You might also like
- Measuring Data Quality for Ongoing Improvement: A Data Quality Assessment FrameworkFrom EverandMeasuring Data Quality for Ongoing Improvement: A Data Quality Assessment FrameworkRating: 5 out of 5 stars5/5 (4)
- Green Building by Superadobe TechnologyDocument22 pagesGreen Building by Superadobe TechnologySivaramakrishnaNalluri67% (3)
- MinitabDocument26 pagesMinitabgpuonline75% (8)
- Socrates 8dDocument8 pagesSocrates 8dcarolinaNo ratings yet
- Improving Performance With Goals、Feedback、Reward、and Positive ReinforcementDocument15 pagesImproving Performance With Goals、Feedback、Reward、and Positive ReinforcementMichelle HuwaeNo ratings yet
- Data Characteristics and Preprocessing TechniquesDocument9 pagesData Characteristics and Preprocessing Techniquesph2in3856No ratings yet
- DMDW 2nd ModuleDocument29 pagesDMDW 2nd ModuleKavya GowdaNo ratings yet
- Clustering & PCA Assignment QuestionsDocument4 pagesClustering & PCA Assignment QuestionsAmith C GowdaNo ratings yet
- Data ReductionDocument22 pagesData ReductionAdil Bin KhalidNo ratings yet
- Data Warehousing and OLAP OverviewDocument4 pagesData Warehousing and OLAP OverviewRajani NainNo ratings yet
- 3 Business Analysis in Data Mining L6 7 8-9-10Document39 pages3 Business Analysis in Data Mining L6 7 8-9-10MANOJ KUMAWATNo ratings yet
- Dimensionality Reduction (1)Document19 pagesDimensionality Reduction (1)Atul PatilNo ratings yet
- Data Prep Roc EsDocument31 pagesData Prep Roc EsM sindhuNo ratings yet
- DM and DW Notes-Module2Document18 pagesDM and DW Notes-Module2SonuNo ratings yet
- Teradata Warehouse MinerDocument3 pagesTeradata Warehouse MinerKakarla SatyanarayanaNo ratings yet
- Unit - IV - DIMENSIONALITY REDUCTION AND GRAPHICAL MODELSDocument59 pagesUnit - IV - DIMENSIONALITY REDUCTION AND GRAPHICAL MODELSIndumathy ParanthamanNo ratings yet
- Unit - 4 FinalDocument71 pagesUnit - 4 FinalSHREYA M PSGRKCWNo ratings yet
- Data Mining Unit 3Document50 pagesData Mining Unit 3balijagudam shashankNo ratings yet
- Data Mining University AnswerDocument10 pagesData Mining University Answeroozed12No ratings yet
- Data Warehousing and Data MiningDocument7 pagesData Warehousing and Data MiningDeepti SinghNo ratings yet
- Cap6 - Data ReductionDocument27 pagesCap6 - Data Reductionpriyanshidubey2008No ratings yet
- Module 2Document19 pagesModule 2a45 asNo ratings yet
- OLAP and MetadataDocument6 pagesOLAP and MetadataBrian GnorldanNo ratings yet
- Explore Data Cleaning in Business Analytics CourseDocument38 pagesExplore Data Cleaning in Business Analytics CourseJ Warneck GultømNo ratings yet
- PCA & Wavelet Transform Data ReductionDocument41 pagesPCA & Wavelet Transform Data ReductionPrashant SahuNo ratings yet
- DWDMDocument5 pagesDWDMAnkit KumarNo ratings yet
- Data Mining Unit-1 Lect-4Document49 pagesData Mining Unit-1 Lect-4Pooja ReddyNo ratings yet
- Data Warehousing and Mining: An Overview of Data Preprocessing TechniquesDocument18 pagesData Warehousing and Mining: An Overview of Data Preprocessing Techniquesnew acc jeetNo ratings yet
- 3 - Business Analysis in Data Mining - L6 - 7 - 8 - 9 - 10Document40 pages3 - Business Analysis in Data Mining - L6 - 7 - 8 - 9 - 10Deepika GargNo ratings yet
- Contact Me To Get Fully Solved Smu Assignments/Project/Synopsis/Exam Guide PaperDocument7 pagesContact Me To Get Fully Solved Smu Assignments/Project/Synopsis/Exam Guide PaperMrinal KalitaNo ratings yet
- Data CubeDocument42 pagesData CubeGauravBhattNo ratings yet
- DM Mod2 PDFDocument41 pagesDM Mod2 PDFnNo ratings yet
- Unit IvDocument9 pagesUnit Iv112 Pranav KhotNo ratings yet
- Data Manipulation and Visualization in RDocument58 pagesData Manipulation and Visualization in RKundan VanamaNo ratings yet
- DM Mod2Document42 pagesDM Mod2Srushti PSNo ratings yet
- Major Issues in Data MiningDocument9 pagesMajor Issues in Data MiningGaurav JaiswalNo ratings yet
- On-Line Analytical Processing For Business Intelligence Using 3-D ArchitectureDocument3 pagesOn-Line Analytical Processing For Business Intelligence Using 3-D ArchitectureIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNo ratings yet
- 2.data Warehouse and OLAPDocument14 pages2.data Warehouse and OLAPBibek NeupaneNo ratings yet
- MapReduce: A Parallel Processing Model for Big DataDocument29 pagesMapReduce: A Parallel Processing Model for Big DatagenaceNo ratings yet
- Research Citation NotesDocument35 pagesResearch Citation NotesWeb Best WabiiNo ratings yet
- Menu Design, Screen Design, Performance Analysis, and Process Modeling from Data ModelsDocument28 pagesMenu Design, Screen Design, Performance Analysis, and Process Modeling from Data ModelsHaroon ExamNo ratings yet
- Week 9 Data Warehouse ConceptsDocument35 pagesWeek 9 Data Warehouse Conceptssavvy_as_98-1No ratings yet
- Data Reduction TechniquesDocument10 pagesData Reduction TechniquesVinjamuri Joshi ManoharNo ratings yet
- Data Mining Answer KeyDocument10 pagesData Mining Answer KeyRishabh TiwariNo ratings yet
- DWM Assignment (1)Document15 pagesDWM Assignment (1)uspoken91No ratings yet
- Unit2 OlapDocument13 pagesUnit2 OlapAnurag sharmaNo ratings yet
- Major Issues in Data Mining ResearchDocument5 pagesMajor Issues in Data Mining ResearchGaurav JaiswalNo ratings yet
- Down 2Document61 pagesDown 2pavunkumarNo ratings yet
- Scope Descendants Self - and - After This Format - String This END ScopeDocument6 pagesScope Descendants Self - and - After This Format - String This END Scopeprasad_nagireddyNo ratings yet
- Multidimensional Data Modeling ExplainedDocument20 pagesMultidimensional Data Modeling ExplainedRaj pratap singhNo ratings yet
- Shell Fragment Cube Computation MethodDocument6 pagesShell Fragment Cube Computation Methoduniversity of TorontoNo ratings yet
- DWM Mod 1Document17 pagesDWM Mod 1Janvi WaghmodeNo ratings yet
- Aggregate Data ModelsDocument55 pagesAggregate Data ModelschitraalavaniNo ratings yet
- Unit 2 Data AnalyticsDocument16 pagesUnit 2 Data AnalyticsTinku The BloggerNo ratings yet
- Data Preprocessing ConceptsDocument40 pagesData Preprocessing ConceptsMag CreationNo ratings yet
- Bi Unit 2Document14 pagesBi Unit 2Jagdish KapadnisNo ratings yet
- Dimension Reduction Techniques in Machine LearningDocument24 pagesDimension Reduction Techniques in Machine LearningShil ShambharkarNo ratings yet
- Data Warehouse & Mining NotesDocument88 pagesData Warehouse & Mining NotesArvind Pandi DoraiNo ratings yet
- Chapter 2 and 3Document89 pagesChapter 2 and 3Harshad NawghareNo ratings yet
- 2.1 - Multi-Dimensional Data ModelDocument4 pages2.1 - Multi-Dimensional Data ModelSakshi UjjlayanNo ratings yet
- Data WarehouseDocument71 pagesData WarehouseOnkar KumarNo ratings yet
- Assignment 1: Aim: Preprocess Data Using Python. ObjectiveDocument7 pagesAssignment 1: Aim: Preprocess Data Using Python. ObjectiveAbhinay SurveNo ratings yet
- Moving From Business Analyst To Data Analyst To Data Scientist (PDFDrive)Document51 pagesMoving From Business Analyst To Data Analyst To Data Scientist (PDFDrive)شريف ناجي عبد الجيد محمدNo ratings yet
- Ici-Ultratech Build Beautiful Award For Homes: Indian Concrete InstituteDocument6 pagesIci-Ultratech Build Beautiful Award For Homes: Indian Concrete InstituteRavi NairNo ratings yet
- Towards Innovative Community Building: DLSU Holds Henry Sy, Sr. Hall GroundbreakingDocument2 pagesTowards Innovative Community Building: DLSU Holds Henry Sy, Sr. Hall GroundbreakingCarl ChiangNo ratings yet
- ENGGBOQEstimation ReportDocument266 pagesENGGBOQEstimation ReportUTTAL RAYNo ratings yet
- Lesson No. 1 - Pipe Sizing HydraulicsDocument4 pagesLesson No. 1 - Pipe Sizing Hydraulicsusaid saifullahNo ratings yet
- Module 1 Power PlantDocument158 pagesModule 1 Power PlantEzhilarasi NagarjanNo ratings yet
- Lesson 4: Mean and Variance of Discrete Random Variable: Grade 11 - Statistics & ProbabilityDocument26 pagesLesson 4: Mean and Variance of Discrete Random Variable: Grade 11 - Statistics & Probabilitynicole MenesNo ratings yet
- Nasya - Paralellism - New Dengan Tambahan Dari LongmanDocument28 pagesNasya - Paralellism - New Dengan Tambahan Dari LongmannasyaayuNo ratings yet
- ARP 598, D, 2016, Microscopic SizingDocument17 pagesARP 598, D, 2016, Microscopic SizingRasoul gholinia kiviNo ratings yet
- Occupational Health and Safety ProceduresDocument20 pagesOccupational Health and Safety ProceduresPRINCESS VILLANo ratings yet
- Drone Hexacopter IjisrtDocument4 pagesDrone Hexacopter IjisrtDEPARTEMEN RUDALNo ratings yet
- Benevolent Assimilation Proclamation AnalysisDocument4 pagesBenevolent Assimilation Proclamation AnalysishgjfjeuyhdhNo ratings yet
- Os Ass-1 PDFDocument18 pagesOs Ass-1 PDFDinesh R100% (1)
- Catalan NumbersDocument17 pagesCatalan NumbersVishal GuptaNo ratings yet
- The Power ParadoxDocument27 pagesThe Power ParadoxKieran De PaulNo ratings yet
- Autochief® C20: Engine Control and Monitoring For General ElectricDocument2 pagesAutochief® C20: Engine Control and Monitoring For General ElectricВадим ГаранNo ratings yet
- Combination Meter: D1 (A), D2 (B)Document10 pagesCombination Meter: D1 (A), D2 (B)PeterNo ratings yet
- Dcs Ict2113 (Apr22) - LabDocument6 pagesDcs Ict2113 (Apr22) - LabMarwa NajemNo ratings yet
- Eugene A. Nida - Theories of TranslationDocument15 pagesEugene A. Nida - Theories of TranslationYohanes Eko Portable100% (2)
- .Design and Development of Motorized Multipurpose MachineDocument3 pages.Design and Development of Motorized Multipurpose MachineANKITA MORENo ratings yet
- Facts About SaturnDocument7 pagesFacts About SaturnGwyn CervantesNo ratings yet
- ICT - 81 - F32A - ISO - 13485 - and - MDD - IVDD - Checklist - Rev1 - 01.05.2020 - ALAMIN (1) (Recovered)Document41 pagesICT - 81 - F32A - ISO - 13485 - and - MDD - IVDD - Checklist - Rev1 - 01.05.2020 - ALAMIN (1) (Recovered)Basma ashrafNo ratings yet
- Nikon SMZ 10A DatasheetDocument3 pagesNikon SMZ 10A DatasheetNicholai HelNo ratings yet
- Free Fall ExperimentDocument31 pagesFree Fall ExperimentLeerzejPuntoNo ratings yet
- Analyzing Reality vs Fantasy in English LessonsDocument7 pagesAnalyzing Reality vs Fantasy in English Lessonsjerico gaspanNo ratings yet
- Lesson Plan Nº1Document7 pagesLesson Plan Nº1Veronica OrpiNo ratings yet
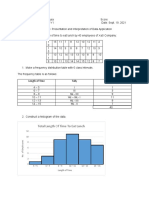
- Cedrix James Estoquia - OLLC Lesson 4.6 Presentation and Interpretation of Data ApplicationDocument4 pagesCedrix James Estoquia - OLLC Lesson 4.6 Presentation and Interpretation of Data ApplicationDeuK WR100% (1)
- 8D Form - LongDocument6 pages8D Form - LongmaofireNo ratings yet