You might also like
- God in Human Form: Sadguru Sri Sri Sri Darga SwamiDocument20 pagesGod in Human Form: Sadguru Sri Sri Sri Darga SwamitvsnNo ratings yet
- Project - 0x00. AirBnB Clone - The Console - ALX Africa IntranetDocument29 pagesProject - 0x00. AirBnB Clone - The Console - ALX Africa IntranetHector Vlad Itok100% (1)
- DataBase SystemsDocument35 pagesDataBase Systemssubhasish_das007No ratings yet
- IT Audit CH 3Document27 pagesIT Audit CH 3Gil Enriquez50% (2)
- Sri Sridhara Swami Sthotra EnglishDocument4 pagesSri Sridhara Swami Sthotra EnglishtvsnNo ratings yet
- Growatt Inverter Modbus RTU Protocol - II V1 - 20-EnglishDocument65 pagesGrowatt Inverter Modbus RTU Protocol - II V1 - 20-EnglishMohamed Abdelmalek100% (1)
- DB2 9 for z/OS Database Administration: Certification Study GuideFrom EverandDB2 9 for z/OS Database Administration: Certification Study GuideNo ratings yet
- Maximizing The Bus S Value of Digital Assets Through API MonetizationDocument15 pagesMaximizing The Bus S Value of Digital Assets Through API MonetizationtvsnNo ratings yet
- Sri Sridhara Swami Stotra - KannadaDocument10 pagesSri Sridhara Swami Stotra - Kannadatvsn100% (3)
- Sri Sridhara Swami Stotra - KannadaDocument10 pagesSri Sridhara Swami Stotra - Kannadatvsn100% (3)
- Garbha Upanishad - TranslationDocument4 pagesGarbha Upanishad - Translationtvsn100% (1)
- Distributed Databases AND Client-Server ArchitechuresDocument73 pagesDistributed Databases AND Client-Server ArchitechuresMichael OdongoNo ratings yet
- 4a. Distributed Databases and Client Server Systems by WELLINGTON MANUEL KUNJENJEMADocument57 pages4a. Distributed Databases and Client Server Systems by WELLINGTON MANUEL KUNJENJEMATinashe KotaNo ratings yet
- DBMS-Unit 5Document27 pagesDBMS-Unit 5ABRNo ratings yet
- Distributed Databases and Client-Server ArchitecturesDocument37 pagesDistributed Databases and Client-Server ArchitectureskdotNo ratings yet
- Distributed Databases and Client-Server ArchitecturesDocument41 pagesDistributed Databases and Client-Server ArchitecturesGenaro07No ratings yet
- Distributed DBMS (Good)Document58 pagesDistributed DBMS (Good)Lakhveer KaurNo ratings yet
- Unit 1 DISTRIBUTED DATABASEDocument6 pagesUnit 1 DISTRIBUTED DATABASEvikas babu gondNo ratings yet
- Lecture 2 Distriburted DatabasesDocument45 pagesLecture 2 Distriburted DatabasesKumkumo Kussia KossaNo ratings yet
- Adt Unitnotes 1to3Document107 pagesAdt Unitnotes 1to3John Solomon GameNo ratings yet
- Adt Unit IDocument18 pagesAdt Unit ISavithri SubramanianNo ratings yet
- Chapter 4 Distributed DatabasesDocument36 pagesChapter 4 Distributed DatabasesMubarek AdemNo ratings yet
- ch6 Distributed DatabaseDocument25 pagesch6 Distributed Databasemelkamu tesfayNo ratings yet
- FinalDocument46 pagesFinalVinod KumarNo ratings yet
- Distributed Databases: Centralized Database System Distributed Database System Advantages and Disadvantages of DDBMSDocument26 pagesDistributed Databases: Centralized Database System Distributed Database System Advantages and Disadvantages of DDBMSPulkit SharmaNo ratings yet
- 8-Distributed DatabaseDocument22 pages8-Distributed DatabaseSabuj DhaliNo ratings yet
- Distributed Database SystemDocument15 pagesDistributed Database Systemwater khanNo ratings yet
- Q # 1: What Are The Components of Distributed Database System? Explain With The Help of A Diagram. AnswerDocument12 pagesQ # 1: What Are The Components of Distributed Database System? Explain With The Help of A Diagram. AnswerAqab ButtNo ratings yet
- DBMS CH-6Document24 pagesDBMS CH-6Endalkachew EmareNo ratings yet
- Distributed Systems - DesignDocument2 pagesDistributed Systems - DesignAman KukarNo ratings yet
- ch6 Distributed DatabaseDocument35 pagesch6 Distributed DatabaseDawit AbNo ratings yet
- Mod 4Document45 pagesMod 4Minu PouloseNo ratings yet
- Advanced Database Management SystemDocument6 pagesAdvanced Database Management SystemTanushree ShenviNo ratings yet
- Distributed Database: Database Storage Devices CPU Database Management System Computers NetworkDocument9 pagesDistributed Database: Database Storage Devices CPU Database Management System Computers NetworkSankari SoniNo ratings yet
- Distributed Database - Unit 5Document4 pagesDistributed Database - Unit 5PreethiVenkateswaranNo ratings yet
- Distributed DatabaseDocument24 pagesDistributed DatabaseHimashree BhuyanNo ratings yet
- Distributed Database Design: BasicsDocument18 pagesDistributed Database Design: BasicsNishant Kumar NarottamNo ratings yet
- Unit-V Distributed and Client Server Databases: A Lalitha Associate Professor Avinash Degree CollegeDocument24 pagesUnit-V Distributed and Client Server Databases: A Lalitha Associate Professor Avinash Degree CollegelalithaNo ratings yet
- 10 DistributeddbmsDocument56 pages10 DistributeddbmsKrishna KumarNo ratings yet
- DDBMS Questions AnswersDocument4 pagesDDBMS Questions AnswersAbdul WaheedNo ratings yet
- Distributed DBDocument16 pagesDistributed DBArchana SaravananNo ratings yet
- CS8492-Database Management Systems-UNIT 5Document20 pagesCS8492-Database Management Systems-UNIT 5Mary James100% (1)
- Module 1Document24 pagesModule 1RAMYA KANAGARAJ AutoNo ratings yet
- Unit 1Document28 pagesUnit 1Kowsalya KandasamyNo ratings yet
- On The Exam We Can Have 1 Cheat Sheet: Blg/Edit?Usp SharingDocument40 pagesOn The Exam We Can Have 1 Cheat Sheet: Blg/Edit?Usp SharingĐorđe KlisuraNo ratings yet
- Advanced Database Techniques-FDocument114 pagesAdvanced Database Techniques-Fsneha555No ratings yet
- Part 2Document8 pagesPart 2Mariane CalospoNo ratings yet
- DDB-distribution Database Important.Document15 pagesDDB-distribution Database Important.Aman PaidlewarNo ratings yet
- New Techniques For Database FragmentationDocument5 pagesNew Techniques For Database FragmentationKidusNo ratings yet
- Answer:: The Different Components of DDBMS Are As FollowsDocument9 pagesAnswer:: The Different Components of DDBMS Are As FollowsAqab ButtNo ratings yet
- Basis For Distributed Database TechnologyDocument35 pagesBasis For Distributed Database TechnologyRavali SrirangamNo ratings yet
- UNIT V RdbmsDocument9 pagesUNIT V RdbmsKatroth PurushothamNo ratings yet
- Distributed Databases: Rohini College of Engineering & TechnologyDocument5 pagesDistributed Databases: Rohini College of Engineering & TechnologymentalinsideNo ratings yet
- Distributed Database Vs Conventional DatabaseDocument4 pagesDistributed Database Vs Conventional Databasecptsankar50% (2)
- Distributed Database Management SystemDocument5 pagesDistributed Database Management SystemGeeti JunejaNo ratings yet
- Distributed Database Management SystemsDocument55 pagesDistributed Database Management Systemsbuyt kuytNo ratings yet
- 4b. Distributed DBDocument52 pages4b. Distributed DBTinashe KotaNo ratings yet
- Distributed DBMS ArchitectureDocument49 pagesDistributed DBMS ArchitectureMahboobNo ratings yet
- Practical No. 1: Aim: Study About Distributed Database System. TheoryDocument22 pagesPractical No. 1: Aim: Study About Distributed Database System. TheoryPrathmesh ChopadeNo ratings yet
- Distributed DatabasesDocument46 pagesDistributed DatabasesSoumya VijoyNo ratings yet
- BIT - University of Colombo - Fundamentals of DB SystemsDocument41 pagesBIT - University of Colombo - Fundamentals of DB SystemsAmaliNo ratings yet
- Distributed DatabasesDocument20 pagesDistributed DatabasesMarefia BirhanuNo ratings yet
- Chapter 7 - Distributed Database SystemDocument27 pagesChapter 7 - Distributed Database Systemajmelcosc0340No ratings yet
- Distributed Database ConceptsDocument35 pagesDistributed Database ConceptsAmalNo ratings yet
- Unit - 2 (1) DBMSDocument25 pagesUnit - 2 (1) DBMSadminNo ratings yet
- Distributed Databases: Presentation-IDocument30 pagesDistributed Databases: Presentation-Irohit_vishwakarma786No ratings yet
- Algorithms To Perform Operations On Two Way Linked ListDocument4 pagesAlgorithms To Perform Operations On Two Way Linked ListtvsnNo ratings yet
- InstallationDocument3 pagesInstallationtvsnNo ratings yet
- Algorithms To Perform Operations On One Way Linked ListDocument4 pagesAlgorithms To Perform Operations On One Way Linked ListtvsnNo ratings yet
- Nizwa College of TechnologyDocument23 pagesNizwa College of TechnologytvsnNo ratings yet
- Algorithms - Array Implementation of Stack PDFDocument1 pageAlgorithms - Array Implementation of Stack PDFtvsnNo ratings yet
- Graphs: by Sonia SoansDocument18 pagesGraphs: by Sonia SoanstvsnNo ratings yet
- Assignment SEM I (2021-22)Document3 pagesAssignment SEM I (2021-22)tvsnNo ratings yet
- Nizwa College of Technology: Academic Year: 2020 / 2021 (Semester 3) Department Timetable DetailsDocument27 pagesNizwa College of Technology: Academic Year: 2020 / 2021 (Semester 3) Department Timetable DetailstvsnNo ratings yet
- Set A: Nizwa College of Technology Department of Information TechnologyDocument7 pagesSet A: Nizwa College of Technology Department of Information TechnologytvsnNo ratings yet
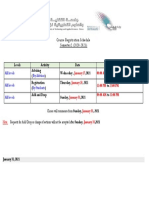
- Registration Schedule - Semester 2 - 2020-2021Document1 pageRegistration Schedule - Semester 2 - 2020-2021tvsnNo ratings yet
- Sankara The Missionary - BiographyDocument137 pagesSankara The Missionary - BiographyChandan Kumar JhaNo ratings yet
- Post Exam Procedure Who? What? Special Mentions ? Finalexammarks. ProtectDocument1 pagePost Exam Procedure Who? What? Special Mentions ? Finalexammarks. ProtecttvsnNo ratings yet
- PART TIME PHD (Cat - B) RegulationsDocument10 pagesPART TIME PHD (Cat - B) RegulationstvsnNo ratings yet
- What Is A Requirement?: Descriptions and Specifications of A SystemDocument17 pagesWhat Is A Requirement?: Descriptions and Specifications of A SystemtvsnNo ratings yet
- ADC in AVR ATmega16Document7 pagesADC in AVR ATmega16Gaurav Shinde100% (1)
- Raspberry Pi Data LoggingDocument5 pagesRaspberry Pi Data LoggingjmdvmNo ratings yet
- CFN Legacy Data 1628092904480Document78 pagesCFN Legacy Data 1628092904480raraNo ratings yet
- Scrum DetailsDocument18 pagesScrum DetailsAmar DeoNo ratings yet
- TK 2 D ManualDocument13 pagesTK 2 D ManualjonasoftmNo ratings yet
- Design Considerations For An LLC Resonant ConverterDocument8 pagesDesign Considerations For An LLC Resonant ConverterNguyễn Duy ThứcNo ratings yet
- DX DiagDocument15 pagesDX DiagJonny GifflyNo ratings yet
- Authorized Distributor Price List: Part # Picture Product Description Precio Lista U.S.$Document11 pagesAuthorized Distributor Price List: Part # Picture Product Description Precio Lista U.S.$Jonathan Valverde RojasNo ratings yet
- SPLA Partner FAQ Cloud Platform Suite GuestDocument5 pagesSPLA Partner FAQ Cloud Platform Suite GuestwalterNo ratings yet
- 4.0 en-US 2023-01 IOM - MultiSmartDocument60 pages4.0 en-US 2023-01 IOM - MultiSmartAbhishek GargNo ratings yet
- Course Recorder U1000Document83 pagesCourse Recorder U1000Bhavin Doshi100% (1)
- HP TruCluster Server V5.1ADocument21 pagesHP TruCluster Server V5.1AAlexandru BotnariNo ratings yet
- ABB Ability Digital Solution: Slide 1Document14 pagesABB Ability Digital Solution: Slide 1Milan LLanque CondeNo ratings yet
- DstatcomDocument18 pagesDstatcomSavreet OttalNo ratings yet
- Microprocessor - WikipediaDocument16 pagesMicroprocessor - WikipediaKarthik KatakamNo ratings yet
- Service Manual: Power AmplifierDocument104 pagesService Manual: Power Amplifierjimmyboy111No ratings yet
- EC203 Solid State Devices PDFDocument2 pagesEC203 Solid State Devices PDFKrishnakumar KattarakunnuNo ratings yet
- Red Hat Enterprise Linux 6 Deployment Guide en USDocument725 pagesRed Hat Enterprise Linux 6 Deployment Guide en USRaju HydNo ratings yet
- Plytka Komunikacyjna Modbus-EnDocument33 pagesPlytka Komunikacyjna Modbus-EnMohammad KazimNo ratings yet
- DX DiagDocument27 pagesDX DiagEdison KodiNo ratings yet
- Java ReportDocument21 pagesJava ReportArmando MaciasNo ratings yet
- Ipc847d Operating Instructions en-USDocument250 pagesIpc847d Operating Instructions en-UShassNo ratings yet
- Logic Gates 1. The Inverter (NOT) : Digital TechniquesDocument10 pagesLogic Gates 1. The Inverter (NOT) : Digital TechniquesLAYTHNo ratings yet
- Sumitomo HF-430 Guìa RápidaDocument31 pagesSumitomo HF-430 Guìa RápidaJohancito Valencia100% (2)
- Eee 1 Le1 UpdDocument2 pagesEee 1 Le1 UpdLester Jason T. ChengNo ratings yet
- 7011a 6-10kva SpecsDocument10 pages7011a 6-10kva SpecsOscar MorenoNo ratings yet
- TALHA NADEEM 11610 CS 5thDocument15 pagesTALHA NADEEM 11610 CS 5thtalhanadeem02No ratings yet