You might also like
- The Calculus Lifesaver: All the Tools You Need to Excel at CalculusFrom EverandThe Calculus Lifesaver: All the Tools You Need to Excel at CalculusRating: 4 out of 5 stars4/5 (6)
- L18 K MeansDocument27 pagesL18 K MeansVeena TellaNo ratings yet
- Data Mining For Business Decision: Prof. (DR.) T. Muthukumar M.SC M.C.A M.B.A M.Phil PH.DDocument73 pagesData Mining For Business Decision: Prof. (DR.) T. Muthukumar M.SC M.C.A M.B.A M.Phil PH.Drisheeta bhattacharyaNo ratings yet
- Machine Learning-Lecture#7-Fall 2020Document18 pagesMachine Learning-Lecture#7-Fall 2020Syed Ali Raza NaqviNo ratings yet
- Spatial Data Mining: Clustering TechniquesDocument56 pagesSpatial Data Mining: Clustering TechniquesbwcastilloNo ratings yet
- CT075!3!2 DTM Topic 10 Cluster AnalysisDocument21 pagesCT075!3!2 DTM Topic 10 Cluster Analysiskishanselvarajah80No ratings yet
- 1-1 Practice - ADocument3 pages1-1 Practice - AStanleyNo ratings yet
- American University of Sharjah: NGN 509 - Computational Methods Professor Nai-Shyong Yeh Assignment #2Document5 pagesAmerican University of Sharjah: NGN 509 - Computational Methods Professor Nai-Shyong Yeh Assignment #2Mohammed AlmoriseyNo ratings yet
- Day-5 IdentifyfractionsdecimalsnumberlineworksheetDocument5 pagesDay-5 IdentifyfractionsdecimalsnumberlineworksheetDra. Nelly Abigail Rodríguez RosalesNo ratings yet
- Chart Slide ShowDocument5 pagesChart Slide ShownnnNo ratings yet
- Introduction - To - Unsupervised - Learning - and - Clustering - MethodsDocument150 pagesIntroduction - To - Unsupervised - Learning - and - Clustering - MethodsEhab EmamNo ratings yet
- Infinite Algebra 2 - HW - Graphing Quadratic Functions in Vertex FormDocument4 pagesInfinite Algebra 2 - HW - Graphing Quadratic Functions in Vertex FormdevikaNo ratings yet
- Project PlanDocument48 pagesProject PlanyehudasimanjuntakNo ratings yet
- UNIT5Document60 pagesUNIT5Sahana ShettyNo ratings yet
- Find Inverse Matrices (40Document1 pageFind Inverse Matrices (40Vaibhav GangwarNo ratings yet
- ClusteringDocument61 pagesClusteringRashul ChutaniNo ratings yet
- CALFEM Mesh Module ManualDocument28 pagesCALFEM Mesh Module ManualJohan Lorentzon100% (1)
- Laporan Poin Asistensi Calysta Skin Clinic Cendana 20220726 20220825Document30 pagesLaporan Poin Asistensi Calysta Skin Clinic Cendana 20220726 20220825Dimas Ricky FirmansyahNo ratings yet
- Chart Slide ShowDocument5 pagesChart Slide ShowAngela MaeNo ratings yet
- Chapter 20 Prob 3Document4 pagesChapter 20 Prob 3CHANDAN KUMARNo ratings yet
- Structured LightDocument10 pagesStructured LightKopkoHNo ratings yet
- Root Locus and Matlab ProgrammingDocument6 pagesRoot Locus and Matlab Programmingshaista00550% (2)
- Fundamentals of Digital Audio Processing: Federico Avanzini and Giovanni de PoliDocument46 pagesFundamentals of Digital Audio Processing: Federico Avanzini and Giovanni de PoliNafi NafiNo ratings yet
- Midterm Exam Specification and Bloom's Taxonomy AnalysisDocument1 pageMidterm Exam Specification and Bloom's Taxonomy Analysismelanie rose barrameda100% (1)
- Around Chord Tones: Concept 6Document3 pagesAround Chord Tones: Concept 6Yiping HuangNo ratings yet
- Around Chord Tones: Concept 6Document3 pagesAround Chord Tones: Concept 6Yiping HuangNo ratings yet
- Lab Session 04Document3 pagesLab Session 04MudassarNo ratings yet
- 09 A PDFDocument3 pages09 A PDFEdgar FloresNo ratings yet
- 2 CNNDocument73 pages2 CNNHan DuNo ratings yet
- DiaphragmDocument16 pagesDiaphragmdbhatia8750% (2)
- Colorful Number Wall Mathematics PosterDocument4 pagesColorful Number Wall Mathematics PosterNURUL SYAHIRAH BINTI MOHD ZOLKIPLI KPM-GuruNo ratings yet
- Algorithms For IRLDocument8 pagesAlgorithms For IRLChaudhary AArishi OrraNo ratings yet
- Komm rt3Document493 pagesKomm rt3Suci musfiraNo ratings yet
- Cec RangosDocument4 pagesCec RangosFernando MaltosNo ratings yet
- Full Download Precalculus Mathematics For Calculus Stewart 6th Edition Test Bank PDF Full ChapterDocument36 pagesFull Download Precalculus Mathematics For Calculus Stewart 6th Edition Test Bank PDF Full Chapteruraninrichweed.be1arg100% (17)
- MRE True WidthDocument7 pagesMRE True WidthJustin ViberNo ratings yet
- Agglomative Clustering CasestudyDocument15 pagesAgglomative Clustering Casestudyクマー ヴィーンNo ratings yet
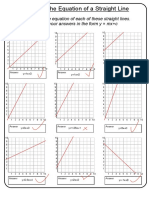
- Finding The Equation of A Straight LineDocument1 pageFinding The Equation of A Straight Linethe tri namNo ratings yet
- MRE WT Ave, Comp, Significant IntDocument7 pagesMRE WT Ave, Comp, Significant IntJustin ViberNo ratings yet
- More ContinuityDocument1 pageMore ContinuityteachopensourceNo ratings yet
- GreenSleeve Tab (Version 1) .XLSBDocument2 pagesGreenSleeve Tab (Version 1) .XLSBcervantexNo ratings yet
- 8 - Clustering ModelDocument44 pages8 - Clustering ModelPutri AnisaNo ratings yet
- Concerto in A Minor RV 356 by Antonio VivaldiDocument6 pagesConcerto in A Minor RV 356 by Antonio Vivaldiumit100% (1)
- Basic GraphDocument8 pagesBasic GraphAditNo ratings yet
- ASTM E18 (2019)_Part31Document1 pageASTM E18 (2019)_Part31david4231993No ratings yet
- AnswersDocument6 pagesAnswerspvqyhzfgy6No ratings yet
- Table of Specification (Automated) v1Document1 pageTable of Specification (Automated) v1Mark Adrian BorjaNo ratings yet
- Test Specification Table and Item AnalysisDocument1 pageTest Specification Table and Item AnalysisAicy G. Dalidig-DisaripNo ratings yet
- Pressure (Bar) Volume (L) Repeat Mean Standard DeviationDocument2 pagesPressure (Bar) Volume (L) Repeat Mean Standard DeviationtuanaNo ratings yet
- Experiment No. 7: Study and Analysis Material Dispersion in Silica FiberDocument2 pagesExperiment No. 7: Study and Analysis Material Dispersion in Silica FiberAltu FaltuNo ratings yet
- Catkul d3 081117Document6 pagesCatkul d3 081117Try Zivilians ZetiaNo ratings yet
- Catkul d3 081117Document6 pagesCatkul d3 081117Try Zivilians ZetiaNo ratings yet
- Pilot Study Reliability ToolDocument5 pagesPilot Study Reliability ToolVaibhav JainNo ratings yet
- Module5 - Outlier - Analysis: Reference: "Data Mining The Text Book", Charu C. Aggarwal, Springer, 2015. (Chapters 8)Document21 pagesModule5 - Outlier - Analysis: Reference: "Data Mining The Text Book", Charu C. Aggarwal, Springer, 2015. (Chapters 8)Rohith RohNo ratings yet
- Mateo FisicaDocument2 pagesMateo FisicaSebastian JaimesNo ratings yet
- Vitesses D'écoulement Plage BlancheDocument1 pageVitesses D'écoulement Plage BlancheZakaria11111No ratings yet
- Libro 1Document11 pagesLibro 1DavidNo ratings yet
- CurvesDocument2 pagesCurvessripaNo ratings yet
- Math 6 Q4 Mod3 ReadingAndInterpretingElectricAndWaterMeterReadings V3Document25 pagesMath 6 Q4 Mod3 ReadingAndInterpretingElectricAndWaterMeterReadings V3fiona leigh homerezNo ratings yet
- Lecture 5 - 8 - Introduction To Feedback Control LoopsDocument28 pagesLecture 5 - 8 - Introduction To Feedback Control LoopsSurendra Louis Dupuis NaikerNo ratings yet
- Topic 6a - Introduction To ClusteringDocument11 pagesTopic 6a - Introduction To ClusteringNurizzati Md NizamNo ratings yet
- Topic 6b - SimilarityDocument23 pagesTopic 6b - SimilarityNurizzati Md NizamNo ratings yet
- Topic 6e - Hierarchical Clustering (MIN)Document14 pagesTopic 6e - Hierarchical Clustering (MIN)Nurizzati Md NizamNo ratings yet
- Topic 6d - Hierarchical AlgorithmDocument38 pagesTopic 6d - Hierarchical AlgorithmNurizzati Md NizamNo ratings yet
- Topic 1a - Introduction To Data MiningDocument12 pagesTopic 1a - Introduction To Data MiningNurizzati Md NizamNo ratings yet
- Topic 1 ISP565Document58 pagesTopic 1 ISP565Nurizzati Md NizamNo ratings yet
- Topic 1 ISP565Document58 pagesTopic 1 ISP565Nurizzati Md NizamNo ratings yet
- Topic 1c - Tasks and Techniques of DMDocument24 pagesTopic 1c - Tasks and Techniques of DMNurizzati Md NizamNo ratings yet
- Topic 1b - History, Evolution and DM ClassificationDocument13 pagesTopic 1b - History, Evolution and DM ClassificationNurizzati Md NizamNo ratings yet
- MSc IT Regulations and Syllabus Periyar UniversityDocument65 pagesMSc IT Regulations and Syllabus Periyar UniversitySrinivasan RamachandranNo ratings yet
- Classifying Iris Data with Neural NetworksDocument21 pagesClassifying Iris Data with Neural NetworksЯу МдNo ratings yet
- Application of Data Mining Techniques To Predicturinary FistDocument140 pagesApplication of Data Mining Techniques To Predicturinary FistshegawNo ratings yet
- Exam VersionDocument413 pagesExam VersionSrikanth MuralidharanNo ratings yet
- Artificial IntelligenceDocument119 pagesArtificial IntelligenceRavishankar BhaganagareNo ratings yet
- Data QualityDocument7 pagesData QualityAaruni GirirajNo ratings yet
- IM Ch14 Big Data Analytics NoSQL Ed12Document8 pagesIM Ch14 Big Data Analytics NoSQL Ed12MohsinNo ratings yet
- Data Mining Notes For BCA 5th Sem 2019 PDFDocument46 pagesData Mining Notes For BCA 5th Sem 2019 PDFAslam NizamiNo ratings yet
- Top 10 Data Mining PapersDocument126 pagesTop 10 Data Mining PapersManjunath.RNo ratings yet
- Knowledge Discovery ProcessDocument24 pagesKnowledge Discovery ProcessSYED ZOHAIB HAIDARNo ratings yet
- Prediction of Poultry Yield Using Data Mining TechniquesDocument17 pagesPrediction of Poultry Yield Using Data Mining TechniquesInternational Journal of Innovation Engineering and Science ResearchNo ratings yet
- Man V Machine: Greyhound Racing Predictions: MSC Research Project Data AnalyticsDocument26 pagesMan V Machine: Greyhound Racing Predictions: MSC Research Project Data Analyticscucu269No ratings yet
- Data Mining Technologies for Cloud Manufacturing Resource ServicesDocument15 pagesData Mining Technologies for Cloud Manufacturing Resource ServicesAvinash KumarNo ratings yet
- DM Question Bank For - 2nd Mid ExamsDocument3 pagesDM Question Bank For - 2nd Mid ExamsGAJULA ANANDPRAVEENKUMARNo ratings yet
- Machine Learning Course Covers Definition, Examples, and AlgorithmsDocument35 pagesMachine Learning Course Covers Definition, Examples, and AlgorithmsAjwad Abrar Mostofa 190042106No ratings yet
- Assignment 1-Preprocessing HandonDocument13 pagesAssignment 1-Preprocessing Handonsuleman045No ratings yet
- Web Mining and Web Usage Mining Techniques: Bulletin de La Société Des Sciences de Liège, Vol. 85, 2016, P. 321 - 328Document8 pagesWeb Mining and Web Usage Mining Techniques: Bulletin de La Société Des Sciences de Liège, Vol. 85, 2016, P. 321 - 328Lalisa DugasaNo ratings yet
- Komparasi Algoritma Neural Network, K-Nearest Neighbor Dan Naive Baiyes Untuk Memprediksi Pendonor Darah Potensial Wahyu Eko Susanto Dwiza RianaDocument10 pagesKomparasi Algoritma Neural Network, K-Nearest Neighbor Dan Naive Baiyes Untuk Memprediksi Pendonor Darah Potensial Wahyu Eko Susanto Dwiza RianaMUHAMMAD FATHURRAHMANNo ratings yet
- P138 A Backtesting ProtocolDocument11 pagesP138 A Backtesting ProtocolRobertoNo ratings yet
- The Using of Analytical Platform For Telecommunication Network Events ForecastingDocument2 pagesThe Using of Analytical Platform For Telecommunication Network Events ForecastingPedrito OrangeNo ratings yet
- Exploring Transfer Learning For Crime PredictionDocument3 pagesExploring Transfer Learning For Crime PredictionSAMEER AHMADNo ratings yet
- DetailedSchedule ICONCT09Document13 pagesDetailedSchedule ICONCT09surendiranNo ratings yet
- Eight Units DWDMDocument119 pagesEight Units DWDMdasarioramaNo ratings yet
- BSSAX Modules 2015Document10 pagesBSSAX Modules 2015Paco PorrasNo ratings yet
- Data Mining: Concepts and Techniques: Cluster AnalysisDocument97 pagesData Mining: Concepts and Techniques: Cluster AnalysissunnynnusNo ratings yet
- Accident Analysis using Data Mining TechniquesDocument80 pagesAccident Analysis using Data Mining TechniquesLeonor Patricia MEDINA SIFUENTESNo ratings yet
- Judyyyy 2Document9 pagesJudyyyy 2rodemae mejoradaNo ratings yet
- A Comparative Study On Financial Stock Market Prediction ModelsDocument4 pagesA Comparative Study On Financial Stock Market Prediction ModelstheijesNo ratings yet
- Advanced Plus Achievement Test 2 (Units 3-4) : ListeningDocument6 pagesAdvanced Plus Achievement Test 2 (Units 3-4) : ListeningFernandoNo ratings yet
- BTech - CSE - 7thsem - Syllabus For WebsiteDocument21 pagesBTech - CSE - 7thsem - Syllabus For WebsiteArindam VermaNo ratings yet