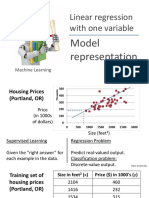
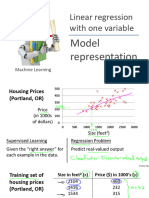
You might also like
- Lecture LinearRegressionDocument42 pagesLecture LinearRegressionRaunak AsnaniNo ratings yet
- Statistics Chapter3Document60 pagesStatistics Chapter3Zhiye Tang100% (1)
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Linear Regression: Study On The Coursera All Right Reserved: Andrew NGDocument29 pagesLinear Regression: Study On The Coursera All Right Reserved: Andrew NGRabbia KhalidNo ratings yet
- Gradient Descent - Linear RegressionDocument47 pagesGradient Descent - Linear RegressionRaushan Kashyap100% (1)
- Lecture 3 AiDocument48 pagesLecture 3 AiEnes sağnakNo ratings yet
- Mathematics Behind Machine Learning:: Linear Regression ModelDocument21 pagesMathematics Behind Machine Learning:: Linear Regression ModelsirineNo ratings yet
- Linear Regression With Multiple VariablesDocument56 pagesLinear Regression With Multiple VariablesAsif Bin LatifNo ratings yet
- L3 Linear Regression and Gradient DescentDocument46 pagesL3 Linear Regression and Gradient Descentjoseph karimNo ratings yet
- Linear RegressionDocument51 pagesLinear RegressionKunal Langer100% (1)
- LinearRegression AnnotatedDocument116 pagesLinearRegression Annotatedmr robotNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model Representationesteban1815No ratings yet
- Linear Regression With One VariableDocument49 pagesLinear Regression With One Variableabdala sabryNo ratings yet
- Lecture 2Document71 pagesLecture 2Bandar AlmaslukhNo ratings yet
- Prs Lab1Document29 pagesPrs Lab1Teodora FurcoviciNo ratings yet
- Linear Regression With Multiple VariablesDocument23 pagesLinear Regression With Multiple VariablesKo Có tênNo ratings yet
- Lecture 2Document62 pagesLecture 2Usama MustafaNo ratings yet
- Machine Learning CourseraDocument55 pagesMachine Learning CourseraLê Văn Tú100% (1)
- Lecture 3-4Document87 pagesLecture 3-4Usama MustafaNo ratings yet
- Multivariate Linear Regression-SharedDocument41 pagesMultivariate Linear Regression-SharedShoppers CartNo ratings yet
- Lecture 3Document32 pagesLecture 3Bandar AlmaslukhNo ratings yet
- Unit 4 - Linear RegressionDocument52 pagesUnit 4 - Linear RegressionshinjoNo ratings yet
- Linear Regression With One VariableDocument49 pagesLinear Regression With One VariableJeffery MaNo ratings yet
- MachineLearning PDFDocument94 pagesMachineLearning PDFKamal BoulefraNo ratings yet
- Linear Regression With Multiple Variables: Reading Material: Part 1 of Lecture Notes 1Document24 pagesLinear Regression With Multiple Variables: Reading Material: Part 1 of Lecture Notes 1M.Talha JavedNo ratings yet
- Prs Lab1 MergedDocument215 pagesPrs Lab1 MergedTeodora FurcoviciNo ratings yet
- Week 04Document101 pagesWeek 04Osii CNo ratings yet
- 3 - Linear Regression Multiple VariablesDocument44 pages3 - Linear Regression Multiple Variableshung13579No ratings yet
- Lecture 5Document31 pagesLecture 5ChatGeePeeTeeNo ratings yet
- 1 ModuleEcontent - Session5Document24 pages1 ModuleEcontent - Session5devesh vermaNo ratings yet
- L3 - Linear Regression - BDocument41 pagesL3 - Linear Regression - BBùi Tấn PhátNo ratings yet
- Linear Regression With Multiple VariablesDocument38 pagesLinear Regression With Multiple VariablesPravinkumarGhodake100% (1)
- AZ AI Lec 08 Machine Learing1Document60 pagesAZ AI Lec 08 Machine Learing1Ahmed MagedNo ratings yet
- ML03Document14 pagesML03Muneeb ButtNo ratings yet
- Accelerated Data Science Introduction To Machine Learning AlgorithmsDocument37 pagesAccelerated Data Science Introduction To Machine Learning AlgorithmssanketjaiswalNo ratings yet
- ML-02-Concept Linear Regression 100822Document53 pagesML-02-Concept Linear Regression 100822Being IITianNo ratings yet
- ML02Document25 pagesML02Muneeb ButtNo ratings yet
- 5 LinearRegression With One-VariableDocument21 pages5 LinearRegression With One-Variableauro auroNo ratings yet
- Deep Learning Nonlinear ControlDocument68 pagesDeep Learning Nonlinear ControlDaotao DaihocNo ratings yet
- 04 Optim ML 2Document66 pages04 Optim ML 2Sourabh AgrawalNo ratings yet
- Estimation (Linear Regression) : Muhamad Fathurahman Data Mining Session 26-27 March 2020Document18 pagesEstimation (Linear Regression) : Muhamad Fathurahman Data Mining Session 26-27 March 2020Ahmad YdNo ratings yet
- Lecture 6,7-Linear RegressionDocument47 pagesLecture 6,7-Linear RegressionWaseem ShahzadNo ratings yet
- Crusher PBM TMDocument4 pagesCrusher PBM TMDirceu NascimentoNo ratings yet
- 1 Definition of Functions - 1S - 22 23Document11 pages1 Definition of Functions - 1S - 22 23Nica Sheena De GuzmanNo ratings yet
- 3.learning The Java LanguageDocument29 pages3.learning The Java LanguageHa Kieu Oanh (K17 HCM)No ratings yet
- 3.3 Bias VarianceDocument14 pages3.3 Bias VarianceDavi Sousa e SilvaNo ratings yet
- Lec 24Document39 pagesLec 24saafinhasan27No ratings yet
- DNN - M2 - Deep Feedforward NN 23decDocument97 pagesDNN - M2 - Deep Feedforward NN 23decManju Prasad NNo ratings yet
- Machine Learning Notes cs229Document217 pagesMachine Learning Notes cs229solomon sudheerNo ratings yet
- Instance Based LearningDocument16 pagesInstance Based LearningSwathi ReddyNo ratings yet
- ML L6 Linear RegresionDocument54 pagesML L6 Linear RegresionMickey MouseNo ratings yet
- Dynamic Programming: Department of CSE JNTUA College of Engg., KalikiriDocument66 pagesDynamic Programming: Department of CSE JNTUA College of Engg., KalikiriMaaz ChauhannNo ratings yet
- Linear Regression With Multiple VariablesDocument20 pagesLinear Regression With Multiple Variablesabdala sabryNo ratings yet
- Week03 - 1 - KNNDocument32 pagesWeek03 - 1 - KNNRawaf FahadNo ratings yet
- Large Scale Deep LearningDocument170 pagesLarge Scale Deep Learningpavancreative81No ratings yet
- Data Mining Classification Algorithms: Credits: Padhraic SmythDocument54 pagesData Mining Classification Algorithms: Credits: Padhraic SmythOm Prakash SharmaNo ratings yet
- Advanced C Concepts and Programming: First EditionFrom EverandAdvanced C Concepts and Programming: First EditionRating: 3 out of 5 stars3/5 (1)
- Data Analytics Using R Seema AcharyaDocument579 pagesData Analytics Using R Seema AcharyaMr. Raghunath ReddyNo ratings yet
- Large2019 Article AProbabilisticClassifierEnsembDocument36 pagesLarge2019 Article AProbabilisticClassifierEnsembMr. Raghunath ReddyNo ratings yet
- Mathematics For Machine LearningDocument417 pagesMathematics For Machine LearningLê Mạnh93% (28)
- Simple Linear Regression: Yandell - Econ 216 Chap 13-1Document70 pagesSimple Linear Regression: Yandell - Econ 216 Chap 13-1Mr. Raghunath ReddyNo ratings yet
- Mahalanobis DistanceDocument8 pagesMahalanobis DistanceMr. Raghunath ReddyNo ratings yet
- 434 M103 PDFDocument8 pages434 M103 PDFMr. Raghunath ReddyNo ratings yet
- KDD96 037Document6 pagesKDD96 037JulioMartinezNo ratings yet
- Javascript TutorialDocument50 pagesJavascript TutorialRobert Rotaru100% (1)
- Cse3521 hw1Document3 pagesCse3521 hw1indrajeet4saravananNo ratings yet
- Anti-Aliasing Analog FiltersDocument12 pagesAnti-Aliasing Analog FiltersDocNo ratings yet
- Energy: Hui Liu, Chengqing Yu, Haiping Wu, Zhu Duan, Guangxi YanDocument18 pagesEnergy: Hui Liu, Chengqing Yu, Haiping Wu, Zhu Duan, Guangxi YanfvijayamiNo ratings yet
- Travelling Salesman Problem Mathematical DescriptionDocument6 pagesTravelling Salesman Problem Mathematical DescriptionMaad M. MijwilNo ratings yet
- Fast Fourier Transform: Diagram 1: View of A Signal in The Time and FrequencyDocument12 pagesFast Fourier Transform: Diagram 1: View of A Signal in The Time and FrequencyJonathan JaegerNo ratings yet
- CNN Image Classification - Image Classification Using CNNDocument9 pagesCNN Image Classification - Image Classification Using CNNchowsaj9No ratings yet
- ML (AutoRecovered)Document4 pagesML (AutoRecovered)IQRA IMRANNo ratings yet
- Bairstow MethodDocument22 pagesBairstow MethodSalagonNo ratings yet
- CBSE Class 10 Maths Worksheet - PolynomialsDocument3 pagesCBSE Class 10 Maths Worksheet - PolynomialsaavyaNo ratings yet
- Solving N Queens Problem Using BacktrackingDocument5 pagesSolving N Queens Problem Using BacktrackingMiriam JohnNo ratings yet
- Image Transforms: DFT-Properties, Walsh, Hadamard, Discrete Cosine, Haar and Slant Transforms The Hotelling TransformDocument25 pagesImage Transforms: DFT-Properties, Walsh, Hadamard, Discrete Cosine, Haar and Slant Transforms The Hotelling TransformramadeviNo ratings yet
- Frequency Domain Least-Squares Reverse Time Migration Using Low-Rank Green'S Function For High Memory EfficiencyDocument5 pagesFrequency Domain Least-Squares Reverse Time Migration Using Low-Rank Green'S Function For High Memory EfficiencyRodrigo SantanaNo ratings yet
- Data Mining-BackpropagationDocument5 pagesData Mining-BackpropagationRaj Endran100% (1)
- (KtabPDF Com) xrwA7TEBGpDocument32 pages(KtabPDF Com) xrwA7TEBGpشجن الزبيرNo ratings yet
- WinZip WinRAR COMPARISON STUDYDocument6 pagesWinZip WinRAR COMPARISON STUDYarun56400% (1)
- What Are The Mean and Median FiltersDocument6 pagesWhat Are The Mean and Median FiltersendaleNo ratings yet
- GENG 300 Numerical Methods: Qatar UniversityDocument2 pagesGENG 300 Numerical Methods: Qatar University0verflowNo ratings yet
- Old Oregon Wood Store Case Analysis: or Group 11: Sravan Barbie Vignesh Rittik Mihira Shruti GotarkarDocument20 pagesOld Oregon Wood Store Case Analysis: or Group 11: Sravan Barbie Vignesh Rittik Mihira Shruti GotarkarBarbie JainNo ratings yet
- AD State Variable Filter DesignDocument3 pagesAD State Variable Filter DesignKinkhKayoNo ratings yet
- LSTMDocument2 pagesLSTMNexgen TechnologyNo ratings yet
- Graphs Shortest PathDocument35 pagesGraphs Shortest PathSangeetha BajanthriNo ratings yet
- Using Excel Solver in Optimization Problems: November 2014Document9 pagesUsing Excel Solver in Optimization Problems: November 2014Chandrabali SahaNo ratings yet
- Simple LPRDocument9 pagesSimple LPRapi-26400509100% (1)
- Machine Learning - Home - Coursera Quiz PDFDocument5 pagesMachine Learning - Home - Coursera Quiz PDFMary Peace100% (1)
- Chapter 10 Digital Transmission Tomasi Review PDFDocument6 pagesChapter 10 Digital Transmission Tomasi Review PDFashwiniNo ratings yet
- Ex - No:8a Date: Channel Equalization Using Lms Algorithm: Adaptive FilterDocument4 pagesEx - No:8a Date: Channel Equalization Using Lms Algorithm: Adaptive FilterbbmathiNo ratings yet
- Hillier and Lieberman Problem 14.4-2 Page 746Document27 pagesHillier and Lieberman Problem 14.4-2 Page 746Potnuru VinayNo ratings yet
- FFT Implementation For FpgaDocument73 pagesFFT Implementation For Fpgaatluri56No ratings yet
- Image Processing Litreature SurveyDocument4 pagesImage Processing Litreature SurveyengineeringwatchNo ratings yet
- PolynomialsDocument11 pagesPolynomialstindutt life timeNo ratings yet