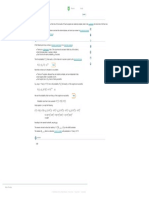
You might also like
- CHAPTER 12 Analysis of VarianceDocument49 pagesCHAPTER 12 Analysis of VarianceAyushi JangpangiNo ratings yet
- Multivariate Analysis: Are Some of The Variables Dependent On Others?Document16 pagesMultivariate Analysis: Are Some of The Variables Dependent On Others?rahul100% (1)
- ML SasDocument17 pagesML SasmartdiazNo ratings yet
- Factor Analysis FullDocument61 pagesFactor Analysis FullcuachanhdongNo ratings yet
- 01 Multivariate AnalysisDocument40 pages01 Multivariate Analysisxc123544100% (1)
- Bivariate Data Analysis TechniquesDocument4 pagesBivariate Data Analysis Techniquesalexis balmoresNo ratings yet
- RMM NotesDocument177 pagesRMM NotesVahni SinghNo ratings yet
- MST-004 - Statistical Inference PDFDocument415 pagesMST-004 - Statistical Inference PDFSRAVANII GOTTIMUKKALANo ratings yet
- Creative Idea Bulb PowerPoint TemplateDocument36 pagesCreative Idea Bulb PowerPoint TemplateReza Adhi NugrohoNo ratings yet
- Multivariate Analysis – The Simplest Guide in the Universe: Bite-Size Stats, #6From EverandMultivariate Analysis – The Simplest Guide in the Universe: Bite-Size Stats, #6No ratings yet
- CH 13Document38 pagesCH 13Imam AwaluddinNo ratings yet
- Missing Value TreatmentDocument22 pagesMissing Value TreatmentrphmiNo ratings yet
- Understanding Variables in StatisticsDocument23 pagesUnderstanding Variables in StatisticsAme DamneeNo ratings yet
- One-Tailed vs Two-Tailed Tests in StatisticsDocument3 pagesOne-Tailed vs Two-Tailed Tests in StatisticsMadhav RajbanshiNo ratings yet
- KINDS OF VARIABLESDocument33 pagesKINDS OF VARIABLESGan BenicoNo ratings yet
- Discriminant Analysis ExplainedDocument8 pagesDiscriminant Analysis Explained04 Shaina SachdevaNo ratings yet
- Econometrics 4Document37 pagesEconometrics 4Anunay ChoudharyNo ratings yet
- Lesson Plans in Urdu SubjectDocument10 pagesLesson Plans in Urdu SubjectNoor Ul AinNo ratings yet
- Discriminant Analysis: Prepared By-Sumit JainDocument44 pagesDiscriminant Analysis: Prepared By-Sumit Jainsumitjain_amcap5571No ratings yet
- Q. 1 How Is Mode Calculated? Also Discuss Its Merits and Demerits. AnsDocument13 pagesQ. 1 How Is Mode Calculated? Also Discuss Its Merits and Demerits. AnsGHULAM RABANINo ratings yet
- Quantitative Data Analysis: Hypothesis TestingDocument12 pagesQuantitative Data Analysis: Hypothesis TestingAtila SalsabillaNo ratings yet
- ModelsDocument38 pagesModelssimonyohannes818No ratings yet
- Marketing Research-2Document6 pagesMarketing Research-2Aakanksha VermaNo ratings yet
- Discriminant AnalysisDocument29 pagesDiscriminant Analysisbalaa aiswaryaNo ratings yet
- Ant AnalysisDocument31 pagesAnt AnalysisPriya BhatterNo ratings yet
- Discriminant Analysis Chapter-SevenDocument7 pagesDiscriminant Analysis Chapter-SevenSoloymanNo ratings yet
- Regression PacketDocument27 pagesRegression PacketgedleNo ratings yet
- PSY301&PSY461 SPSS Practical Exercise ANCOVA With AnswersDocument10 pagesPSY301&PSY461 SPSS Practical Exercise ANCOVA With AnswersBelle GurdNo ratings yet
- Discriminant AnalysisDocument7 pagesDiscriminant AnalysisHisham ElhadidiNo ratings yet
- Discriminant Analysis, Logit Models & Multinomial Logit ExplainedDocument3 pagesDiscriminant Analysis, Logit Models & Multinomial Logit ExplainedSaloni GuptaNo ratings yet
- Comprehensive Guide to Data ExplorationDocument8 pagesComprehensive Guide to Data Explorationsnreddy b100% (1)
- Group 4 MANCOVADocument31 pagesGroup 4 MANCOVAbitterguardNo ratings yet
- Unit 1Document9 pagesUnit 1Saral ManeNo ratings yet
- Chapter Summary-2Document6 pagesChapter Summary-2Hitesh NigamNo ratings yet
- Group 8 OriDocument8 pagesGroup 8 OriZeeshan ch 'Hadi'No ratings yet
- BRM chp09Document41 pagesBRM chp09agarwalmonicaNo ratings yet
- Objectives of Discriminant AnalysisDocument4 pagesObjectives of Discriminant AnalysisNg. Minh ThảoNo ratings yet
- Educational StatisticsDocument12 pagesEducational StatisticsAsad NomanNo ratings yet
- Multivariate AnalysisDocument7 pagesMultivariate AnalysisGOMATHI ANo ratings yet
- Unit 1Document9 pagesUnit 1Saral ManeNo ratings yet
- LESSON - Quantitative Research DesignsDocument16 pagesLESSON - Quantitative Research DesignsHomer Kurt BugtongNo ratings yet
- Inferential StatisticsDocument22 pagesInferential StatisticsTrixie MengulloNo ratings yet
- Multivariate Statistical Analysis: Professor Dr. Muhammad Mohsin Butt Department of Marketing School of Business StudiesDocument8 pagesMultivariate Statistical Analysis: Professor Dr. Muhammad Mohsin Butt Department of Marketing School of Business Studiessaka haiNo ratings yet
- Research Methodology - Multi Variate Analysis 13 10 23Document17 pagesResearch Methodology - Multi Variate Analysis 13 10 23Muthu KumarNo ratings yet
- Multivariate Analysis-MRDocument8 pagesMultivariate Analysis-MRhemalichawlaNo ratings yet
- Q1. W3. The Nature of VariablesDocument3 pagesQ1. W3. The Nature of VariablesDazzleNo ratings yet
- A Guide To Data ExplorationDocument20 pagesA Guide To Data Explorationmike110*No ratings yet
- Topic - 9 PDFDocument12 pagesTopic - 9 PDFCiise Cismaan AadamNo ratings yet
- Terms To Learn: Notes in StatisticsDocument13 pagesTerms To Learn: Notes in StatisticsMichael JubayNo ratings yet
- Data Mining TechnicalDocument45 pagesData Mining TechnicalbhaveshNo ratings yet
- Discriminant Analysis TechniqueDocument7 pagesDiscriminant Analysis TechniquebalachmalikNo ratings yet
- Discriminant Analysis: How Can You Answer These Questions?Document14 pagesDiscriminant Analysis: How Can You Answer These Questions?Priya BhatNo ratings yet
- Linear Regression Analysis of Experimental Design and DataDocument12 pagesLinear Regression Analysis of Experimental Design and DataMuhammad kamran khanNo ratings yet
- PSYSTAT22 Lecture 1Document15 pagesPSYSTAT22 Lecture 1Kisha MontanoNo ratings yet
- Name: Muhammad Siddique Class: B.Ed. Semester: Fifth Subject: Inferential Statistics Submitted To: Sir Sajid AliDocument6 pagesName: Muhammad Siddique Class: B.Ed. Semester: Fifth Subject: Inferential Statistics Submitted To: Sir Sajid Aliusama aliNo ratings yet
- Basic Analytical ConceptsDocument12 pagesBasic Analytical ConceptsHimadri JanaNo ratings yet
- Advanced Statistics: Paper #6Document11 pagesAdvanced Statistics: Paper #6Precious NosaNo ratings yet
- Practical Research 2 Q1 Topic 2Document84 pagesPractical Research 2 Q1 Topic 2B9 K-Lem LopezNo ratings yet
- Lesson 3 - Research VariablesDocument29 pagesLesson 3 - Research VariablesEllamea BorjaNo ratings yet
- One Way FinalDocument9 pagesOne Way FinalDipayan Bhattacharya 478No ratings yet
- Name: Muhammad Siddique Class: B.Ed. Semester: Fifth Subject: Inferential Statistics Submitted To: Sir Sajid AliDocument5 pagesName: Muhammad Siddique Class: B.Ed. Semester: Fifth Subject: Inferential Statistics Submitted To: Sir Sajid Aliusama aliNo ratings yet
- Pred Test 2Document2 pagesPred Test 2Turner PikulinskiNo ratings yet
- Target: Before Proceeding Further, Check How Much You Know About BusinessDocument16 pagesTarget: Before Proceeding Further, Check How Much You Know About BusinessGhilany Carillo CacdacNo ratings yet
- Statistics Study NotesDocument71 pagesStatistics Study Notesbakajin00No ratings yet
- Business Club: Basic StatisticsDocument26 pagesBusiness Club: Basic StatisticsJustin Russo HarryNo ratings yet
- All About VariablesDocument61 pagesAll About VariablesSasji HasjNo ratings yet
- Height-For-Age BOYSDocument1 pageHeight-For-Age BOYSTheresia Lolita SetiawanNo ratings yet
- Kerangka Acuan PMKDocument2 pagesKerangka Acuan PMKTheresia Lolita SetiawanNo ratings yet
- Metolid - Quantitative Data AnalysisDocument26 pagesMetolid - Quantitative Data AnalysisTheresia Lolita SetiawanNo ratings yet
- Education Concept PowerPoint Templates WidescreenDocument3 pagesEducation Concept PowerPoint Templates WidescreenAlva SevenNo ratings yet
- Tutorial Akuntansi LanjutanDocument27 pagesTutorial Akuntansi LanjutanTheresia Lolita SetiawanNo ratings yet
- Materi To Interna 02 FebruariDocument75 pagesMateri To Interna 02 FebruariMario AlexanderNo ratings yet
- COVID 19 Anticoagulation Algorithm Version Final 1.1Document2 pagesCOVID 19 Anticoagulation Algorithm Version Final 1.1Emi PuspitasariNo ratings yet
- COVID-19 Simulation Case - A STABLE PATIENT WITH SUSPECTED COVID-19Document10 pagesCOVID-19 Simulation Case - A STABLE PATIENT WITH SUSPECTED COVID-19Theresia Lolita SetiawanNo ratings yet
- Solution AssignmentDocument34 pagesSolution AssignmentBizuayehu AyeleNo ratings yet
- Calculating variance and covariance: methods and formulasDocument3 pagesCalculating variance and covariance: methods and formulasGiorgia 1709No ratings yet
- Anova Two WayDocument2 pagesAnova Two WayNikhitha AdluriNo ratings yet
- Random Variable: Prepared By: Prof. Julie E. Avila Mr. Ronel R. AldayDocument24 pagesRandom Variable: Prepared By: Prof. Julie E. Avila Mr. Ronel R. AldayLeandro Jr. RomuloNo ratings yet
- A New Surgery Is Successful of The Time. If The Results of SuchDocument1 pageA New Surgery Is Successful of The Time. If The Results of Suchuswriting consultantsNo ratings yet
- Analyzing Algorithm Efficiency EmpiricallyDocument8 pagesAnalyzing Algorithm Efficiency EmpiricallysaiNo ratings yet
- AD3301 - Unit II Part 2.ipynb - ColaboratoryDocument4 pagesAD3301 - Unit II Part 2.ipynb - Colaboratorypalaniappan.cseNo ratings yet
- Assignment 1 AnswersDocument7 pagesAssignment 1 AnswersIzwan YusofNo ratings yet
- HmmsDocument59 pagesHmmsmatin ashrafiNo ratings yet
- Naive Bayesian Classification and Apriori Algorithm in RDocument9 pagesNaive Bayesian Classification and Apriori Algorithm in RLALITH SARANNo ratings yet
- DS1 Outline PGP Term 1 2021 - FirstDayDocument4 pagesDS1 Outline PGP Term 1 2021 - FirstDayEncore GamingNo ratings yet
- F Distribution TablesDocument5 pagesF Distribution TablesnawaNo ratings yet
- Channel Coding Schemes in GSM and UMTS: Presentation by Wajahat Ullah Khan Tatiana PourtovaDocument43 pagesChannel Coding Schemes in GSM and UMTS: Presentation by Wajahat Ullah Khan Tatiana PourtovadjhfdzuzuNo ratings yet
- Stats Spss ProjectDocument11 pagesStats Spss Projectmuhammadtaimoorkhan100% (12)
- Response Table For Analyze Taguchi Design: Learn More About Minitab 18Document11 pagesResponse Table For Analyze Taguchi Design: Learn More About Minitab 18psmonu54No ratings yet
- 18.S096 Problem Set Fall 2013: Stochastic CalculusDocument3 pages18.S096 Problem Set Fall 2013: Stochastic CalculusGagik AtabekyanNo ratings yet
- Point EstimationDocument13 pagesPoint EstimationTarun Goyal100% (1)
- Process Capability AnalysisDocument37 pagesProcess Capability Analysisabishank09100% (1)
- Panel Data Analysis Using EViews Chapter - 1 PDFDocument30 pagesPanel Data Analysis Using EViews Chapter - 1 PDFimohamed2No ratings yet
- Intercity Land Public Transport in Malaysia: A Case Study On Bus Users in Kuala Lumpur - Penang CorridorDocument14 pagesIntercity Land Public Transport in Malaysia: A Case Study On Bus Users in Kuala Lumpur - Penang CorridorAngelalia RozaNo ratings yet
- K.S. School of Engineering and Management, Bangalore - 560109Document2 pagesK.S. School of Engineering and Management, Bangalore - 560109Pradeep BiradarNo ratings yet
- Excercise 2Document2 pagesExcercise 2Shivam RaiNo ratings yet
- Construction Planning, Scheduling and ControlDocument26 pagesConstruction Planning, Scheduling and ControlSadaf ShahNo ratings yet
- Gulf Properties - FinalDocument22 pagesGulf Properties - FinalYati GuptaNo ratings yet
- ACTL 2003 Stochastic Models For Actuarial Applications Final ExaminationDocument12 pagesACTL 2003 Stochastic Models For Actuarial Applications Final ExaminationBobNo ratings yet