You might also like
- Findings: I. Mean, Median and Mode Frequency Tables 1) GenderDocument22 pagesFindings: I. Mean, Median and Mode Frequency Tables 1) GenderNishant ThpNo ratings yet
- BRM-Lecture 4-2023Document48 pagesBRM-Lecture 4-2023sharma.divya0598No ratings yet
- Module 1Document11 pagesModule 1api-327653481No ratings yet
- Chapter - VI: Data Analysis, Interpretations and Hypothesis TestingDocument34 pagesChapter - VI: Data Analysis, Interpretations and Hypothesis Testingritika soodNo ratings yet
- Business Report Assesment 2-1Document13 pagesBusiness Report Assesment 2-1VickytedNo ratings yet
- Differences in age, gender and loyalty towards Adidas productsDocument9 pagesDifferences in age, gender and loyalty towards Adidas productstushar jainNo ratings yet
- AGW 615/3 Advanced Business Statistics: Statistical Analysis ReportDocument10 pagesAGW 615/3 Advanced Business Statistics: Statistical Analysis ReportNida AmriNo ratings yet
- Quoc Dat SAT Score ReportDocument10 pagesQuoc Dat SAT Score ReportManh DoanNo ratings yet
- Effect of Brand Extension On The Sale of LU Bakeri Biscuits - Majid Bashir (4750)Document19 pagesEffect of Brand Extension On The Sale of LU Bakeri Biscuits - Majid Bashir (4750)dijam_786No ratings yet
- Ijrar Issue PDFDocument3 pagesIjrar Issue PDFNishant KoolNo ratings yet
- Skewness, Moments and KurtosisDocument15 pagesSkewness, Moments and KurtosisHasan Raby100% (1)
- Test Week 4 AnswersDocument18 pagesTest Week 4 AnswersPriscilla YaoNo ratings yet
- Answers For Past PapersDocument17 pagesAnswers For Past Papersseyon sithamparanathanNo ratings yet
- Requirements Prioritization Matrix TemplateDocument10 pagesRequirements Prioritization Matrix TemplateKhedidja OuhebNo ratings yet
- Quantitative Methods QuestionDocument2 pagesQuantitative Methods QuestionPriyanka shakyaNo ratings yet
- Statistics Lectures (Part2)Document16 pagesStatistics Lectures (Part2)Juliana IpoNo ratings yet
- Data Preparation and Analysis 3Document182 pagesData Preparation and Analysis 3Karishma AkhtarNo ratings yet
- RepresentativenessDocument4 pagesRepresentativenessHarshvardhini MunwarNo ratings yet
- Clinical Assessment Marking and Interpretation FormDocument2 pagesClinical Assessment Marking and Interpretation FormBob UyNo ratings yet
- Eco 315 Weeks 1-2 - 2024Document97 pagesEco 315 Weeks 1-2 - 2024t728kxtb5tNo ratings yet
- Scatter-Graphs-Demonstration For FlipchartDocument12 pagesScatter-Graphs-Demonstration For FlipchartAnna ElkinNo ratings yet
- DocxDocument6 pagesDocxherrajohn100% (1)
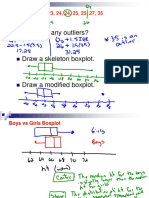
- Boxplots and DistributionsDocument25 pagesBoxplots and DistributionsRenzzyBautistaNo ratings yet
- KruskalWallis TestDocument13 pagesKruskalWallis TestmaricrisNo ratings yet
- Tutorial 6Document2 pagesTutorial 6Robert OoNo ratings yet
- Research Methodology: Presentation BYDocument16 pagesResearch Methodology: Presentation BYBarunNo ratings yet
- Glenn Livingston 8020Document7 pagesGlenn Livingston 8020Rodney Ephraïm NGNo ratings yet
- Quantitative Methods in ManagementDocument131 pagesQuantitative Methods in Managementmanish guptaNo ratings yet
- Women and The Glass CeilingDocument7 pagesWomen and The Glass CeilingGovind RanaNo ratings yet
- Blood Relation - Verbal Reasoning - Competitive Exams Reasoning Tricks PDFDocument7 pagesBlood Relation - Verbal Reasoning - Competitive Exams Reasoning Tricks PDFsumit valsangkarNo ratings yet
- Business Statistics - Hypothesis Testing, Chi Square and AnnovaDocument7 pagesBusiness Statistics - Hypothesis Testing, Chi Square and AnnovaRavindra BabuNo ratings yet
- Developing Critical and Creative Thinking Through ChessDocument7 pagesDeveloping Critical and Creative Thinking Through ChessChess in Schools and Academic ExcellenceNo ratings yet
- A Study On Customer Satisfaction Towards PDFDocument7 pagesA Study On Customer Satisfaction Towards PDFAastha sharmaNo ratings yet
- Assessment 1 Gamified QuizDocument64 pagesAssessment 1 Gamified QuizJackson Abraham ThekkekaraNo ratings yet
- Chi SquareDocument25 pagesChi SquarerolandNo ratings yet
- 570.assignment 2 Frontsheet (Ver.2)Document8 pages570.assignment 2 Frontsheet (Ver.2)Nghia CrisNo ratings yet
- Unit 1Document47 pagesUnit 1Vikas DalalNo ratings yet
- Unit 1Document47 pagesUnit 1Vikas DalalNo ratings yet
- SET-I-Practice Questions - Students - ProblemDocument4 pagesSET-I-Practice Questions - Students - ProblemTushar ChaudharyNo ratings yet
- Chapter 3Document23 pagesChapter 3Alper MertNo ratings yet
- Answers To Exercises and Review Questions: Part Three: Preliminary AnalysesDocument10 pagesAnswers To Exercises and Review Questions: Part Three: Preliminary Analysesjhun bagainNo ratings yet
- Malaysia's e-commerce websites' information and its influence on customers' information privacy concernsDocument10 pagesMalaysia's e-commerce websites' information and its influence on customers' information privacy concernsCik YayaNo ratings yet
- Scorecard 1 303020Document1 pageScorecard 1 303020SHASHANK SINGHNo ratings yet
- Impact of Occupational Stress On Work Life Balance of Bank Employees With Reference To Rayalaseema Region of Andhra PradeshDocument6 pagesImpact of Occupational Stress On Work Life Balance of Bank Employees With Reference To Rayalaseema Region of Andhra PradesharcherselevatorsNo ratings yet
- SFPQ SampleReportDocument11 pagesSFPQ SampleReportPsi MacalandaNo ratings yet
- DS Report Group 3 NNDocument16 pagesDS Report Group 3 NNAmogh Parde (Finance 21-23)No ratings yet
- Study GuideDocument16 pagesStudy GuideKalama KitsaoNo ratings yet
- Kami Export - Jared Duran - Careers Exploration Part 1 1Document17 pagesKami Export - Jared Duran - Careers Exploration Part 1 1api-525646997No ratings yet
- 2 Assignment For Data Analysis For Decision Making: Dipanwita GhoshDocument13 pages2 Assignment For Data Analysis For Decision Making: Dipanwita GhoshDipanwita GhoshNo ratings yet
- Probability Distribution Curve For Net SalesDocument7 pagesProbability Distribution Curve For Net Salessamyak darundeNo ratings yet
- Discriminant AnalysisDocument33 pagesDiscriminant AnalysisLokesh LaddhaNo ratings yet
- Marketing Research Data Analysis TechniquesDocument9 pagesMarketing Research Data Analysis TechniquesLovely DarkNo ratings yet
- Survey reveals investors' attitudesDocument9 pagesSurvey reveals investors' attitudespoojaNo ratings yet
- Scorecard 1 503420Document1 pageScorecard 1 503420tpo.amitpandeyNo ratings yet
- 01 HME 712 Week 1 Assoc Agree Kappa StatisticDocument5 pages01 HME 712 Week 1 Assoc Agree Kappa Statisticjackbane69No ratings yet
- A Study On Investors Perception Towards Mutual FuDocument15 pagesA Study On Investors Perception Towards Mutual Fusmartway projectsNo ratings yet
- Statistics For Everyone Workshop Fall 2010Document47 pagesStatistics For Everyone Workshop Fall 2010SharonCasadorRuñaNo ratings yet
- The Leadership Circle Profile Brochure TLC AUG2015 1 PDFDocument8 pagesThe Leadership Circle Profile Brochure TLC AUG2015 1 PDFCsengeNo ratings yet
- COMM5501 W1 SlidesDocument45 pagesCOMM5501 W1 SlidesASHISH RANJANNo ratings yet
- 1631 - Assignment 2Document36 pages1631 - Assignment 2Bảo HưngNo ratings yet
- VC Accu Gold Brochure QP 12 7 26Document2 pagesVC Accu Gold Brochure QP 12 7 26api-236561915No ratings yet
- Product Development: Don'T Find Customers For Your Products, Find Products For Your Customers"Document27 pagesProduct Development: Don'T Find Customers For Your Products, Find Products For Your Customers"Dharmesh SavitaNo ratings yet
- Economic Impact of Lamu Cultural Festival 2016Document58 pagesEconomic Impact of Lamu Cultural Festival 2016BURAC INSIGHTNo ratings yet
- Statistics 4th Edition Agresti Test BankDocument27 pagesStatistics 4th Edition Agresti Test Banksamuelsalaswfspqdaoyi100% (16)
- EMV of ALTERNATIVES - Final RequirementDocument28 pagesEMV of ALTERNATIVES - Final RequirementClarisse De VeneciaNo ratings yet
- DG Placement Using Loss Sensitivity Factor Method For Loss Reduction and Reliability Improvement in Distribution SystemDocument5 pagesDG Placement Using Loss Sensitivity Factor Method For Loss Reduction and Reliability Improvement in Distribution SystemeihtweNo ratings yet
- (2019) Ahmed Et Al. The Impact of Corporate Social and Environmental Practices On The Cost of Equity Capital - UK EvidenceDocument17 pages(2019) Ahmed Et Al. The Impact of Corporate Social and Environmental Practices On The Cost of Equity Capital - UK EvidenceGabriela De Abreu PassosNo ratings yet
- Minggu 1Document16 pagesMinggu 1JohArNo ratings yet
- Verawati R. Simbolon Catholic University of Saint Thomas EmailDocument13 pagesVerawati R. Simbolon Catholic University of Saint Thomas Emailvera simbolonNo ratings yet
- Module 1 Lesson 2-MetacognitionDocument7 pagesModule 1 Lesson 2-MetacognitionJohn Cedric DullaNo ratings yet
- Brain Tumor Detection Using Machine Learning TechniquesDocument7 pagesBrain Tumor Detection Using Machine Learning TechniquesYashvanthi SanisettyNo ratings yet
- List of Documents / Records To Be Made Available During The VisitDocument2 pagesList of Documents / Records To Be Made Available During The VisitAvinash Shinde100% (1)
- Cultural Evaluation: Superior Good Developing PoorDocument2 pagesCultural Evaluation: Superior Good Developing PoorAnonymous s6pcMzQGpFNo ratings yet
- Clarifying The Research Question Through Secondary Data and ExplorationDocument25 pagesClarifying The Research Question Through Secondary Data and ExplorationAnika VarkeyNo ratings yet
- Impacts of Stress On Employees Job Performance in Hawassa Industrial Park, EthiopiaDocument4 pagesImpacts of Stress On Employees Job Performance in Hawassa Industrial Park, EthiopiaPangeran JoyNo ratings yet
- Lesson 2 q4Document16 pagesLesson 2 q4Luna LedezmaNo ratings yet
- Walking As A Source of Electricity Through The Use of Piezoelectric Plated ShoesDocument5 pagesWalking As A Source of Electricity Through The Use of Piezoelectric Plated ShoesBrave MitraNo ratings yet
- Payyanur Khadi Centre..Document51 pagesPayyanur Khadi Centre..Jithin K Chandran100% (3)
- Cooperative Learning Boosts English ScoresDocument12 pagesCooperative Learning Boosts English ScoresRonald BarriosNo ratings yet
- REINER, Eising. "Studying Interest Groups: Methodological Challenges and Tools". European Political Science, Vol. 16, N. 3, 2017.Document15 pagesREINER, Eising. "Studying Interest Groups: Methodological Challenges and Tools". European Political Science, Vol. 16, N. 3, 2017.Murilo RosaNo ratings yet
- The National Academies Press: Nextgen For Airports, Volume 5: Airport Planning and Development (2017)Document160 pagesThe National Academies Press: Nextgen For Airports, Volume 5: Airport Planning and Development (2017)ERRAMESH1989No ratings yet
- Socio-Economic Environmental Impact Study of The Dadaab Refugee Camp On The Host Community PDFDocument85 pagesSocio-Economic Environmental Impact Study of The Dadaab Refugee Camp On The Host Community PDFShah KhanNo ratings yet
- Yashwanth - Equipment MedicalDocument4 pagesYashwanth - Equipment MedicalValidationNo ratings yet
- GisDocument156 pagesGisanonymous anonymousNo ratings yet
- MEC3416 Semester2 2016Document28 pagesMEC3416 Semester2 2016Aloysi DelouizaNo ratings yet
- The Nature of Inquiry AND ResearchDocument40 pagesThe Nature of Inquiry AND ResearchJelly Joy CampomayorNo ratings yet
- Necessary Evils of Private Tuition: A Case StudyDocument6 pagesNecessary Evils of Private Tuition: A Case StudyInternational Organization of Scientific Research (IOSR)No ratings yet
- Effective Audit Execution GuideDocument16 pagesEffective Audit Execution Guidemirk ardenson ebuizaNo ratings yet
- Lesson 2 - Determining The Progress Towards The Attainment of Learning OutcomesDocument89 pagesLesson 2 - Determining The Progress Towards The Attainment of Learning OutcomesDiana HernandezNo ratings yet