You might also like
- DNSDocument70 pagesDNSSaiVamsiKrrishnaNo ratings yet
- 25 KW X-Band Transceiver DownmastDocument132 pages25 KW X-Band Transceiver DownmastArshad Jummani67% (3)
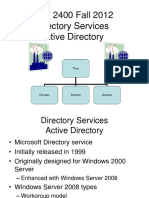
- 01-Introduction To Active DirectoryDocument24 pages01-Introduction To Active DirectoryUwintije Jean PaulNo ratings yet
- RPG TnT: 101 Dynamite Tips 'n Techniques with RPG IVFrom EverandRPG TnT: 101 Dynamite Tips 'n Techniques with RPG IVRating: 5 out of 5 stars5/5 (1)
- RavPower RP WD02 Filehub Windows ManualDocument13 pagesRavPower RP WD02 Filehub Windows ManualJudson BorgesNo ratings yet
- Intelligent Addressable Fire Alarm System: GeneralDocument8 pagesIntelligent Addressable Fire Alarm System: GeneralAmr El-Deeb100% (1)
- Naming, Identifiers and AddressesDocument65 pagesNaming, Identifiers and AddressesRevathi AngamuthuNo ratings yet
- Distributed Systems: NamingDocument36 pagesDistributed Systems: NamingbiploveNo ratings yet
- DNS - How the Domain Name System Works to Resolve Names to IP AddressesDocument19 pagesDNS - How the Domain Name System Works to Resolve Names to IP AddressesyaNo ratings yet
- Distributed System: Naming System in DSDocument51 pagesDistributed System: Naming System in DSፍቅር ለተጠማNo ratings yet
- Components: Naming SystemDocument28 pagesComponents: Naming SystemM.s. NeerajNo ratings yet
- Naming in Distributed SystemsDocument28 pagesNaming in Distributed SystemsHussien MekonnenNo ratings yet
- Chapter09 Name ServiceDocument30 pagesChapter09 Name ServiceaishskyNo ratings yet
- 07 DNSDocument53 pages07 DNSKena DesalegnNo ratings yet
- NamingDocument15 pagesNamingKidane KenenisaNo ratings yet
- Domain Name Server (DNS)Document28 pagesDomain Name Server (DNS)sweatha NNo ratings yet
- Chapter 5-NamingDocument30 pagesChapter 5-NamingMohamedsultan AwolNo ratings yet
- Intro To DS Chapter 3Document38 pagesIntro To DS Chapter 3Habib MuhammedNo ratings yet
- Chapter - 5Document39 pagesChapter - 5AddisuNo ratings yet
- Chapter 4 - Naming: Distributed Systems (IT 441)Document68 pagesChapter 4 - Naming: Distributed Systems (IT 441)hiwot kebedeNo ratings yet
- Chương 8Document62 pagesChương 8đạt thếNo ratings yet
- Samea Yusofi-Name ServiceDocument44 pagesSamea Yusofi-Name Servicesebghat aslamzaiNo ratings yet
- DST - Chapter 2 - Network Enumeration and Foot Printing - 2023 (Compatibility Mode)Document39 pagesDST - Chapter 2 - Network Enumeration and Foot Printing - 2023 (Compatibility Mode)AyushNo ratings yet
- Distributed Systems: Naming ServicesDocument19 pagesDistributed Systems: Naming ServicesArjuna KrishNo ratings yet
- Distributed Systems: Domain Name SystemDocument26 pagesDistributed Systems: Domain Name SystemArjuna KrishNo ratings yet
- NSA - W13L13 Namespaces and NameservicesDocument18 pagesNSA - W13L13 Namespaces and NameservicesHassaan AliNo ratings yet
- DS - Chapter 5 - NamingDocument45 pagesDS - Chapter 5 - Namingbojaa mNo ratings yet
- 21 - Advanced AppLayerDocument14 pages21 - Advanced AppLayerLê Thị Hồng HàNo ratings yet
- 6 NamingDocument23 pages6 NamingSneha GowdaNo ratings yet
- Screenshot 2023-04-08 at 7.03.30 AMDocument23 pagesScreenshot 2023-04-08 at 7.03.30 AMJaabir MacalinyareNo ratings yet
- 677 Lec11Document5 pages677 Lec11alejo alNo ratings yet
- Introduction to Distributed Systems Chapter 5: Naming in Wolkite UniversityDocument51 pagesIntroduction to Distributed Systems Chapter 5: Naming in Wolkite UniversityKidist AsefaNo ratings yet
- JNDI Naming and Directory ServicesDocument10 pagesJNDI Naming and Directory ServicesNishantha Bandara BulumullaNo ratings yet
- Chapter 5 - Naming Systems ExplainedDocument51 pagesChapter 5 - Naming Systems ExplainedyekoyesewNo ratings yet
- ApplicationDocument16 pagesApplicationMuhibbullah MuhibNo ratings yet
- Introduction Distributed Systems - Naming: TodayDocument16 pagesIntroduction Distributed Systems - Naming: Todaykanavonly4uNo ratings yet
- Chapter 3 (B)– Naming and Name ServicesDocument36 pagesChapter 3 (B)– Naming and Name Servicessiraj mohammedNo ratings yet
- Distributed Systems Chapter 5-Naming 1Document57 pagesDistributed Systems Chapter 5-Naming 1Latifa YounisNo ratings yet
- 6CS029 Lecture 10 - Network Directory ServicesDocument35 pages6CS029 Lecture 10 - Network Directory Servicesdushantha.ellewalaNo ratings yet
- Nguyễn Đăng Quang Faculty for High Quality TrainingDocument19 pagesNguyễn Đăng Quang Faculty for High Quality Training21110754No ratings yet
- DNS Domain Name SystemDocument23 pagesDNS Domain Name SystemMuhammad Jawad AbidNo ratings yet
- DNS resolution process explainedDocument55 pagesDNS resolution process explainedDaniel SerkinNo ratings yet
- DNS TranslationDocument22 pagesDNS TranslationZ GooNo ratings yet
- Gathering Target Information Through Reconnaissance, Footprinting and Social EngineeringDocument11 pagesGathering Target Information Through Reconnaissance, Footprinting and Social EngineeringBiff PocorobaNo ratings yet
- 03 NamingDocument56 pages03 NamingThùy DungNo ratings yet
- Screenshot 2023-06-16 at 4.39.36 PMDocument17 pagesScreenshot 2023-06-16 at 4.39.36 PMeeshacheema123No ratings yet
- ENERGY 211 / CME 211: October 6, 2008Document14 pagesENERGY 211 / CME 211: October 6, 2008dantyNo ratings yet
- CH 5Document40 pagesCH 5gemchis dawoNo ratings yet
- Symbol Table and Activation RecordsDocument31 pagesSymbol Table and Activation RecordsVIRENDRA VERMANo ratings yet
- Domain Name SystemDocument16 pagesDomain Name SystempankajNo ratings yet
- 1-Getting Started With ELKDocument44 pages1-Getting Started With ELKMariem El MechryNo ratings yet
- CPSC-662 Naming in Distributed SystemsDocument9 pagesCPSC-662 Naming in Distributed SystemsShivakumar BarupatiNo ratings yet
- Naming EntitiesDocument19 pagesNaming EntitiessivaNo ratings yet
- Dnssec 20122014Document85 pagesDnssec 20122014Muhammad Amal Al-Ghifari0% (1)
- 15-441 Computer NetworkingDocument37 pages15-441 Computer NetworkingShaveta KhepraNo ratings yet
- Name Spaces Documentation NewDocument31 pagesName Spaces Documentation NewRecarroNo ratings yet
- L2 Mechanisms For Web 1Document28 pagesL2 Mechanisms For Web 1chinazasomto02No ratings yet
- 04 Naming PDFDocument53 pages04 Naming PDFMarco CarusoNo ratings yet
- Chapter 10Document25 pagesChapter 10Md Kowsar IslamNo ratings yet
- SCCS 420 CH 25 26 (DNS Telnet Email)Document18 pagesSCCS 420 CH 25 26 (DNS Telnet Email)api-3738694No ratings yet
- Application Layer Protocols Unit 5Document73 pagesApplication Layer Protocols Unit 5Hemasai 6909No ratings yet
- Domain Name System (DNS) : Mrs G Parimala Assistant Professor Department of CSEDocument48 pagesDomain Name System (DNS) : Mrs G Parimala Assistant Professor Department of CSESAI SUHAS KOTARINo ratings yet
- Domain-Driven Laravel: Learn to Implement Domain-Driven Design Using LaravelFrom EverandDomain-Driven Laravel: Learn to Implement Domain-Driven Design Using LaravelNo ratings yet
- APA Referencing 6th Ed Quick GuideDocument2 pagesAPA Referencing 6th Ed Quick GuidehartymNo ratings yet
- Leading Institutional Change & Innovation FlyerDocument6 pagesLeading Institutional Change & Innovation FlyerDr. Atta ur Rehman KhanNo ratings yet
- Adil Shizawi's Thesis on Leadership StylesDocument111 pagesAdil Shizawi's Thesis on Leadership StylesDr. Atta ur Rehman KhanNo ratings yet
- Network Operating Systems and Distributed OS ConceptsDocument43 pagesNetwork Operating Systems and Distributed OS ConceptsDr. Atta ur Rehman KhanNo ratings yet
- Network Operating Systems: INT413 (Fault-Tolerance)Document9 pagesNetwork Operating Systems: INT413 (Fault-Tolerance)Dr. Atta ur Rehman KhanNo ratings yet
- Routing Proposals For Multipath Interdomain RoutingDocument7 pagesRouting Proposals For Multipath Interdomain RoutingDr. Atta ur Rehman KhanNo ratings yet
- Network Operating Systems INT413 Communication: Dr. Atta Ur Rehman Khan A.khan@ajman - Ac.aeDocument39 pagesNetwork Operating Systems INT413 Communication: Dr. Atta Ur Rehman Khan A.khan@ajman - Ac.aeDr. Atta ur Rehman KhanNo ratings yet
- Naming PDFDocument13 pagesNaming PDFPrasanna LakshmiNo ratings yet
- Vehicular Ad Hoc Network (VANET) Localization Techniques A SurveyDocument33 pagesVehicular Ad Hoc Network (VANET) Localization Techniques A SurveyDr. Atta ur Rehman KhanNo ratings yet
- Optimized D-RAN Aware Data Retrieval For 5G Information Centric NetworksDocument23 pagesOptimized D-RAN Aware Data Retrieval For 5G Information Centric NetworksDr. Atta ur Rehman KhanNo ratings yet
- DGRU Based Human Activity Recognition Using Channel State InformationDocument10 pagesDGRU Based Human Activity Recognition Using Channel State InformationDr. Atta ur Rehman KhanNo ratings yet
- Lec-4 UnderstandProblem+DivideWork-1Document33 pagesLec-4 UnderstandProblem+DivideWork-1Dr. Atta ur Rehman KhanNo ratings yet
- Review and Performance Analysis of Position Based Routing in VANETsDocument20 pagesReview and Performance Analysis of Position Based Routing in VANETsDr. Atta ur Rehman KhanNo ratings yet
- A Survey of Mobile Device Virtualization Taxonomy and State of The ArtDocument36 pagesA Survey of Mobile Device Virtualization Taxonomy and State of The ArtDr. Atta ur Rehman KhanNo ratings yet
- Identification of Yeast's Interactome Using Neural NetworksDocument12 pagesIdentification of Yeast's Interactome Using Neural NetworksDr. Atta ur Rehman KhanNo ratings yet
- Diet-Right A Smart Food Recommendation SystemDocument16 pagesDiet-Right A Smart Food Recommendation SystemDr. Atta ur Rehman KhanNo ratings yet
- 3D-RP A DHT-Based Routing Protocol For MANETsDocument22 pages3D-RP A DHT-Based Routing Protocol For MANETsDr. Atta ur Rehman KhanNo ratings yet
- LECTURE 2: The Object Model: Ivan Marsic Rutgers UniversityDocument23 pagesLECTURE 2: The Object Model: Ivan Marsic Rutgers UniversityorionNo ratings yet
- Lec-3 SoftwareConfigMgmtDocument17 pagesLec-3 SoftwareConfigMgmtDr. Atta ur Rehman KhanNo ratings yet
- Lec-5 RequirementsEngDocument43 pagesLec-5 RequirementsEngDr. Atta ur Rehman KhanNo ratings yet
- Lec-1 IntroDocument44 pagesLec-1 IntroDr. Atta ur Rehman KhanNo ratings yet
- Application Note 5336: Gate Drive Optocoupler Basic Design For IGBT / MOSFET Applicable To All Gate Drive OptocouplersDocument4 pagesApplication Note 5336: Gate Drive Optocoupler Basic Design For IGBT / MOSFET Applicable To All Gate Drive OptocouplerselecompinnNo ratings yet
- Divya - Detection of Face Spoofs With Raspberry PiDocument34 pagesDivya - Detection of Face Spoofs With Raspberry PidivyaNo ratings yet
- Work Experience: Birth Date: Birth Place: Age: Civil Status: Nationality: Height: Language SpokenDocument2 pagesWork Experience: Birth Date: Birth Place: Age: Civil Status: Nationality: Height: Language SpokenJohn De LeonNo ratings yet
- ICS 431-Ch3-Process ManagementDocument63 pagesICS 431-Ch3-Process ManagementSalama AlSalamaNo ratings yet
- Operating and Maintenance Instruction Manual for the DAVID-II Model 716 FM-Stereo Processor/GeneratorDocument40 pagesOperating and Maintenance Instruction Manual for the DAVID-II Model 716 FM-Stereo Processor/Generatorclaudio lugonesNo ratings yet
- Q. Find The Output Generated by Following Code FragmentsDocument13 pagesQ. Find The Output Generated by Following Code FragmentsVivekNo ratings yet
- AT Commands PDFDocument68 pagesAT Commands PDFashleshNo ratings yet
- System ProgrammingDocument2 pagesSystem ProgrammingDreamtech Press25% (4)
- RC Dan FLIP FLOP IC 555Document24 pagesRC Dan FLIP FLOP IC 555assaNo ratings yet
- Oracle Identity Manager: Administration and Implementation NEWDocument5 pagesOracle Identity Manager: Administration and Implementation NEWkamuniasNo ratings yet
- Manual Service VaioDocument31 pagesManual Service Vaiomaluxro50% (2)
- Sarvam Ucs v1r5 System ManualDocument2,630 pagesSarvam Ucs v1r5 System ManualUriel Obregon BalbinNo ratings yet
- Connect Motor Controller Pins To Arduino Digital PinsDocument5 pagesConnect Motor Controller Pins To Arduino Digital PinsMuhammadAkbarAsis100% (1)
- UCC28950 Green Phase-Shifted Full-Bridge Controller With Synchronous RectificationDocument76 pagesUCC28950 Green Phase-Shifted Full-Bridge Controller With Synchronous RectificationSaikumarNo ratings yet
- RCS-9611C Instruction Manual en General X R1.02 (En DYBH0301.0086.0013)Document196 pagesRCS-9611C Instruction Manual en General X R1.02 (En DYBH0301.0086.0013)Novandi Wijayanto67% (3)
- Px3xdhmi en 1390Document2 pagesPx3xdhmi en 1390anon_143821310No ratings yet
- Kasturba Institute of Technology: Minor ProjectDocument15 pagesKasturba Institute of Technology: Minor ProjectRiya KumariNo ratings yet
- Circuit Theory Solved Assignments - Semester Fall 2008Document28 pagesCircuit Theory Solved Assignments - Semester Fall 2008Muhammad Umair100% (3)
- Course Slot and Faculty DetailsDocument26 pagesCourse Slot and Faculty DetailsPranjal RuhelaNo ratings yet
- Astrex For AcquirersDocument2 pagesAstrex For Acquirersamul_muthaNo ratings yet
- Testing BookDocument117 pagesTesting BookHumberto KiraNo ratings yet
- Cisco AS5300 Voice Gateway - Technical Data SheetDocument16 pagesCisco AS5300 Voice Gateway - Technical Data SheetsamsulNo ratings yet
- Introduction To Classes and ObjectsDocument78 pagesIntroduction To Classes and ObjectsJohn Oliver JamangNo ratings yet
- Digital Circuits & Fundamentals of Microprocessor: B.E. (Computer Science & Engineering (New) ) Third Semester (C.B.S.)Document2 pagesDigital Circuits & Fundamentals of Microprocessor: B.E. (Computer Science & Engineering (New) ) Third Semester (C.B.S.)A JNo ratings yet
- 1519292487one Indian Girl by Chetan BhagatDocument32 pages1519292487one Indian Girl by Chetan Bhagatabhishek kumarNo ratings yet
- RC Circuits Fundamentals - 2Document6 pagesRC Circuits Fundamentals - 2chipulinoNo ratings yet
- Conference Management System 10Document4 pagesConference Management System 10vidhyasiva8350% (2)