You might also like
- Workloads 02 TutorialDocument149 pagesWorkloads 02 TutorialsudheerNo ratings yet
- Modeling and Performance Evaluation of Network and Computer SystemsDocument19 pagesModeling and Performance Evaluation of Network and Computer SystemsRudren Eswaran KrishnanNo ratings yet
- TechniquesDocument34 pagesTechniquestameromar1971No ratings yet
- Network Performance Evaluation: Dr. Muazzam A. KhanDocument46 pagesNetwork Performance Evaluation: Dr. Muazzam A. KhanTayyab RafiqueNo ratings yet
- Scenario Questions Scheduling AlgorithmsDocument7 pagesScenario Questions Scheduling Algorithmssathvika.taduruNo ratings yet
- Deep Learning Basics Lecture 11 Practical MethodologyDocument25 pagesDeep Learning Basics Lecture 11 Practical MethodologybarisNo ratings yet
- 01introduction To SimulationDocument23 pages01introduction To SimulationRafelino LengkongNo ratings yet
- Fundamentals of Computer Design - 1Document32 pagesFundamentals of Computer Design - 1qwety300No ratings yet
- BCS 413 - Lecture5 - Replication - ConsistencyDocument25 pagesBCS 413 - Lecture5 - Replication - ConsistencyDesmond KampoeNo ratings yet
- Operating System Chapter 4 - MaDocument41 pagesOperating System Chapter 4 - MaSileshi Bogale HaileNo ratings yet
- Process Scheduling - 3Document28 pagesProcess Scheduling - 3StupefyNo ratings yet
- Network Performance Evaluation: Selection of Techniques and MetricsDocument35 pagesNetwork Performance Evaluation: Selection of Techniques and MetricsTayyab RafiqueNo ratings yet
- Cloud ComputingDocument10 pagesCloud Computingapi-273044715No ratings yet
- Modeling & Simulation: An Introduction To Business Process SimulationDocument24 pagesModeling & Simulation: An Introduction To Business Process SimulationNOSHEEN MEHFOOZNo ratings yet
- Lecture 1Document18 pagesLecture 1wmanjonjoNo ratings yet
- Page ReplaceDocument24 pagesPage Replacekaramjot kaurNo ratings yet
- Parallel Programming PlatformsDocument109 pagesParallel Programming PlatformsKarthik LaxmikanthNo ratings yet
- Uniprocessor Scheduling PDFDocument58 pagesUniprocessor Scheduling PDFmarco.dado2700No ratings yet
- Network Performance Measurement and AnalysisDocument8 pagesNetwork Performance Measurement and AnalysisAdhiyamanPownraj100% (1)
- W01-Basic System Modeling PDFDocument40 pagesW01-Basic System Modeling PDFAlfian NasutionNo ratings yet
- OepDocument13 pagesOepAnonymous R0vXI894TNo ratings yet
- 6 CNNDocument50 pages6 CNNSWAMYA RANJAN DASNo ratings yet
- Introduction To Simulation: Dr. John Mellor-CrummeyDocument30 pagesIntroduction To Simulation: Dr. John Mellor-CrummeyMadalina CalenNo ratings yet
- DSS ModelingDocument13 pagesDSS ModelingS.m. ShadabNo ratings yet
- L-1.1.3 Types OSDocument21 pagesL-1.1.3 Types OSSarthak ThakurNo ratings yet
- Lecture 5: Simulation Technology and Manufacturing System SimulationDocument50 pagesLecture 5: Simulation Technology and Manufacturing System Simulationbilash mehediNo ratings yet
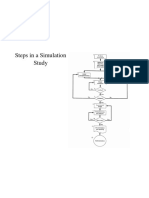
- 4 Steps in A Simulation StudyDocument3 pages4 Steps in A Simulation StudySuresh ThangarajanNo ratings yet
- Workload & WL CharacterizationDocument34 pagesWorkload & WL CharacterizationTayyab RafiqueNo ratings yet
- Scheduling & Data Communication and Networking.: Platform TechnologiesDocument28 pagesScheduling & Data Communication and Networking.: Platform TechnologiesLouie AbbIeNo ratings yet
- Adapt-Policy: Task Assignment in Server Farms When The Service Time Distribution of Tasks Is Not Known A PrioriDocument7 pagesAdapt-Policy: Task Assignment in Server Farms When The Service Time Distribution of Tasks Is Not Known A PrioriShankar ManoNo ratings yet
- Lec 1 Modeling and SimulationDocument29 pagesLec 1 Modeling and SimulationlitrakhanNo ratings yet
- Operating Systems Week4Document30 pagesOperating Systems Week4Yano NettleNo ratings yet
- OS Assignment 2Document3 pagesOS Assignment 2Rizwan SannyNo ratings yet
- Unit Online 1.4Document132 pagesUnit Online 1.4Nitesh SainiNo ratings yet
- Operating Systems: Literature Review On Scheduling Algorithms of Operating SystemDocument12 pagesOperating Systems: Literature Review On Scheduling Algorithms of Operating SystemTeja PeddiNo ratings yet
- L3 Types OSDocument24 pagesL3 Types OSAanchal KashyapNo ratings yet
- Lecture 1Document23 pagesLecture 1Lets clear Jee mathsNo ratings yet
- Nformation Echnology: Engineering & ManufacturingDocument59 pagesNformation Echnology: Engineering & ManufacturingPrashant TripathiNo ratings yet
- Modeling and Performance Evaluation of Network and Computer SystemsDocument34 pagesModeling and Performance Evaluation of Network and Computer Systemsmm_sharma71No ratings yet
- 8 - Input - Output and System ImplementationDocument36 pages8 - Input - Output and System ImplementationakdauatemNo ratings yet
- Lecture 2Document17 pagesLecture 2Lets clear Jee mathsNo ratings yet
- 2016, Q1 - Concurrent Manager Express Lane - 15 Seconds or Less Please - Spring 16Document10 pages2016, Q1 - Concurrent Manager Express Lane - 15 Seconds or Less Please - Spring 16hjtaiebNo ratings yet
- Lec 2Document39 pagesLec 2Mushahid Hussain NomeeNo ratings yet
- Linux Clusters Institute: SchedulingDocument93 pagesLinux Clusters Institute: SchedulingcquintoNo ratings yet
- Parallel ProcessingDocument127 pagesParallel ProcessingrichtomNo ratings yet
- New Challenges in Cloud Datacenter Monitoring and ManagementDocument35 pagesNew Challenges in Cloud Datacenter Monitoring and ManagementIM222No ratings yet
- Requirements: (Selected From Ian Sommerville Slides For "Software Engineering")Document32 pagesRequirements: (Selected From Ian Sommerville Slides For "Software Engineering")Prem UpadhyayNo ratings yet
- Time and Resource Estimation: What Do You Need?Document6 pagesTime and Resource Estimation: What Do You Need?Devjit GhoseNo ratings yet
- ERP ImplementationDocument60 pagesERP ImplementationALI ASGHAR MUSTAFANo ratings yet
- Performance Testing With Jmeter: Yes, But Is It Fast Enough?Document30 pagesPerformance Testing With Jmeter: Yes, But Is It Fast Enough?kirankumar_ks2010No ratings yet
- HWSW Co-Synthesis AlgorithmsDocument38 pagesHWSW Co-Synthesis AlgorithmsAbdur-raheem Ashrafee BeparNo ratings yet
- Os - 5Document15 pagesOs - 5StupefyNo ratings yet
- 0604M Pertemuan1Document61 pages0604M Pertemuan1davidNo ratings yet
- Seminar On-: Real Time Scheduling Policy For Embedded System DomainDocument25 pagesSeminar On-: Real Time Scheduling Policy For Embedded System Domainvinod kapateNo ratings yet
- Recurrent Neural Networks: Anahita Zarei, PH.DDocument37 pagesRecurrent Neural Networks: Anahita Zarei, PH.DNickNo ratings yet
- DBMS Unit-05: By: Mani Butwall, Asst. Prof. (CSE)Document27 pagesDBMS Unit-05: By: Mani Butwall, Asst. Prof. (CSE)Ronak MakwanaNo ratings yet
- Os Unit IiDocument69 pagesOs Unit IiYuvaraj V, Assistant Professor, BCANo ratings yet
- Motivation For Research: Software PerformanceDocument21 pagesMotivation For Research: Software PerformancekshitijrtNo ratings yet
- A Staffing EmergencyDocument4 pagesA Staffing EmergencyAndrés DíazNo ratings yet
- Computer Systems Performance Evaluation and PredictionFrom EverandComputer Systems Performance Evaluation and PredictionRating: 4 out of 5 stars4/5 (1)
- Chapter 09 Litvin PythonDocument24 pagesChapter 09 Litvin PythonOmar AtreidesNo ratings yet
- Automated Restaurant Ordering System BasDocument5 pagesAutomated Restaurant Ordering System BasBikalp KcNo ratings yet
- My Computer: Computers: Vocabulary This Test Comes From - The Site To Learn English (Test N°76352)Document6 pagesMy Computer: Computers: Vocabulary This Test Comes From - The Site To Learn English (Test N°76352)felipegonzalezmarquezNo ratings yet
- How To Install ArduinoDocument129 pagesHow To Install ArduinoKhaizul ZaimNo ratings yet
- Dokumen - Tips - r12 Release NotesDocument49 pagesDokumen - Tips - r12 Release NotesGNo ratings yet
- 74 MLM Team-Building Tips: by Richard DennisDocument13 pages74 MLM Team-Building Tips: by Richard DennisNajib MohamedNo ratings yet
- RW Quick Start Guide WebDocument14 pagesRW Quick Start Guide WebSulianto BhirawaNo ratings yet
- Sesmic Design3Document10 pagesSesmic Design3Swath M MuraliNo ratings yet
- Enterprise Item Number Management - v3.5 - 20210122Document42 pagesEnterprise Item Number Management - v3.5 - 20210122Nikola Bojke BojovicNo ratings yet
- Led DisplayDocument61 pagesLed DisplayJayesh Jain100% (1)
- Updated SMS TemplatesDocument88 pagesUpdated SMS TemplatesShahzaib TanveerNo ratings yet
- Operations Manager - CVDocument3 pagesOperations Manager - CVManazirullah BaigNo ratings yet
- Chapter 2 ERPDocument36 pagesChapter 2 ERPHassan ElbayyaNo ratings yet
- Katana Memory Hint Flash CardDocument92 pagesKatana Memory Hint Flash CardFikha BimaNo ratings yet
- En DMR Hytera-Dispatch-System 201402111Document6 pagesEn DMR Hytera-Dispatch-System 201402111nonlungomalargoNo ratings yet
- Multi-Purpose Slipform Paver: Paving Range: Nom. 6.5 - 24.5 FT (2 - 7.5m) Available With Dowel Bar Inserter (DBI)Document16 pagesMulti-Purpose Slipform Paver: Paving Range: Nom. 6.5 - 24.5 FT (2 - 7.5m) Available With Dowel Bar Inserter (DBI)MudduKrishna shettyNo ratings yet
- Microprocessor MP.Document8 pagesMicroprocessor MP.pritam PawarNo ratings yet
- AN6000 Series Optical Line Terminal Equipment Alarm and Event Reference ADocument327 pagesAN6000 Series Optical Line Terminal Equipment Alarm and Event Reference AEdilson Silva100% (1)
- Software Quality Assurance - 1Document32 pagesSoftware Quality Assurance - 1bilalkhanpatricianNo ratings yet
- SG 246915Document690 pagesSG 246915Antawn OrpillaNo ratings yet
- File: ch01, Chapter 1: Introduction To Systems Analysis and DesignDocument26 pagesFile: ch01, Chapter 1: Introduction To Systems Analysis and DesignJaya MalathyNo ratings yet
- Emtech q1 Module FullDocument72 pagesEmtech q1 Module FullMarlyn GuiangNo ratings yet
- Teaching and Learning Advances On Sensors For IoTDocument124 pagesTeaching and Learning Advances On Sensors For IoTantonioheredia100% (1)
- FortiManager Lab Guide-OnlineDocument182 pagesFortiManager Lab Guide-OnlineFelipe Gabriel Nieto Concha100% (2)
- Sambhavi Amarapalli - ResumeDocument8 pagesSambhavi Amarapalli - Resumesatish_metahorizonNo ratings yet
- Hog ScoopDocument18 pagesHog ScoopAnonymous 2gIWpUcA8RNo ratings yet
- English and Literature - Davao Room Assignments For September 2013 LETDocument75 pagesEnglish and Literature - Davao Room Assignments For September 2013 LETScoopBoyNo ratings yet
- Dialog Controls: - These Controls Are Used To PerformDocument32 pagesDialog Controls: - These Controls Are Used To PerformNadikattu RavikishoreNo ratings yet
- VCS-279.examcollection - Premium.exam.89q HLNTGXN PDFDocument31 pagesVCS-279.examcollection - Premium.exam.89q HLNTGXN PDFkhursheed4u3590No ratings yet
- B. R. Mehta, Y. J. Reddy - Applying FOUNDATION Fieldbus-International Society of Automation (2016) PDFDocument350 pagesB. R. Mehta, Y. J. Reddy - Applying FOUNDATION Fieldbus-International Society of Automation (2016) PDFLeo Le GrisNo ratings yet