You might also like
- Practical Engineering, Process, and Reliability StatisticsFrom EverandPractical Engineering, Process, and Reliability StatisticsNo ratings yet
- FOR 2nd Mid EditedDocument36 pagesFOR 2nd Mid EditedSP VetNo ratings yet
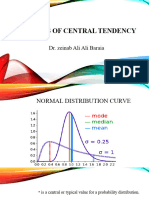
- 11 Economics - Measures of Central Tendency - NotesDocument16 pages11 Economics - Measures of Central Tendency - NotesHimanshu Pandey100% (4)
- Measure of Central Tendency: Measure of Location: GoalsDocument7 pagesMeasure of Central Tendency: Measure of Location: GoalsDebashish MahapatraNo ratings yet
- Study of Averages FinalDocument111 pagesStudy of Averages FinalVishal KumarNo ratings yet
- Unit 3 Summary Statistics 1Document29 pagesUnit 3 Summary Statistics 1Jon BarcenaNo ratings yet
- Unit 8 - Stats and ProbabDocument92 pagesUnit 8 - Stats and ProbabMadhu JethaniNo ratings yet
- Chapter 3-4 Basic Stat MaterialDocument21 pagesChapter 3-4 Basic Stat Materialamanuelfitsum589No ratings yet
- BS Unit 2Document37 pagesBS Unit 2Sneha DavisNo ratings yet
- Measures of Central Tendency: Mean, Mode, Median: Soumendra RoyDocument34 pagesMeasures of Central Tendency: Mean, Mode, Median: Soumendra Roybapparoy100% (1)
- Measures of Central TendencyDocument15 pagesMeasures of Central TendencyAmit Gurav100% (15)
- Central Tendency (Stats)Document89 pagesCentral Tendency (Stats)kutaboys100% (1)
- Central TendencyDocument34 pagesCentral TendencyMd. Anhar Sharif MollahNo ratings yet
- Chapter Three: Measures of Central Tendency (MCT)Document31 pagesChapter Three: Measures of Central Tendency (MCT)Omar KamilNo ratings yet
- Central Tendency Measurement 022-2023Document57 pagesCentral Tendency Measurement 022-2023sajad abasNo ratings yet
- Measures of Central TendencyDocument40 pagesMeasures of Central TendencyAnagha AnuNo ratings yet
- Measures of Central Tendency: Mean, Mode, MedianDocument30 pagesMeasures of Central Tendency: Mean, Mode, Medianafnan nabiNo ratings yet
- Chapter 3Document49 pagesChapter 3sossiNo ratings yet
- Measure of Central TendencyDocument34 pagesMeasure of Central TendencyShailendra Kr YadavNo ratings yet
- Lesson Note 5Document13 pagesLesson Note 5Miftah 67No ratings yet
- Combined MeanDocument14 pagesCombined MeanArun Rana80% (10)
- Measures of Central TendencyDocument40 pagesMeasures of Central TendencyAnagha AnuNo ratings yet
- Chapter4 StatisticsDocument108 pagesChapter4 Statisticsaymane dibNo ratings yet
- Instructor'S Manual: Statistical Techniques in Financial ManagementDocument3 pagesInstructor'S Manual: Statistical Techniques in Financial Managementjoebloggs1888No ratings yet
- 2.4 Descriptive Statistics: Measures of Central TendencyDocument6 pages2.4 Descriptive Statistics: Measures of Central TendencyMd. Abdulla-Al-SabbyNo ratings yet
- Module 1 Additional NotesDocument7 pagesModule 1 Additional NotesWaqas KhanNo ratings yet
- Measures of Central Tendency Mean, Mode, Median: DR. Hetal Koringa Assistant ProfessorDocument26 pagesMeasures of Central Tendency Mean, Mode, Median: DR. Hetal Koringa Assistant ProfessorHetal Koringa patelNo ratings yet
- AK - STATISTIKA - 02 - Describing Data (Cont.)Document47 pagesAK - STATISTIKA - 02 - Describing Data (Cont.)Margareth SilvianaNo ratings yet
- Measures of Central Tendency: Mean, Mode, Median: ChandrappaDocument26 pagesMeasures of Central Tendency: Mean, Mode, Median: ChandrappaMd Mehedi HasanNo ratings yet
- Measure of Central TendencyDocument35 pagesMeasure of Central TendencyPuttu Guru PrasadNo ratings yet
- MMM SD NDDocument41 pagesMMM SD NDEj VillarosaNo ratings yet
- Statistics in ResearchDocument26 pagesStatistics in ResearchStevoh100% (2)
- Handnote On B-Stat.-I-chapter-3Document57 pagesHandnote On B-Stat.-I-chapter-3Kim NamjoonneNo ratings yet
- QMM 3Document67 pagesQMM 3Sandeep VijayakumarNo ratings yet
- 3 Measures of Central Tendency (Mean, Median)Document32 pages3 Measures of Central Tendency (Mean, Median)Mohamed FathyNo ratings yet
- Measures of Central TendencyDocument30 pagesMeasures of Central TendencyYukti SharmaNo ratings yet
- Chapter 3 Descriptive StatisticsDocument78 pagesChapter 3 Descriptive StatisticsG Gጂጂ TubeNo ratings yet
- Mean Median ModeDocument16 pagesMean Median ModeSoumyaBadoniNo ratings yet
- Ugc Net Commerce: Business Statistics & ResearchDocument101 pagesUgc Net Commerce: Business Statistics & ResearchParth TiwariNo ratings yet
- Measures of Central Tendency: Presentation By: Dr. Sampda RajurkarDocument44 pagesMeasures of Central Tendency: Presentation By: Dr. Sampda RajurkarVaishnavi Tiwari100% (1)
- Measure of Central TendencyDocument113 pagesMeasure of Central TendencyRajdeep DasNo ratings yet
- Descriptive Statistics: 由Nordridesign提供Document21 pagesDescriptive Statistics: 由Nordridesign提供مي عديسانNo ratings yet
- Centeral Tendency Part 2Document34 pagesCenteral Tendency Part 2scherrercuteNo ratings yet
- Measures of AveragesDocument32 pagesMeasures of AveragesAarushi SharmaNo ratings yet
- Measures of Central Tendency: Presentation By: DR DharuvDocument44 pagesMeasures of Central Tendency: Presentation By: DR DharuvdharuvNo ratings yet
- CH-3 PPT For Basic Stat (Repaired)Document43 pagesCH-3 PPT For Basic Stat (Repaired)Sani MohammedNo ratings yet
- Measures Of: Central Tendency & DispersionDocument58 pagesMeasures Of: Central Tendency & DispersionAustine Ampofo TwumasiNo ratings yet
- 2.1 Measures of Central TendencyDocument32 pages2.1 Measures of Central Tendencypooja_patnaik237No ratings yet
- Quantitative Techniques in Business: Statistical PartDocument28 pagesQuantitative Techniques in Business: Statistical PartMuhammad ArslanNo ratings yet
- RSU - Statistics - Lecture 3 - Final - myRSUDocument34 pagesRSU - Statistics - Lecture 3 - Final - myRSUirina.mozajevaNo ratings yet
- Measure of Central TendencyDocument7 pagesMeasure of Central TendencyMd.borhan UddinNo ratings yet
- (Measures of Location) - Lec#1 - Chapter 1 - Part1Document33 pages(Measures of Location) - Lec#1 - Chapter 1 - Part1yasmenyasser101No ratings yet
- 5 Measure of Central TendencyDocument54 pages5 Measure of Central Tendencyeshet chafNo ratings yet
- NITKclass 1Document50 pagesNITKclass 1'-MubashirBaigNo ratings yet
- Mean Median ModeDocument56 pagesMean Median ModeJenneth Cabinto DalisanNo ratings yet
- Central TendencyDocument41 pagesCentral TendencyRomit AgarwalNo ratings yet
- Descriptive Statistics ModifiedDocument36 pagesDescriptive Statistics ModifiedMohammad Bony IsrailNo ratings yet
- Quantitative Methods in ManagementDocument70 pagesQuantitative Methods in Managementmanish guptaNo ratings yet
- Measures of Central Tendency PositionDocument12 pagesMeasures of Central Tendency PositionCaren Pelayo JonelasNo ratings yet
- Ugc Net CommerceDocument166 pagesUgc Net CommerceHilal Ahmad100% (3)
- UntitledDocument223 pagesUntitledAzarudheen S StatisticsNo ratings yet
- UntitledDocument498 pagesUntitledAzarudheen S StatisticsNo ratings yet
- Stochastic Ageing and Dependence For RelDocument437 pagesStochastic Ageing and Dependence For RelAzarudheen S StatisticsNo ratings yet
- (27-33) Designing of Skip-LotDocument7 pages(27-33) Designing of Skip-LotAzarudheen S StatisticsNo ratings yet
- Optimal Designing of An SKSP-V Skip-Lot Sampling Plan With Double-Sampling Plan As The Reference PlanDocument8 pagesOptimal Designing of An SKSP-V Skip-Lot Sampling Plan With Double-Sampling Plan As The Reference PlanAzarudheen S StatisticsNo ratings yet
- Long Persistent Luminescence and Blue Photochrımism in Eu Dy Co-Doped Barium Silicate Glass Ceramic PhosphorDocument21 pagesLong Persistent Luminescence and Blue Photochrımism in Eu Dy Co-Doped Barium Silicate Glass Ceramic Phosphorabdi soyluNo ratings yet
- Paratrack 1-26Document4 pagesParatrack 1-26Mahmoud AliNo ratings yet
- Lab Grown MeatDocument17 pagesLab Grown MeatSaya SufiaNo ratings yet
- Lesson Plan Geometry 7esDocument5 pagesLesson Plan Geometry 7esGrizz P100% (3)
- A Motivational View of Learning Performance and Behavior ModificationDocument15 pagesA Motivational View of Learning Performance and Behavior ModificationAndrewsNo ratings yet
- 22 PDFDocument5 pages22 PDFvenkateshNo ratings yet
- Latin Word Study ToolDocument1 pageLatin Word Study Toolmusic cisumNo ratings yet
- Chapter 3Document47 pagesChapter 3yasinNo ratings yet
- Criteria Poor Satisfactory Good Excellent: Report Content (15 Marks)Document4 pagesCriteria Poor Satisfactory Good Excellent: Report Content (15 Marks)Sir KollyNo ratings yet
- Table Differences Between Reggio Montessori SteinerDocument5 pagesTable Differences Between Reggio Montessori SteinerAswiniie100% (1)
- Refugee and Migrant Health: Global Competency Standards For Health WorkersDocument48 pagesRefugee and Migrant Health: Global Competency Standards For Health WorkersAlina ForrayNo ratings yet
- Assignment 1Document17 pagesAssignment 1api-723710078100% (1)
- Biosynthesis of The Neurotoxin Domoic Acid in A Bloom-Forming DiatomDocument4 pagesBiosynthesis of The Neurotoxin Domoic Acid in A Bloom-Forming DiatomHamidun BunawanNo ratings yet
- Cfu On Diversity and Future Directions in Ob Case 1Document3 pagesCfu On Diversity and Future Directions in Ob Case 1Vincent CariñoNo ratings yet
- Standards-Based Cylinders DSBC, To ISO 15552: Look For The Star!Document61 pagesStandards-Based Cylinders DSBC, To ISO 15552: Look For The Star!Shriniwas SharmaNo ratings yet
- DPB10023 Principles of Management Problem Scenario Chapter 6 Staffing Chapter 7 Decision MakingDocument8 pagesDPB10023 Principles of Management Problem Scenario Chapter 6 Staffing Chapter 7 Decision MakingSiti NurSyahirah 1071No ratings yet
- Graphs of A Piecewise Linear FunctionDocument11 pagesGraphs of A Piecewise Linear FunctionRex Lemuel AndesNo ratings yet
- Victorian Age Introduction 2022Document44 pagesVictorian Age Introduction 2022Souss OuNo ratings yet
- Module 4 Learning and DevelopmentDocument10 pagesModule 4 Learning and DevelopmentMelg VieNo ratings yet
- Applications: Mathematics and ArtDocument2 pagesApplications: Mathematics and ArtJohn Kenneth BentirNo ratings yet
- Compressor Sizing and CalculationDocument6 pagesCompressor Sizing and CalculationOghale B. E. Omuabor100% (6)
- EQUATIONSDocument34 pagesEQUATIONSveer pratap mauryaNo ratings yet
- LT05 L2SP 179032 19990818 20200908 02 T1 AngDocument13 pagesLT05 L2SP 179032 19990818 20200908 02 T1 AngAnas Sharafeldin Mohamed OsmanNo ratings yet
- Variable Frecuency Drives (VFDS)Document17 pagesVariable Frecuency Drives (VFDS)Waldir GavelaNo ratings yet
- Research: Newborn CareDocument119 pagesResearch: Newborn CareLouie Anne Cardines Angulo100% (2)
- LMAOOOODocument30 pagesLMAOOOOCarl JohnsonNo ratings yet
- Motion Control Chap17 - SDocument90 pagesMotion Control Chap17 - SPlatin1976No ratings yet
- Reliability Web 5 Sources of Defects SecureDocument1 pageReliability Web 5 Sources of Defects SecureHaitham YoussefNo ratings yet
- Simon - Science Seeks Parsimony, Not SimplicityDocument66 pagesSimon - Science Seeks Parsimony, Not SimplicityAnima Sola100% (1)
- A Comprehensive Ignition System Model For Spark Ignition Engines PDFDocument9 pagesA Comprehensive Ignition System Model For Spark Ignition Engines PDFAmr EmadNo ratings yet