You might also like
- The Complete SEO Checklist For 2020 PDFDocument37 pagesThe Complete SEO Checklist For 2020 PDFNikita Shevchenko91% (11)
- Annie Cushing's Must-Have ToolsDocument67 pagesAnnie Cushing's Must-Have ToolsBuk MarkzNo ratings yet
- Annie Cushing's Must-Have ToolsDocument67 pagesAnnie Cushing's Must-Have ToolsBuk MarkzNo ratings yet
- Itseo Zone - The Digital AgencyDocument21 pagesItseo Zone - The Digital AgencyNews TimesNo ratings yet
- Author Accounts Update Sheet (Hamid SEO)Document50 pagesAuthor Accounts Update Sheet (Hamid SEO)Abdullah0% (1)
- SEO ResumeDocument6 pagesSEO Resumesantoshweb100% (2)
- Seo-Smo Activities PDFDocument27 pagesSeo-Smo Activities PDFAditya SinghNo ratings yet
- Solve SEO Challenges With Data Science Using PythonDocument596 pagesSolve SEO Challenges With Data Science Using PythonEleuterio Antagónico100% (2)
- How To Get .Edu Backlinks Easy & QuicklyDocument10 pagesHow To Get .Edu Backlinks Easy & QuicklySumon Abdul KaderNo ratings yet
- SEO Beginners Slide ShowDocument44 pagesSEO Beginners Slide Showyawar sajadkNo ratings yet
- Quarter 2 Week2Document3 pagesQuarter 2 Week2Juditha AniñonNo ratings yet
- SEO & Google SEODocument60 pagesSEO & Google SEOHumayunNo ratings yet
- On Site Factors Factors Importance (Why?) Value (If Any) How Does Your Site Score Action (If Any)Document9 pagesOn Site Factors Factors Importance (Why?) Value (If Any) How Does Your Site Score Action (If Any)Shyamendra Kushwaha0% (1)
- Search Engine Optimization: An Introduction To Optimizing Your Web Site For Best Possible Search Engine ResultsDocument43 pagesSearch Engine Optimization: An Introduction To Optimizing Your Web Site For Best Possible Search Engine ResultsPiyush ChavanNo ratings yet
- Competitor AnalysisDocument4 pagesCompetitor Analysis007sizan123No ratings yet
- Web MiningDocument28 pagesWeb MiningAkilesh Peethambaram100% (3)
- Search EngineDocument35 pagesSearch Engine『HW』 DOBBYNo ratings yet
- SEO GlossaryDocument6 pagesSEO GlossaryCésar DelgadoNo ratings yet
- Working of Webb Search EnginesDocument29 pagesWorking of Webb Search EnginesMohammed Azzan PatniNo ratings yet
- Search Engine Optimization (SEO) : Mark Branom Continuing Studies CS 22Document50 pagesSearch Engine Optimization (SEO) : Mark Branom Continuing Studies CS 22Anshul BhallaNo ratings yet
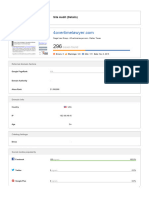
- SEOptimer SEO Report SampleDocument11 pagesSEOptimer SEO Report Sampleedukacija11No ratings yet
- Implementation and Analysis of Google's Page Rank Algorithm Using Network DatasetDocument5 pagesImplementation and Analysis of Google's Page Rank Algorithm Using Network DatasetriyaNo ratings yet
- SEO ReportDocument11 pagesSEO ReportNilesh Kumar ChoudharyNo ratings yet
- 1 Domain 2 IP Address 3 Domain Age 4 Domain Authority 5 Total Number of Indexed Pages in Google 6 Last Caching DateDocument13 pages1 Domain 2 IP Address 3 Domain Age 4 Domain Authority 5 Total Number of Indexed Pages in Google 6 Last Caching DateImperial universitiesNo ratings yet
- Project Part 2Document29 pagesProject Part 2Rajath K RNo ratings yet
- Google PDFDocument58 pagesGoogle PDFAyin NikyNo ratings yet
- NKD Pizza SEO PresentationDocument20 pagesNKD Pizza SEO PresentationPrakashKumarDuttaNo ratings yet
- BizAmpsLink Research - Inbound Links - Moz Pro PDFDocument2 pagesBizAmpsLink Research - Inbound Links - Moz Pro PDFakshatkharbandaNo ratings yet
- Audit Results For EdugritzDocument12 pagesAudit Results For Edugritzrafikul123No ratings yet
- WebmininglecDocument75 pagesWebmininglecPadmini A. AgnihotriNo ratings yet
- E Cient Crawling Through URL OrderingDocument18 pagesE Cient Crawling Through URL OrderingRenZo MesquitaNo ratings yet
- Faceted Navigation - Everyone Is Doing It Wrong 2020 - Botify CrawlerDocument44 pagesFaceted Navigation - Everyone Is Doing It Wrong 2020 - Botify CrawlerNicolás D'AndradeNo ratings yet
- Search Engine OptimizationDocument28 pagesSearch Engine OptimizationchetnadNo ratings yet
- SEO Score: 17 FailedDocument12 pagesSEO Score: 17 FailedlinkedNo ratings yet
- Book 2Document3 pagesBook 2prashant01811No ratings yet
- Search Engine Optimization: July 2019Document98 pagesSearch Engine Optimization: July 2019Mina YoussefNo ratings yet
- Detecting Spam Web Pages: Marc NajorkDocument30 pagesDetecting Spam Web Pages: Marc NajorkdiranjNo ratings yet
- 6 SEO Health CheckupDocument13 pages6 SEO Health CheckupMamata SreenivasNo ratings yet
- 15 Best SEO Tools For Content PlanningDocument18 pages15 Best SEO Tools For Content PlanningNarrato SocialNo ratings yet
- SEO Check List - DetailDocument3 pagesSEO Check List - Detailrileyghost622No ratings yet
- 2024 Ranking Factors Study ENGDocument99 pages2024 Ranking Factors Study ENGm8621115No ratings yet
- Audit Templete by Khalid FarhanDocument11 pagesAudit Templete by Khalid FarhanEmran HossainNo ratings yet
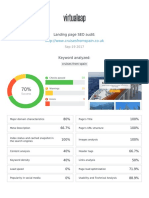
- Landing Page SEO Audit:: Cruises From SpainDocument29 pagesLanding Page SEO Audit:: Cruises From SpainMohammad Neyamath Ullah SaqlainNo ratings yet
- Website Audit Report Www4overtimelawyercom 20151103Document30 pagesWebsite Audit Report Www4overtimelawyercom 20151103gmapsextractor48No ratings yet
- Htmlcheatsheet Com SeoDocument21 pagesHtmlcheatsheet Com SeoyusufmbubeNo ratings yet
- Search Engine Optimisation: DR Ajitabh DashDocument20 pagesSearch Engine Optimisation: DR Ajitabh DashAditya GuptaNo ratings yet
- SearchLand: Search Quality For BeginnersDocument29 pagesSearchLand: Search Quality For BeginnersvcvpaivaNo ratings yet
- SEO Audit Checklist ESDM 2322Document4 pagesSEO Audit Checklist ESDM 2322Fariha FerdowsNo ratings yet
- 200 Website Ranking FactorDocument10 pages200 Website Ranking Factorsoorajas602No ratings yet
- Pingraphs On-Page Audit: About WebsiteDocument10 pagesPingraphs On-Page Audit: About WebsitemursalinNo ratings yet
- Atlas PavementDocument12 pagesAtlas PavementnikhilNo ratings yet
- Website AnalyzerDocument15 pagesWebsite Analyzerapi-238604507No ratings yet
- DWM PresentationDocument18 pagesDWM PresentationPratik ShrivastavNo ratings yet
- Web MiningpptDocument29 pagesWeb MiningpptTeresa SebastianNo ratings yet
- Chritell ClinicDocument34 pagesChritell ClinicHeshan AsithaNo ratings yet
- SEO Ranking Factors 2010 SMX LondonDocument26 pagesSEO Ranking Factors 2010 SMX Londonrandfish100% (4)
- Website Audit ReportDocument9 pagesWebsite Audit ReportSimranjeet KaurNo ratings yet
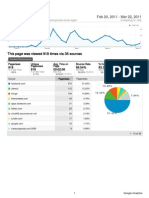
- Referral Traffic Overview - April 2020Document2 pagesReferral Traffic Overview - April 2020Gazi ForhadNo ratings yet
- Web Search EngineDocument26 pagesWeb Search Enginepradhanritesh6No ratings yet
- Module 1 - Search Engine BasicsDocument79 pagesModule 1 - Search Engine BasicsPRIYANKA TARACHANDANINo ratings yet
- Web AnalyticsDocument11 pagesWeb AnalyticsRiya LokhandeNo ratings yet
- Domain Level Audit: 1. Site CommandDocument15 pagesDomain Level Audit: 1. Site Commandjoker13No ratings yet
- Website SEO Audit Checklist-LitashikderDocument13 pagesWebsite SEO Audit Checklist-Litashikderbitc96288No ratings yet
- Analytics - Contest Blog Post Entrance Sources PercentagesDocument1 pageAnalytics - Contest Blog Post Entrance Sources Percentageshill4reelNo ratings yet
- Hamro Pradesh: Crawled Urls User Agent Crawl PeriodDocument95 pagesHamro Pradesh: Crawled Urls User Agent Crawl PeriodHimal GhimireNo ratings yet
- Free Advertising Credits Worth $600-$800Document3 pagesFree Advertising Credits Worth $600-$800picesaw859No ratings yet
- Mario Brown Seo TakeoverDocument17 pagesMario Brown Seo TakeoverMagenta HagemiNo ratings yet
- FX 3900 PVDocument194 pagesFX 3900 PVthomasoburNo ratings yet
- English: Quarter 2 - Module 2 Electronic Search EngineDocument26 pagesEnglish: Quarter 2 - Module 2 Electronic Search EngineMICHAEL USTARENo ratings yet
- Seach EngineDocument18 pagesSeach Enginescribdraulscribd50% (2)
- SEO Checklist by H-EducateDocument5 pagesSEO Checklist by H-Educatevyshnavi PotnuriNo ratings yet
- Search Engine OptimizationDocument17 pagesSearch Engine Optimization18BCS4038- KAVYADHARSINI PNo ratings yet
- Pedidos 1Document64 pagesPedidos 1Pablo UzNo ratings yet
- Canon Canonet ql17 User ManualDocument29 pagesCanon Canonet ql17 User Manual2080814941No ratings yet
- Toyota Crown User Manual 1973Document50 pagesToyota Crown User Manual 1973Brian DirouNo ratings yet
- 15 Torrent WebsitesDocument2 pages15 Torrent Websitessanju2011No ratings yet
- XML SitemapDocument1 pageXML SitemapHoodtrendsNo ratings yet
- Keyword Research and Competition AnalysisDocument12 pagesKeyword Research and Competition AnalysisWellness & FreedomNo ratings yet
- सामाजिक अध्ययन तथा जीवन उपयोगी शिक्षाDocument208 pagesसामाजिक अध्ययन तथा जीवन उपयोगी शिक्षाBijay Aryan DhakalNo ratings yet
- Keyword Research Cheat SheetDocument2 pagesKeyword Research Cheat SheetDovlaNo ratings yet
- I.I.T. Physics Volume-I - Dr. P. K. Agarwal - Google BooksDocument1 pageI.I.T. Physics Volume-I - Dr. P. K. Agarwal - Google BooksCareerslike Consultancy40% (5)
- MIR 1512 SEOPlatfrmDocument78 pagesMIR 1512 SEOPlatfrmThong Tran (ThongTran SEO)No ratings yet
- Terminal TackleDocument160 pagesTerminal TackleStart AmazonNo ratings yet
- t90 Instruction ManualDocument53 pagest90 Instruction ManualPataki SandorNo ratings yet
- DriveDocument1 pageDriveMxplatform Mx PlatformNo ratings yet
- Canon Uc - 1 - Hi ManualDocument118 pagesCanon Uc - 1 - Hi ManualWil van SchadewijkNo ratings yet
- 0804 Google DomainsDocument239 pages0804 Google DomainsTechCrunch100% (2)
- Mysearchengines 150208065440 Conversion Gate02Document22 pagesMysearchengines 150208065440 Conversion Gate02Franz Lawrenz De TorresNo ratings yet
- (Reliablesoft - Net) SEO Basics Mini Course 2021Document35 pages(Reliablesoft - Net) SEO Basics Mini Course 2021Huỳnh Lê Quang ĐệNo ratings yet