You might also like
- Sumanmondal 14871022056Document5 pagesSumanmondal 14871022056moviesu938No ratings yet
- Unit 2 16 MarksDocument11 pagesUnit 2 16 MarksUma MaheswariNo ratings yet
- Ajith's Artificial Intelligence Assignment Unit2 PDFDocument28 pagesAjith's Artificial Intelligence Assignment Unit2 PDFajithNo ratings yet
- PresDocument24 pagesPresAl-Muneer Sound VehariNo ratings yet
- Uninformed Search AlgorithmsDocument19 pagesUninformed Search AlgorithmsIzwah NazirNo ratings yet
- Lab Report: Department of Mechatronics & Control EngineeringDocument7 pagesLab Report: Department of Mechatronics & Control EngineeringFEALABREPORTSNo ratings yet
- Uninformed Search AlgorithmsDocument16 pagesUninformed Search AlgorithmsMallikarjun YaramadhiNo ratings yet
- Uninformed Search AlgorithmsDocument13 pagesUninformed Search Algorithmsniet sruthimadhavanNo ratings yet
- Ai Unit 2Document40 pagesAi Unit 2riiddhii.8No ratings yet
- Uninformed Search Solution 3.4.2 Uniform-Cost Search: 1 Ms. V. Nisha Jenipher (M.E/Cse)Document23 pagesUninformed Search Solution 3.4.2 Uniform-Cost Search: 1 Ms. V. Nisha Jenipher (M.E/Cse)Sanju ShreeNo ratings yet
- Ai Unit-2 NotesDocument32 pagesAi Unit-2 Notes4119 RAHUL SNo ratings yet
- BWG7JK53 3Document1 pageBWG7JK53 3Matthieu BridiNo ratings yet
- Lecture 3 - Search and Its Strategies - Uninformed SearchDocument52 pagesLecture 3 - Search and Its Strategies - Uninformed SearchjoelanandrajNo ratings yet
- Assignment # 06: Graph Search TechnquesDocument11 pagesAssignment # 06: Graph Search TechnquesAhmad MasoodNo ratings yet
- Module 2Document98 pagesModule 2Bhavana ThummalaNo ratings yet
- BFS DFSDocument10 pagesBFS DFSNANDEESH SANJAYNo ratings yet
- Chapter 3 Search AlgorithmsDocument23 pagesChapter 3 Search Algorithmskhagendra dahalNo ratings yet
- GeorgiaTech CS-6515: Graduate Algorithms: Graph Algorithms Flashcards by Yang Hu - BrainscapeDocument4 pagesGeorgiaTech CS-6515: Graduate Algorithms: Graph Algorithms Flashcards by Yang Hu - BrainscapeJan_SuNo ratings yet
- Uninformed and Informed Search AlgorithmsDocument33 pagesUninformed and Informed Search AlgorithmsDafniNo ratings yet
- Aiml Report757Document8 pagesAiml Report757sumatksumatk5No ratings yet
- Uninformed SearchDocument31 pagesUninformed SearchPrashantNo ratings yet
- Breadth First SearchDocument37 pagesBreadth First SearchAngelina JoyNo ratings yet
- 6 Uninformed SearchDocument13 pages6 Uninformed SearchMuizz AsifNo ratings yet
- Breadth-First Search (BFS) Is An Algorithm ForDocument4 pagesBreadth-First Search (BFS) Is An Algorithm ForOrly DahanNo ratings yet
- Unit 2: 1 A Jeyanthi Asp/Cse MnmjecDocument146 pagesUnit 2: 1 A Jeyanthi Asp/Cse MnmjecJEYANTHI maryNo ratings yet
- Cucs 197 85Document13 pagesCucs 197 85zpa5408No ratings yet
- Year & Sem - II & III Section - A, B, C, D Subject - Data Structures & Algorithms Unit - VDocument178 pagesYear & Sem - II & III Section - A, B, C, D Subject - Data Structures & Algorithms Unit - VKunallNo ratings yet
- 4-Depth Limit Search and Iterative Deepening search-25-Jul-2020Material - I - 25-Jul-2020 - Module - 2 - Problem - SolvingDocument34 pages4-Depth Limit Search and Iterative Deepening search-25-Jul-2020Material - I - 25-Jul-2020 - Module - 2 - Problem - SolvingLatera GonfaNo ratings yet
- CS 611 Slides 2Document28 pagesCS 611 Slides 2Ahmad AbubakarNo ratings yet
- BFS, DFS, Best First SearchDocument15 pagesBFS, DFS, Best First Searchelsa annaNo ratings yet
- Fundamentals IN Artificial Intelligence & Machine Learning CSA2001Document44 pagesFundamentals IN Artificial Intelligence & Machine Learning CSA2001Shreenu SutarNo ratings yet
- A Star AlgoDocument78 pagesA Star Algojiminisinbts02No ratings yet
- L7 L8 - Searching For Solutions - Uninformed Search StrategiesDocument34 pagesL7 L8 - Searching For Solutions - Uninformed Search Strategiesabhinav vuppalaNo ratings yet
- AI NotesDocument10 pagesAI NotesTamilarasi .R 4039No ratings yet
- Chapter 3Document87 pagesChapter 3helNo ratings yet
- I008 - Khemal - Experiment - PAI - 2Document10 pagesI008 - Khemal - Experiment - PAI - 2Khemal DesaiNo ratings yet
- Unit II NotesDocument28 pagesUnit II NotesHatersNo ratings yet
- UnInformed SearchDocument21 pagesUnInformed SearchmonacmicsiaNo ratings yet
- UNIT II Introduction (Extra)Document58 pagesUNIT II Introduction (Extra)thdghj8No ratings yet
- Uniform Cost SearchDocument3 pagesUniform Cost SearchScribdfavNo ratings yet
- Search ProblemsDocument19 pagesSearch ProblemsBala kawshikNo ratings yet
- Search ProblemsDocument19 pagesSearch ProblemsBala kawshikNo ratings yet
- AI Lec2Document43 pagesAI Lec2Asil Zulfiqar 4459-FBAS/BSCS4/F21No ratings yet
- Week 5Document19 pagesWeek 5Khalid SaifNo ratings yet
- Unit1 Class3.2 Uninformed SearchDocument61 pagesUnit1 Class3.2 Uninformed SearchTanush ReddyNo ratings yet
- North Western University, Khulna: Department of Computer Science and EngineeringDocument10 pagesNorth Western University, Khulna: Department of Computer Science and EngineeringShakila JamanNo ratings yet
- Lecture2 AIDocument24 pagesLecture2 AIomar abdulNo ratings yet
- AI 2 NotesDocument36 pagesAI 2 Notesmr8566No ratings yet
- BFS DFS Uniform Cost Search AlgosDocument27 pagesBFS DFS Uniform Cost Search AlgostusharNo ratings yet
- ARTIFICIAL INTELLIGENCE Unit-2Document104 pagesARTIFICIAL INTELLIGENCE Unit-2tushitnigam02No ratings yet
- Depth-First Search (DFS) Is AnDocument2 pagesDepth-First Search (DFS) Is AnAafi QaisarNo ratings yet
- Search Algorithms in AI7Document13 pagesSearch Algorithms in AI7jhn75070No ratings yet
- UntitledDocument15 pagesUntitledBibek SubediNo ratings yet
- Shortest Path AlgorithmDocument2 pagesShortest Path AlgorithmNguyen Phuc NguyenNo ratings yet
- Indira Gandhi Delhi Technical University For Women (Igdtuw) : Mechanical and Automation Engineering (MAE) 2019-2023Document7 pagesIndira Gandhi Delhi Technical University For Women (Igdtuw) : Mechanical and Automation Engineering (MAE) 2019-2023Sheena KhannaNo ratings yet
- Indira Gandhi Delhi Technical University For Women (Igdtuw) : Mechanical and Automation Engineering (MAE) 2019-2023Document8 pagesIndira Gandhi Delhi Technical University For Women (Igdtuw) : Mechanical and Automation Engineering (MAE) 2019-2023Sheena KhannaNo ratings yet
- Lecture 2Document27 pagesLecture 2hefawoj62No ratings yet
- Aies Unit - 2Document28 pagesAies Unit - 2kingslya2004No ratings yet
- Advanced Mathematical Methods in Science and Engineering S. I. Hayek PDFDocument737 pagesAdvanced Mathematical Methods in Science and Engineering S. I. Hayek PDFAndres GonzalezNo ratings yet
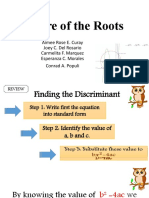
- Nature of The Roots (Day 2)Document9 pagesNature of The Roots (Day 2)Aíméé CúràyNo ratings yet
- Relation and Function Between SetsDocument36 pagesRelation and Function Between SetsRiza Mae BayoNo ratings yet
- MIT18 100BF10 Prac3Document9 pagesMIT18 100BF10 Prac3rohitkyadav0999No ratings yet
- How To Differentiate Different Types of Functions?Document1 pageHow To Differentiate Different Types of Functions?Alishmah JafriNo ratings yet
- 4.91 SYBSC Maths PDFDocument24 pages4.91 SYBSC Maths PDFAzhar Ahmed BashaNo ratings yet
- Learn CBSE: MCQ Questions For Class 10 Maths Polynomials With AnswersDocument18 pagesLearn CBSE: MCQ Questions For Class 10 Maths Polynomials With Answerstindutt life timeNo ratings yet
- Polynomial FunctionsDocument9 pagesPolynomial FunctionsLaurenzhen SorianoNo ratings yet
- Guidelines For The Method of Undetermined CoefficientsDocument6 pagesGuidelines For The Method of Undetermined CoefficientsSandipan SahaNo ratings yet
- Chapter 4 Laplace TransformDocument17 pagesChapter 4 Laplace Transformain sharmilaNo ratings yet
- Programming Assignment 1: Decomposition of Graphs: Algorithms On Graphs ClassDocument10 pagesProgramming Assignment 1: Decomposition of Graphs: Algorithms On Graphs ClassRani SorenNo ratings yet
- Numerical Methods Using ExcelDocument17 pagesNumerical Methods Using ExcelJohn Carlo Agbuya0% (1)
- Numerical Methods PPT AYUSH MISHRADocument11 pagesNumerical Methods PPT AYUSH MISHRAsubscribe.us100No ratings yet
- Q Bernoulli Matrices and Their Some PropertiesDocument6 pagesQ Bernoulli Matrices and Their Some PropertiesLuis perezNo ratings yet
- Graphing Polynomial FunctionsDocument30 pagesGraphing Polynomial FunctionsJean Aristonet Woods LeysonNo ratings yet
- Function SolutionsDocument135 pagesFunction Solutionsshehbazs96No ratings yet
- Chapter 3: Power Series.: 1 Definitions and First PropertiesDocument12 pagesChapter 3: Power Series.: 1 Definitions and First PropertiesAlliver SapitulaNo ratings yet
- Unit V Game Theory (Graphical Method)Document6 pagesUnit V Game Theory (Graphical Method)mohanthakralNo ratings yet
- Tutorial Sheet-10 IIT Kharagpur UG 1st YearDocument3 pagesTutorial Sheet-10 IIT Kharagpur UG 1st YearWilliam EbenezarajNo ratings yet
- L03 LCCDE LaplaceTransform PDFDocument40 pagesL03 LCCDE LaplaceTransform PDFJoseph Angelo BuenafeNo ratings yet
- Local Lipschitz Continuity of Graphs With Prescribed Levi Mean Curvature - Vittorio MARTINODocument14 pagesLocal Lipschitz Continuity of Graphs With Prescribed Levi Mean Curvature - Vittorio MARTINOJefferson Johannes Roth FilhoNo ratings yet
- Laplace Table PDFDocument2 pagesLaplace Table PDFshella168No ratings yet
- On Applications of DerivativesDocument19 pagesOn Applications of DerivativesPradeep Chaudhary50% (2)
- Linear Algebra Report Group 2 CC06Document11 pagesLinear Algebra Report Group 2 CC06long tranNo ratings yet
- Problems For ISI-CMI EntranceDocument4 pagesProblems For ISI-CMI EntranceAnsuman ChakrabortyNo ratings yet
- Advanced Engineering Mathematics 8Th Edition Oneil Solutions Manual Full Chapter PDFDocument36 pagesAdvanced Engineering Mathematics 8Th Edition Oneil Solutions Manual Full Chapter PDFbetty.slaton822100% (14)
- Conclusiones EtaDocument17 pagesConclusiones EtaBart MaxNo ratings yet
- Linear Algebra 2Document25 pagesLinear Algebra 2api-19866009No ratings yet
- Goldmakher, L. Differentiation Under The Integral SignDocument4 pagesGoldmakher, L. Differentiation Under The Integral SignuashdiuahsduiNo ratings yet
- Hölder's Inequality - WikipediaDocument10 pagesHölder's Inequality - WikipediaDuc DoNo ratings yet