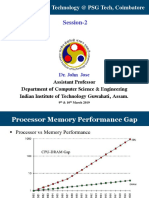
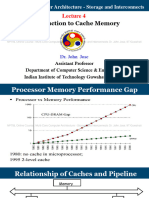
You might also like
- Appendix B SolutionDocument9 pagesAppendix B Solutionebook_sandeep83% (6)
- Adm315 en Col15 Ilt FV ShowDocument239 pagesAdm315 en Col15 Ilt FV ShowSamrat Tiwari100% (2)
- Computer Architecture and Organization: Chapter ThreeDocument42 pagesComputer Architecture and Organization: Chapter ThreeGebrie BeleteNo ratings yet
- Mapping TechniquesDocument4 pagesMapping TechniquesBastin RogersNo ratings yet
- Cache Memory - Mapping FunctionsDocument36 pagesCache Memory - Mapping FunctionsMajety S LskshmiNo ratings yet
- Cache Mapping FunctionsDocument39 pagesCache Mapping FunctionssalithakkNo ratings yet
- Cache MappingDocument44 pagesCache MappingxoeaeoxNo ratings yet
- Memory SystemDocument41 pagesMemory Systemmusfiqurrahman232No ratings yet
- Chap 6Document48 pagesChap 6siddhiNo ratings yet
- Lect11 Cache BasicsDocument22 pagesLect11 Cache BasicsVishal MittalNo ratings yet
- Helping Slides - Cache MappingsDocument30 pagesHelping Slides - Cache MappingsA NNo ratings yet
- Module 6 CO 2020Document40 pagesModule 6 CO 2020jinto0007No ratings yet
- Chapter 03Document57 pagesChapter 03Nguyen Huu Duc ThoNo ratings yet
- Cache - Memory - ConceptDocument73 pagesCache - Memory - ConceptniNo ratings yet
- Large and Fast: Exploiting Memory HierarchyDocument48 pagesLarge and Fast: Exploiting Memory Hierarchyapi-26072581No ratings yet
- 9 - CacheDocument58 pages9 - CacheHARI SANKARNo ratings yet
- Chapter 03Document58 pagesChapter 03Tram NguyenNo ratings yet
- Lectures9 10 Computer Memory 1Document15 pagesLectures9 10 Computer Memory 1Andualem YismawNo ratings yet
- 12 Memory 3Document15 pages12 Memory 3max scalomNo ratings yet
- Memory Mapping Techniques (Zain)Document3 pagesMemory Mapping Techniques (Zain)ZAIN ABBASNo ratings yet
- CO6: Analyze The Levels of Computer Memory and Its Operation (Registers, Main Memory, Cache Memory, Etc.)Document31 pagesCO6: Analyze The Levels of Computer Memory and Its Operation (Registers, Main Memory, Cache Memory, Etc.)hudhaifaNo ratings yet
- Computer Arch 06Document41 pagesComputer Arch 06NaheedNo ratings yet
- 34-Cache Memory Block Identification in Direct Mapping, Associate Mapping and Set Associate-06-03-2Document36 pages34-Cache Memory Block Identification in Direct Mapping, Associate Mapping and Set Associate-06-03-2Rishabh Paul 21BCE2019No ratings yet
- COSS - Contact Session - 4 - With AnnotatonDocument44 pagesCOSS - Contact Session - 4 - With Annotatonnotes.chandanNo ratings yet
- DECO - Module 4.3 - CacheDocument20 pagesDECO - Module 4.3 - Cachesalpoha0102011No ratings yet
- CO Unit 3Document86 pagesCO Unit 3KarthikNo ratings yet
- Caches - Basic IdeaDocument11 pagesCaches - Basic IdeaJustin WilsonNo ratings yet
- CHAPTER 12 - Memory Organization PDFDocument34 pagesCHAPTER 12 - Memory Organization PDFburaNo ratings yet
- Memory Technology & Hierarchy: Caching and Virtual Memory Parallel System ArchitecturesDocument36 pagesMemory Technology & Hierarchy: Caching and Virtual Memory Parallel System Architecturesvamshi krishnaNo ratings yet
- COA U 4 ONE SHOT NOTES 6e9c9f83 6c3a 40ec Afdb 4d22f61f8368 1Document58 pagesCOA U 4 ONE SHOT NOTES 6e9c9f83 6c3a 40ec Afdb 4d22f61f8368 1Haa haNo ratings yet
- Chapter ThreeDocument61 pagesChapter ThreeMawcha HaftuNo ratings yet
- CachesDocument56 pagesCachesAasma KhalidNo ratings yet
- Computer ArchitectureDocument38 pagesComputer ArchitectureFaisal ShehzadNo ratings yet
- 9장 캐시Document65 pages9장 캐시민규No ratings yet
- 5-4 - Chapter 8 - HW 5 - Exercises Logic - and - Computer - Design - Fundamentals - 4th - International - EditionDocument2 pages5-4 - Chapter 8 - HW 5 - Exercises Logic - and - Computer - Design - Fundamentals - 4th - International - EditionDavid SwarcheneggerNo ratings yet
- The Memory Hierarchy (2) - The Cache: 8.1 Some ValuesDocument22 pagesThe Memory Hierarchy (2) - The Cache: 8.1 Some ValuesESSIM DANIEL EGBENo ratings yet
- Nonce and Previous Hash Construction For Bitcoin MiningDocument3 pagesNonce and Previous Hash Construction For Bitcoin MiningAniAceNo ratings yet
- COSS - Contact Session - 4Document34 pagesCOSS - Contact Session - 4Prasana VenkateshNo ratings yet
- 15IF11 Multicore BDocument36 pages15IF11 Multicore BRakesh VenkatesanNo ratings yet
- Tutorial 1Document1 pageTutorial 1Bonnie KwaeNo ratings yet
- Cache Memory: Chapter # 5Document30 pagesCache Memory: Chapter # 5Raheel FareedNo ratings yet
- Cache Memory: Replacement Policy Memory Issues Related To CacheDocument9 pagesCache Memory: Replacement Policy Memory Issues Related To CacheKarthik RoshanNo ratings yet
- Computer Org and Arch: R.MageshDocument48 pagesComputer Org and Arch: R.Mageshmage9999No ratings yet
- Memory Unit Bindu AgarwallaDocument62 pagesMemory Unit Bindu AgarwallaYogansh KesharwaniNo ratings yet
- Module 4: Memory System Organization & ArchitectureDocument97 pagesModule 4: Memory System Organization & ArchitectureSurya SunderNo ratings yet
- Memory PDFDocument16 pagesMemory PDFWity WytiNo ratings yet
- 04 - Cache MemoryDocument47 pages04 - Cache MemoryuabdulgwadNo ratings yet
- Lab 3Document3 pagesLab 3Kiyanoosh RahravanNo ratings yet
- SeminarDocument29 pagesSeminarAjinNo ratings yet
- Unit - 5 Increasing The Memory SizeDocument14 pagesUnit - 5 Increasing The Memory SizeKuldeep SainiNo ratings yet
- Cache and Memory SystemsDocument100 pagesCache and Memory SystemsJay JaberNo ratings yet
- COSS - Lecture - 5 - With AnnotationDocument23 pagesCOSS - Lecture - 5 - With Annotationnotes.chandanNo ratings yet
- CH 06Document58 pagesCH 06Yohannes DerejeNo ratings yet
- Lec 4Document31 pagesLec 4jettychetan524No ratings yet
- My Presentation - 6th Oct. 2011Document18 pagesMy Presentation - 6th Oct. 2011Edinamobong N. OkonNo ratings yet
- Rohini 41399022862Document4 pagesRohini 41399022862shraddhasmethriNo ratings yet
- Chapter 03Document59 pagesChapter 03Tao Chi VyNo ratings yet
- Conspect of Lecture 7Document13 pagesConspect of Lecture 7arukaborbekovaNo ratings yet
- Wk10a Cache PDFDocument25 pagesWk10a Cache PDFV SwaythaNo ratings yet
- William Stallings Computer Organization and Architecture 8th Edition Cache MemoryDocument71 pagesWilliam Stallings Computer Organization and Architecture 8th Edition Cache MemoryBum TumNo ratings yet
- Memory Hierarchy: REG Cache Main SecondaryDocument37 pagesMemory Hierarchy: REG Cache Main SecondaryHimeshParyaniNo ratings yet
- Coding Sites - : Hackerearth or Hackerrank InterviewbitDocument4 pagesCoding Sites - : Hackerearth or Hackerrank InterviewbitAnanya JainNo ratings yet
- Core Java Question Bank (Set-1)Document22 pagesCore Java Question Bank (Set-1)Amitav BiswasNo ratings yet
- Bare Metal CPP v1.0Document177 pagesBare Metal CPP v1.0Kostas KarapidNo ratings yet
- Lab 09 - Doubly Linked ListDocument1 pageLab 09 - Doubly Linked Listadil054No ratings yet
- Umts GSM TrainingDocument57 pagesUmts GSM Trainingazharz4uNo ratings yet
- Javacore 20190309 142011 1548 0002Document249 pagesJavacore 20190309 142011 1548 0002Ευαγγελία ΠαττακούNo ratings yet
- Android Graphics Path - Chis SimmondsDocument44 pagesAndroid Graphics Path - Chis SimmondsSuman Kumar S PNo ratings yet
- Memory ManagementDocument4 pagesMemory Managementrathiramsha7No ratings yet
- Working Set Model & LocalityDocument15 pagesWorking Set Model & LocalitySunimali PereraNo ratings yet
- Memory LogDocument262 pagesMemory LogKevin BernellNo ratings yet
- 20 Tips For Salesforce DevelopersDocument8 pages20 Tips For Salesforce DevelopersajaihlbNo ratings yet
- Example: $ Cat /proc/meminfo: Statistics DetailsDocument3 pagesExample: $ Cat /proc/meminfo: Statistics DetailsETCNo ratings yet
- Total COTS Solutions For Embedded 1553Document12 pagesTotal COTS Solutions For Embedded 1553Vikram ManiNo ratings yet
- 06-Chap04-FileSystems-4slots (86 Slides)Document86 pages06-Chap04-FileSystems-4slots (86 Slides)AN NINH NGUYENNo ratings yet
- Lec 6Document18 pagesLec 6Rama DeviNo ratings yet
- Seb080015 Tut04shes2300Document2 pagesSeb080015 Tut04shes2300Koo Xue YingNo ratings yet
- Unit 3 2015Document25 pagesUnit 3 2015pathakpranavNo ratings yet
- Demand PagingDocument3 pagesDemand PagingBholu DicostaNo ratings yet
- Logical & Physical Address Space - Swapping - Memory Management TechniquesDocument47 pagesLogical & Physical Address Space - Swapping - Memory Management Techniquesmeer aquibNo ratings yet
- CS604 Final Term Solved MCQS With References by AwaisDocument48 pagesCS604 Final Term Solved MCQS With References by AwaisMuhammad Awais100% (2)
- CH 20Document34 pagesCH 20Sakib AhmedNo ratings yet
- Contiguous Memory Allocation (Fixed, Variable Size)Document11 pagesContiguous Memory Allocation (Fixed, Variable Size)Madhurjo MondalNo ratings yet
- TAFJ-AS WebLogicInstallDocument66 pagesTAFJ-AS WebLogicInstallS.M. SayeedNo ratings yet
- Anatomy of A Program in MemoryDocument19 pagesAnatomy of A Program in MemoryVictor J. PerniaNo ratings yet
- History of PythonDocument42 pagesHistory of Pythonsuhaim shibiliNo ratings yet
- Python Interview Questions and AnswersDocument88 pagesPython Interview Questions and AnswersGurupal SachdevaNo ratings yet
- Unit-5: Memory ManagementDocument87 pagesUnit-5: Memory Managementabc defNo ratings yet
- SAP Memory ManagementDocument8 pagesSAP Memory Managementsdk27bNo ratings yet