-656305100% (6)
- Tim Hawkins: or "How To Survive The Digg or Slashdot Effect"Document34 pagesTim Hawkins: or "How To Survive The Digg or Slashdot Effect"Robert Guiscard100% (10)
- Explain PlanDocument5 pagesExplain PlanFerasHamdanNo ratings yet
- SQL Statements - Create Synonym To Drop Rollback Segment, 9 of 31Document5 pagesSQL Statements - Create Synonym To Drop Rollback Segment, 9 of 31santiiyNo ratings yet
- Operating System MCQ ImopoDocument3 pagesOperating System MCQ ImopoNavdeep SinghNo ratings yet
- Webutil DocumentationDocument5 pagesWebutil Documentationsweta29No ratings yet
- A Project Report ON Library Management System: Niranjan KC Sagar Kunjyang Tamang Prajwal BhandariDocument14 pagesA Project Report ON Library Management System: Niranjan KC Sagar Kunjyang Tamang Prajwal BhandariAshish NepalNo ratings yet
- Relationship Diagram (ER Diagram)Document33 pagesRelationship Diagram (ER Diagram)JESHUA MARK BAYNo ratings yet
- MySQL, LINQ and The ADO NET Entity FrameworkDocument32 pagesMySQL, LINQ and The ADO NET Entity FrameworkOleksiy Kovyrin100% (10)
- Use Case Fully DressedDocument9 pagesUse Case Fully DressedAli SyedNo ratings yet
- Using MIS 3e: David KroenkeDocument40 pagesUsing MIS 3e: David Kroenkenorsiah_shukeriNo ratings yet
- ArraysDocument15 pagesArraysd ponnapalliNo ratings yet
- HandoutSample Preservation Letter-1438978445486Document2 pagesHandoutSample Preservation Letter-1438978445486sasakrstNo ratings yet
- Backup and Restore Interview Question and AnswersDocument2 pagesBackup and Restore Interview Question and AnswersAnwar Hayat100% (1)
- Handout 2 - Introduction To SQL ServerDocument6 pagesHandout 2 - Introduction To SQL Serverabdi100% (1)
- Odbc Setup GuideDocument5 pagesOdbc Setup GuideCharan Kumar PNo ratings yet
- Introduction To Computers and Information Technology: Chapter 9: Database BasicsDocument20 pagesIntroduction To Computers and Information Technology: Chapter 9: Database BasicsAbdullah AldwsryNo ratings yet
- Correcting The - Ve Valuated Stock by Cancelling Material DocumentDocument7 pagesCorrecting The - Ve Valuated Stock by Cancelling Material Documentamol_di1743No ratings yet
- KishoreDocument4 pagesKishorehariprasadreddy008No ratings yet
- AdamDocument4 pagesAdamVenkata Subrahmanyam KalagaNo ratings yet
- Data Warehouse Final ReportDocument19 pagesData Warehouse Final ReportLi BredNo ratings yet
- Less16 RecoveryDocument22 pagesLess16 Recoverymca_javaNo ratings yet
- MCQ On ARRAYDocument22 pagesMCQ On ARRAYShweta ShahNo ratings yet
- AX40 DatamodelDocument156 pagesAX40 Datamodelaxapta7No ratings yet
- Useful Commands-BrocadeDocument1 pageUseful Commands-BrocadeMrityunjoy KunduNo ratings yet
- Red Hat Ceph Storage-1.2.3-Red Hat Ceph Architecture-En-USDocument24 pagesRed Hat Ceph Storage-1.2.3-Red Hat Ceph Architecture-En-USkunalsingNo ratings yet
- Database Systems For Software Engineers SOEN 363 - Winter 2023 Assignment 1Document5 pagesDatabase Systems For Software Engineers SOEN 363 - Winter 2023 Assignment 1Elon DuskNo ratings yet
- Open XML Deep DiveDocument81 pagesOpen XML Deep DivePhalgun MaddaliNo ratings yet
- Midterm Cheat SheetDocument2 pagesMidterm Cheat SheetspopNo ratings yet
- IP Record File St. Anselm Term 2Document55 pagesIP Record File St. Anselm Term 2Harsh Vardhan Singh TanwarNo ratings yet