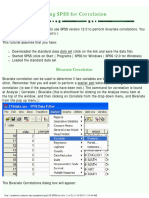
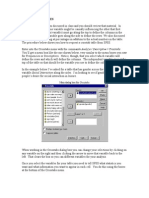
You might also like
- Machine Learning Business ReportDocument60 pagesMachine Learning Business Reportshorya74% (53)
- Principles of ManagementDocument7 pagesPrinciples of ManagementHarshit Rajput100% (1)
- Charter OCAP 4-Device Remote Control: Manufacturer'S CodesDocument2 pagesCharter OCAP 4-Device Remote Control: Manufacturer'S CodesDerek WebsterNo ratings yet
- Chapter 1 Problems Working PapersDocument5 pagesChapter 1 Problems Working PapersZachLovingNo ratings yet
- Free Ebook - The Ultimate Guide To Basic Data Cleaning PDFDocument70 pagesFree Ebook - The Ultimate Guide To Basic Data Cleaning PDFSantiagourquizoNo ratings yet
- Digest of CIR v. Arnoldus Carpentry (G.R. No. 71122)Document2 pagesDigest of CIR v. Arnoldus Carpentry (G.R. No. 71122)Rafael PangilinanNo ratings yet
- Stud Bolt Coating - XYLAN - 10701Document3 pagesStud Bolt Coating - XYLAN - 10701scott100% (2)
- LectureDocument3 pagesLectureSai SmithNo ratings yet
- Excel Stats Nicar2013Document6 pagesExcel Stats Nicar2013yaktamerNo ratings yet
- Correlation: ObjectivesDocument9 pagesCorrelation: ObjectivesJust MahasiswaNo ratings yet
- Statistics NotesDocument46 pagesStatistics Noteshsrinivas_7No ratings yet
- Bivariate Analysis and Chi-Square TestsDocument40 pagesBivariate Analysis and Chi-Square TestsFazalHayatNo ratings yet
- What Is A Correlation Matrix?Document4 pagesWhat Is A Correlation Matrix?Irfan UllahNo ratings yet
- 0 Correlation ADocument5 pages0 Correlation ANazia SyedNo ratings yet
- Histograms and Bar Graphs: Frequency DistrubutionDocument7 pagesHistograms and Bar Graphs: Frequency DistrubutionSimge CicekNo ratings yet
- By Microsoft Website: DURATION: 6 Weeks Amount Paid: Yes: Introduction To Data ScienceDocument21 pagesBy Microsoft Website: DURATION: 6 Weeks Amount Paid: Yes: Introduction To Data ScienceVishal AgrawalNo ratings yet
- Bivariate Correlation in SPSSDocument2 pagesBivariate Correlation in SPSSSana JavaidNo ratings yet
- Data Visualisation Unit 2Document10 pagesData Visualisation Unit 2Anand MohanDassNo ratings yet
- Data Visualisation-Unit-2Document10 pagesData Visualisation-Unit-2Anand MohanDassNo ratings yet
- A Comprehensive Guide To Data ExplorationDocument18 pagesA Comprehensive Guide To Data ExplorationbobbyNo ratings yet
- Crosstab and correlation analysis in SPSSDocument6 pagesCrosstab and correlation analysis in SPSSHimanshu MishraNo ratings yet
- Business Statistics: Qualitative or Categorical DataDocument14 pagesBusiness Statistics: Qualitative or Categorical DataSweety 12No ratings yet
- Statistics Using Excel and SPSS PDFDocument324 pagesStatistics Using Excel and SPSS PDFGerard Benedict Stephen Joseph100% (1)
- The Pattern of Data Is Indicative of The Type of Relationship Between Your Two VariablesDocument4 pagesThe Pattern of Data Is Indicative of The Type of Relationship Between Your Two VariablesJenny PadillaNo ratings yet
- Regression TutorialDocument5 pagesRegression TutorialBálint L'Obasso TóthNo ratings yet
- Basic Commands SPSSDocument25 pagesBasic Commands SPSSAyesha AhmedNo ratings yet
- Data Mining: 1 Task: ClusteringDocument36 pagesData Mining: 1 Task: ClusteringElNo ratings yet
- 07 Scatter DiagramsDocument2 pages07 Scatter DiagramsSteven Bonacorsi100% (4)
- Buku SPSS CompleteDocument72 pagesBuku SPSS Completeb6788No ratings yet
- 1 Correlation BDocument3 pages1 Correlation BNazia SyedNo ratings yet
- Ecotrix With R and PythonDocument25 pagesEcotrix With R and PythonzuhanshaikNo ratings yet
- Torturing Excel Into Doing Statistics: Preparing Your SpreadsheetDocument10 pagesTorturing Excel Into Doing Statistics: Preparing Your SpreadsheetFederico CarusoNo ratings yet
- Unit - 2 BRM PDFDocument9 pagesUnit - 2 BRM PDFmalavika nairNo ratings yet
- Published With Written Permission From SPSS Statistics 11111Document21 pagesPublished With Written Permission From SPSS Statistics 11111arbab buttNo ratings yet
- Correlation and Regression Excel 2003Document6 pagesCorrelation and Regression Excel 2003iqbalNo ratings yet
- machine learning Project ReportDocument65 pagesmachine learning Project ReportAbhishek AbhiNo ratings yet
- A Guide To Data ExplorationDocument20 pagesA Guide To Data Explorationmike110*No ratings yet
- Correspondence Analysis: Ata Cience and NalyticsDocument6 pagesCorrespondence Analysis: Ata Cience and NalyticsSWAPNIL MISHRANo ratings yet
- WWW Social Research Methods Net KB Statdesc PHPDocument87 pagesWWW Social Research Methods Net KB Statdesc PHPNexBengson100% (1)
- Linear Models in Stata and AnovaDocument20 pagesLinear Models in Stata and AnovaarvindpmNo ratings yet
- Create A ScatterplotDocument15 pagesCreate A Scatterplotrithikashivani06No ratings yet
- Data Mining TechnicalDocument45 pagesData Mining TechnicalbhaveshNo ratings yet
- Using Spss For Descriptive Analysis: Description & Correlation - 1Document16 pagesUsing Spss For Descriptive Analysis: Description & Correlation - 1armailgmNo ratings yet
- Analytics Advanced Assignment Mubassir SurveDocument7 pagesAnalytics Advanced Assignment Mubassir SurveMubassir SurveNo ratings yet
- Missing Value TreatmentDocument22 pagesMissing Value TreatmentrphmiNo ratings yet
- Research Statistics DescriptiveDocument100 pagesResearch Statistics Descriptivejouie tabilinNo ratings yet
- Correlation CoefficientDocument11 pagesCorrelation Coefficientdhiyaafr2000No ratings yet
- Module 3Document11 pagesModule 3Sayan MajumderNo ratings yet
- Introduction to basic statistics conceptsDocument11 pagesIntroduction to basic statistics conceptsrssarmaNo ratings yet
- Paired T Tests - PracticalDocument3 pagesPaired T Tests - PracticalMosesNo ratings yet
- Excel Training UnlockedDocument34 pagesExcel Training Unlockedsayantanpaul482No ratings yet
- Measures of Central TendencyDocument48 pagesMeasures of Central TendencySheila Mae Guad100% (1)
- 2/ Organizing and Visualizing Variables: DcovaDocument4 pages2/ Organizing and Visualizing Variables: DcovaThong PhanNo ratings yet
- Predective Analytics or Inferential StatisticsDocument27 pagesPredective Analytics or Inferential StatisticsMichaella PurgananNo ratings yet
- Data Mining ProjectDocument22 pagesData Mining ProjectRanadip GuhaNo ratings yet
- Statistics and Econometrics ICA - R ProjectDocument21 pagesStatistics and Econometrics ICA - R ProjectMeenal ChaturvediNo ratings yet
- MBA0040 Statistics For ManagementDocument11 pagesMBA0040 Statistics For ManagementDhaniram SharmaNo ratings yet
- Data Exploration & VisualizationDocument23 pagesData Exploration & Visualizationdivya kolluriNo ratings yet
- Descriptive StatisticsDocument6 pagesDescriptive StatisticsRuach Dak TangNo ratings yet
- Presentation 1Document55 pagesPresentation 1Zeleke GeresuNo ratings yet
- What Is Measures of Central TendencyDocument4 pagesWhat Is Measures of Central TendencyMEL ABANo ratings yet
- Statistical Analysis For Environmental Systems and SocietiesDocument12 pagesStatistical Analysis For Environmental Systems and SocietiesMichael SmithNo ratings yet
- Chapter 1: Exploring Data: Section 1.1Document16 pagesChapter 1: Exploring Data: Section 1.1jinhyukNo ratings yet
- Excel 2019 Conditional Formatting: Easy Excel Essentials 2019, #3From EverandExcel 2019 Conditional Formatting: Easy Excel Essentials 2019, #3No ratings yet
- ANTDocument19 pagesANTturpu poojithareddyNo ratings yet
- Wa0003.Document8 pagesWa0003.turpu poojithareddyNo ratings yet
- Socialization Assignment1Document13 pagesSocialization Assignment1turpu poojithareddyNo ratings yet
- Self Awareness Worksheet: Who I Am?Document11 pagesSelf Awareness Worksheet: Who I Am?turpu poojithareddyNo ratings yet
- Manonmaniam Sundaranar University: B.Sc. Psychology - I YearDocument72 pagesManonmaniam Sundaranar University: B.Sc. Psychology - I Yearhimansu reddyNo ratings yet
- Development Overview: Physical, Cognitive, Psychosocial ChangesDocument10 pagesDevelopment Overview: Physical, Cognitive, Psychosocial Changesturpu poojithareddyNo ratings yet
- TTD's Role in EducationDocument37 pagesTTD's Role in Educationsri_iasNo ratings yet
- Sustainability at United Parcel ServiceDocument11 pagesSustainability at United Parcel ServiceBabak EbrahimiNo ratings yet
- Isolating Antagonistic BacteriaDocument12 pagesIsolating Antagonistic BacteriaDesy rianitaNo ratings yet
- Ch3.2 - HomeworkDocument2 pagesCh3.2 - HomeworkArcherDash Love GeometrydashNo ratings yet
- Nirma Bhabhi ApplicationDocument3 pagesNirma Bhabhi Applicationsuresh kumarNo ratings yet
- BSI ISOIEC27001 Assessment Checklist UK enDocument3 pagesBSI ISOIEC27001 Assessment Checklist UK enDanushkaPereraNo ratings yet
- 341 Examples of Addressing ModesDocument8 pages341 Examples of Addressing ModesdurvasikiranNo ratings yet
- Rapid AbgDocument11 pagesRapid AbgDeoMikhailAngeloNuñezNo ratings yet
- Alrehman Pirani Resume LMCDocument1 pageAlrehman Pirani Resume LMCapi-307195944No ratings yet
- DTY 4-CH Hard Disc Mobile DVR with GPS, 3G & Wi-FiDocument3 pagesDTY 4-CH Hard Disc Mobile DVR with GPS, 3G & Wi-FiAleksandar NikolovskiNo ratings yet
- Tony'sDocument11 pagesTony'sanna sanaeiNo ratings yet
- Definition of Terms in Practical ResearchDocument4 pagesDefinition of Terms in Practical Researchscarlet chikky endinoNo ratings yet
- Assignment Two: Dennis Wanyoike DIT-035-0022/2009 2/7/2010Document8 pagesAssignment Two: Dennis Wanyoike DIT-035-0022/2009 2/7/2010Dennis WanyoikeNo ratings yet
- What is Bluetooth? The complete guide to the wireless technology standardDocument4 pagesWhat is Bluetooth? The complete guide to the wireless technology standardArpit SrivastavaNo ratings yet
- WCES Second Year Civil Engineering Teaching and Evaluation SchemeDocument13 pagesWCES Second Year Civil Engineering Teaching and Evaluation SchemeawesomeyogeshwarNo ratings yet
- Install Fresh & Hot Air AttenuatorsDocument3 pagesInstall Fresh & Hot Air Attenuatorsmazumdar_satyajitNo ratings yet
- Managerial Accounting Decision Making and Motivating Performance 1st Edition Datar Rajan Test BankDocument46 pagesManagerial Accounting Decision Making and Motivating Performance 1st Edition Datar Rajan Test Bankmable100% (18)
- 06-08 Civic Grid Charger 1 - 1Document4 pages06-08 Civic Grid Charger 1 - 1MilosNo ratings yet
- GAD Project ProposalDocument2 pagesGAD Project ProposalMa. Danessa T. BulingitNo ratings yet
- HRC Couplings: Technical Changes Reserved, Some Items May Not Be Available From Stock. PTI Europa A/S - Pti - EuDocument1 pageHRC Couplings: Technical Changes Reserved, Some Items May Not Be Available From Stock. PTI Europa A/S - Pti - EuVijay BhureNo ratings yet
- 5.1.2.8 Lab - Viewing Network Device MAC AddressesDocument5 pages5.1.2.8 Lab - Viewing Network Device MAC Addresseschristian hallNo ratings yet
- Leadership and Leadership StylesDocument21 pagesLeadership and Leadership StylesJeet Summer83% (6)
- PSY290 Presentation 2Document3 pagesPSY290 Presentation 2kacaribuantonNo ratings yet
- Cytokines: Microenvironment To 10 M)Document6 pagesCytokines: Microenvironment To 10 M)ganeshNo ratings yet
- TDL Reference ManualDocument628 pagesTDL Reference ManualhanifmitNo ratings yet