You might also like
- Lecture18 HMMs Part1Document28 pagesLecture18 HMMs Part1Krishnavishal VemulaNo ratings yet
- Markov Processes MengDocument29 pagesMarkov Processes Mengrfoliveira1975No ratings yet
- ASR System: Rashmi KethireddyDocument28 pagesASR System: Rashmi KethireddyRakesh PatelNo ratings yet
- Clock Domain CrossingDocument5 pagesClock Domain CrossingRAGUL RAJ SNo ratings yet
- Tmp939a TMPDocument17 pagesTmp939a TMPFrontiersNo ratings yet
- Hidden Markov Models (HMMS) : Prabhleen Juneja Thapar Institute of Engineering & TechnologyDocument36 pagesHidden Markov Models (HMMS) : Prabhleen Juneja Thapar Institute of Engineering & TechnologyRohan SharmaNo ratings yet
- Lecture5 hmms1Document37 pagesLecture5 hmms1Beyene TsegayeNo ratings yet
- Lecture 8: State-Space Models Based On Slides By: Probabilis C Graphical ModelsDocument29 pagesLecture 8: State-Space Models Based On Slides By: Probabilis C Graphical ModelsRohit PandeyNo ratings yet
- CD-HMM For Normal Sinus Rhythm: V.K.Srivastava, Dr. Devendra PrasadDocument4 pagesCD-HMM For Normal Sinus Rhythm: V.K.Srivastava, Dr. Devendra PrasadInternational Journal of computational Engineering research (IJCER)No ratings yet
- Consistency of The EKF-SLAM Algorithm: Tim Bailey, Juan Nieto, Jose Guivant, Michael Stevens and Eduardo NebotDocument7 pagesConsistency of The EKF-SLAM Algorithm: Tim Bailey, Juan Nieto, Jose Guivant, Michael Stevens and Eduardo NebotHBNo ratings yet
- Hidden Markov ModelssDocument59 pagesHidden Markov ModelssAna MariaNo ratings yet
- Applications of Hidden Markov Models PDFDocument30 pagesApplications of Hidden Markov Models PDFHshdjdud SjdhdjsjjsNo ratings yet
- PCB Lect06 HMMDocument55 pagesPCB Lect06 HMMbalj balhNo ratings yet
- Gene Finding and HMMS: 6.096 - Algorithms For Computational Biology - Lecture 7Document69 pagesGene Finding and HMMS: 6.096 - Algorithms For Computational Biology - Lecture 7fvenkyNo ratings yet
- 18ECC206J - Lab Experiment 3 - Revised - Feb-2023Document7 pages18ECC206J - Lab Experiment 3 - Revised - Feb-2023KONASANI HARSHITH (RA2011004010349)No ratings yet
- Inv Delay Link 1Document5 pagesInv Delay Link 1kapilcooldudeNo ratings yet
- Applying-Hidden Markov Models To BioinformaticsDocument28 pagesApplying-Hidden Markov Models To BioinformaticsasherNo ratings yet
- Hidden Markov Model Methods: Submitted byDocument11 pagesHidden Markov Model Methods: Submitted bylokeshk_46No ratings yet
- Lec-6 HMMDocument63 pagesLec-6 HMMGia ByNo ratings yet
- On-Line Viterbi Algorithm For Analysis of Long Biological SequencesDocument12 pagesOn-Line Viterbi Algorithm For Analysis of Long Biological Sequencesfjair_10No ratings yet
- Markov ChainsDocument22 pagesMarkov ChainsAnonymous XybLZfNo ratings yet
- Hidden Markov Model in Automatic Speech RecognitionDocument29 pagesHidden Markov Model in Automatic Speech Recognitionvipkute0901No ratings yet
- Markov - Hidden MarkovDocument32 pagesMarkov - Hidden MarkovSIDRA ALI MA ECO DEL 2021-23No ratings yet
- Probabilidadesde TransicionDocument40 pagesProbabilidadesde TransicionLuis CorteNo ratings yet
- Hidden Markov Model: Le HMM - IpynbDocument2 pagesHidden Markov Model: Le HMM - IpynbRoushan GiriNo ratings yet
- Machine Learning For Natural Language Processing: Hidden Markov ModelsDocument33 pagesMachine Learning For Natural Language Processing: Hidden Markov ModelsHưngNo ratings yet
- Sequence Model:: Hidden Markov ModelsDocument60 pagesSequence Model:: Hidden Markov Models21020641No ratings yet
- Cis262 HMMDocument34 pagesCis262 HMMAndrej IlićNo ratings yet
- Cellular Automata: Based Mostly On Dr. Richard Spillman Class On Alternative Computing in Summer 2000Document29 pagesCellular Automata: Based Mostly On Dr. Richard Spillman Class On Alternative Computing in Summer 2000yashikabirdiNo ratings yet
- Parametric Models Hidden Markov ModelsDocument30 pagesParametric Models Hidden Markov Modelsbill.morrissonNo ratings yet
- DSD Lab Manual 5 21 CPDocument6 pagesDSD Lab Manual 5 21 CPUsman AbdullahNo ratings yet
- Title: Hidden Markov Model: Hidden Markov Model The States That Were Responsible For Emitting The Various Symbols AreDocument5 pagesTitle: Hidden Markov Model: Hidden Markov Model The States That Were Responsible For Emitting The Various Symbols AreVivek BarsopiaNo ratings yet
- Sequence Model:: Hidden Markov ModelsDocument58 pagesSequence Model:: Hidden Markov ModelsKỉ Nguyên Hủy DiệtNo ratings yet
- 10 ISD 2022-23 Part3 TP2 FSM AnalysisDocument29 pages10 ISD 2022-23 Part3 TP2 FSM AnalysisPedro NevesNo ratings yet
- Topologically Massive GravityDocument54 pagesTopologically Massive Gravitymichael101101No ratings yet
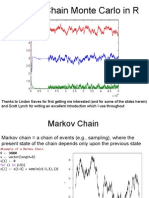
- Markov Chain Monte Carlo in RDocument14 pagesMarkov Chain Monte Carlo in RCươngNguyễnBáNo ratings yet
- Rising Edge Detector, Debounce CKT, Testing CKT For ThatDocument10 pagesRising Edge Detector, Debounce CKT, Testing CKT For ThataminhardNo ratings yet
- Breaking The Simulation Barrier: SRAM Evaluation Through Norm MinimizationDocument8 pagesBreaking The Simulation Barrier: SRAM Evaluation Through Norm MinimizationTanmoy RoyNo ratings yet
- FHMM MLDocument31 pagesFHMM MLHeru PraptonoNo ratings yet
- Sistemas de ControlDocument17 pagesSistemas de ControlVIRUSINOFENCIVONo ratings yet
- Introduction To Machine Learning CMU-10701: Hidden Markov ModelsDocument30 pagesIntroduction To Machine Learning CMU-10701: Hidden Markov Modelsricksant2003No ratings yet
- Introduction To HMMDocument38 pagesIntroduction To HMMDispensasi unipasbyNo ratings yet
- Introduction To Hidden Markov ModelsDocument31 pagesIntroduction To Hidden Markov ModelsAnshy SinghNo ratings yet
- An Incremental Viterbi Algorithm For Large Sequence Hidden Markov ModelsDocument7 pagesAn Incremental Viterbi Algorithm For Large Sequence Hidden Markov Modelsjason bobbinNo ratings yet
- SvarDocument27 pagesSvarMirza KudumovićNo ratings yet
- Hidden Markov Model (HMM) Tutorial: Home Ciphers Cryptanalysis Hashes ResourcesDocument5 pagesHidden Markov Model (HMM) Tutorial: Home Ciphers Cryptanalysis Hashes ResourcesMasud SarkerNo ratings yet
- Hidden Markov ModelsDocument51 pagesHidden Markov ModelsSauki RidwanNo ratings yet
- Dynamic Monte Carlo Methods: Theory and ApplicationsDocument42 pagesDynamic Monte Carlo Methods: Theory and Applicationsgump_813No ratings yet
- Parameter Estimation: Leonid KoganDocument41 pagesParameter Estimation: Leonid Koganseanwu95No ratings yet
- Hidden Markov Model: Abstract: HMM Is Probabilistic Model For Machine Learning. It Is Mostly Used inDocument9 pagesHidden Markov Model: Abstract: HMM Is Probabilistic Model For Machine Learning. It Is Mostly Used inchala mitafaNo ratings yet
- Case 2Document3 pagesCase 2decapodabrachyNo ratings yet
- Visualize RF Impairments - MATLAB & Simulink - MathWorks IndiaDocument15 pagesVisualize RF Impairments - MATLAB & Simulink - MathWorks Indiatiblue.black.36No ratings yet
- Aspects of Certified Randomness From Quantum Supremacy: Scott Aaronson (UT Austin)Document22 pagesAspects of Certified Randomness From Quantum Supremacy: Scott Aaronson (UT Austin)JerimiahNo ratings yet
- HMM NotesDocument2 pagesHMM NotesdrewbarbsNo ratings yet
- Micro and Nano Scale Flow - Direct Simulation Monte Carlo (DSMC)Document16 pagesMicro and Nano Scale Flow - Direct Simulation Monte Carlo (DSMC)Behzad Mohajer100% (2)
- Cu HMMDocument13 pagesCu HMMRupesh ParabNo ratings yet
- Aim of The Experiment: System Identification of DC Motor Using Matlab/Labview. Equipments RequiredDocument10 pagesAim of The Experiment: System Identification of DC Motor Using Matlab/Labview. Equipments Requiredpriyatosh dashNo ratings yet
- Algorithms - Hidden Markov ModelsDocument7 pagesAlgorithms - Hidden Markov ModelsMani NadNo ratings yet
- Wireless Comm Systems2Document23 pagesWireless Comm Systems2abdulsahibNo ratings yet
- Spatial Pattern of Rural Settlements Types in Jhargram District of West Bengal: A Comparative StudyDocument6 pagesSpatial Pattern of Rural Settlements Types in Jhargram District of West Bengal: A Comparative StudyIndrajit PalNo ratings yet
- My Brain Is A Stick of Butter Alt Design AttemptDocument16 pagesMy Brain Is A Stick of Butter Alt Design AttemptSteve RobicheauNo ratings yet
- Modul Kulit SsDocument22 pagesModul Kulit Ssshafiraa29No ratings yet
- Pathogen Research AssignmentDocument2 pagesPathogen Research AssignmentDeven BaliNo ratings yet
- Creative Thinking of Low Academic Student Undergoing Search S PDFDocument18 pagesCreative Thinking of Low Academic Student Undergoing Search S PDFgiyonoNo ratings yet
- Philippine Contemporary FictionDocument8 pagesPhilippine Contemporary FictionRhea Batiller LozanesNo ratings yet
- Stronetz, A Faithful Physician, Is Also Very Loyal To The Prince Demitri. The KranitzkiDocument2 pagesStronetz, A Faithful Physician, Is Also Very Loyal To The Prince Demitri. The KranitzkiSahil PrasharNo ratings yet
- THE DESIDERATA by LES CRANEDocument2 pagesTHE DESIDERATA by LES CRANEHErSON LUNo ratings yet
- Warren Larsen Chp1 (Principles of Accounting)Document147 pagesWarren Larsen Chp1 (Principles of Accounting)annie100% (1)
- Effect of The Acts of Worship On The Muslim's LifeDocument17 pagesEffect of The Acts of Worship On The Muslim's LifeZakaria BelloulaNo ratings yet
- January 6th Committee Hints at A Failed Congressional Coup'Document5 pagesJanuary 6th Committee Hints at A Failed Congressional Coup'siesmannNo ratings yet
- National Bankruptcy Services The LedgerDocument28 pagesNational Bankruptcy Services The LedgerOxigyneNo ratings yet
- GALLARDO, Glena M.: City University of Pasay Bachelor of Science Administration (Bsba) Major in Operations ManagementDocument1 pageGALLARDO, Glena M.: City University of Pasay Bachelor of Science Administration (Bsba) Major in Operations ManagementGlena Jean GallardoNo ratings yet
- PROGRESSIVE DEVELOPMENT CORP v. LAGUESMADocument1 pagePROGRESSIVE DEVELOPMENT CORP v. LAGUESMAdasfghkjlNo ratings yet
- Pseudo-Mechanistic Explanations in Psychology and Cognitive NeuroscienceDocument12 pagesPseudo-Mechanistic Explanations in Psychology and Cognitive NeuroscienceMarianaNo ratings yet
- No Rest For The Wicked (LotFP)Document34 pagesNo Rest For The Wicked (LotFP)Paulo Ricardo100% (1)
- Pobre Vs Mendieta GR 106677Document7 pagesPobre Vs Mendieta GR 106677Judel MatiasNo ratings yet
- ALFONSO - Double Sales - ArtDocument4 pagesALFONSO - Double Sales - ArtAlfonso DimlaNo ratings yet
- (Gelfand - Glagoleva - Kirilov) The Method of Coordinates PDFDocument77 pages(Gelfand - Glagoleva - Kirilov) The Method of Coordinates PDFحكيم الفيلسوف الضائع100% (9)
- Milestone 2 Persona TemplateDocument4 pagesMilestone 2 Persona TemplateNtinaGanesNo ratings yet
- (9789004383487 - The Skandapurā A Volume IV) IntroductionDocument29 pages(9789004383487 - The Skandapurā A Volume IV) IntroductionRoman OgnevyukNo ratings yet
- Installing Red Hat Enterprise Linux 6 On VirtualBox 4Document2 pagesInstalling Red Hat Enterprise Linux 6 On VirtualBox 4maulishNo ratings yet
- Articulated Light: The Emergence of Abstract Film in AmericaDocument16 pagesArticulated Light: The Emergence of Abstract Film in AmericaitkusNo ratings yet
- Literary Criticism of Graham GreeneDocument4 pagesLiterary Criticism of Graham GreeneAmylea SyazlinaNo ratings yet
- Tep Lesson Plan 2Document3 pagesTep Lesson Plan 2api-376073512No ratings yet
- Circular Flow of Income Prep 2Document5 pagesCircular Flow of Income Prep 2Tianlu WangNo ratings yet
- 1.1 EXPOSURE (Sketching The Map of A School Showing Its Structures:) Draw Your Map Here. Name of School: Marcelino Fule Memorial CollegeDocument6 pages1.1 EXPOSURE (Sketching The Map of A School Showing Its Structures:) Draw Your Map Here. Name of School: Marcelino Fule Memorial CollegeJalenne NolledoNo ratings yet
- EDSP 5320-D03 Spring 2020 Sunshine Valdilles - Project 2Document2 pagesEDSP 5320-D03 Spring 2020 Sunshine Valdilles - Project 2Sunshine Corliss ValdillesNo ratings yet
- 6 People Vs LasacaDocument1 page6 People Vs Lasacamei atienzaNo ratings yet
- Plate Tectonic Web QuestDocument5 pagesPlate Tectonic Web QuestEvan CandyNo ratings yet