You might also like
- Lecture Notes For Chapter 3 Introduction To Data Mining, 2 EditionDocument59 pagesLecture Notes For Chapter 3 Introduction To Data Mining, 2 EditionYến NghĩaNo ratings yet
- Chap3 Basic ClassificationDocument59 pagesChap3 Basic ClassificationNovitaNo ratings yet
- Data Mining Classification Concepts and TechniquesDocument30 pagesData Mining Classification Concepts and Techniqueshossain2333No ratings yet
- Data Mining Classification TechniquesDocument59 pagesData Mining Classification Techniqueskodchanipha khanthakuarnNo ratings yet
- Data Mining Classification ConceptsDocument58 pagesData Mining Classification ConceptsIshwar MhtNo ratings yet
- Week 10-11Document58 pagesWeek 10-11Humaira BanoNo ratings yet
- Data Mining: Basic Concepts and Techniques of ClassificationDocument58 pagesData Mining: Basic Concepts and Techniques of ClassificationKimondo KingNo ratings yet
- ML-Lecture-9 (Classification and Decision Trees)Document26 pagesML-Lecture-9 (Classification and Decision Trees)Md Fazle RabbyNo ratings yet
- Lecture Notes For Chapter 3: by Tan, Steinbach, Karpatne, KumarDocument58 pagesLecture Notes For Chapter 3: by Tan, Steinbach, Karpatne, KumarSiva ThushanthNo ratings yet
- Lecture Notes For Chapter 3: by Tan, Steinbach, Karpatne, KumarDocument58 pagesLecture Notes For Chapter 3: by Tan, Steinbach, Karpatne, KumarChanda TestNo ratings yet
- Decision Tree and Nearest Neighbor ClassifierDocument80 pagesDecision Tree and Nearest Neighbor ClassifierCharanjit singhNo ratings yet
- basic_classificationDocument58 pagesbasic_classification20B81A1235cvr.ac.in G RUSHI BHARGAVNo ratings yet
- Data Mining Classification ConceptsDocument58 pagesData Mining Classification ConceptsSam Sep A SixtyoneNo ratings yet
- Lecture Notes For Chapter 3 Introduction To Data Mining, 2 EditionDocument58 pagesLecture Notes For Chapter 3 Introduction To Data Mining, 2 EditionsumahalsNo ratings yet
- ch3 1Document58 pagesch3 1楊喻妃No ratings yet
- Lecture Notes For Chapter 4 Introduction To Data Mining: by Tan, Steinbach, KumarDocument35 pagesLecture Notes For Chapter 4 Introduction To Data Mining: by Tan, Steinbach, KumarMihirSanganiNo ratings yet
- Classification Techniques and Decision Tree InductionDocument134 pagesClassification Techniques and Decision Tree InductionrakshithaNo ratings yet
- AIML_UNIT-3Document92 pagesAIML_UNIT-3sunilswapnarathod143No ratings yet
- 13/07/21 Introduction To Data Mining, 2 Edition 1Document58 pages13/07/21 Introduction To Data Mining, 2 Edition 1B.KARTHI KEYANNo ratings yet
- Chap3 Basic ClassificationDocument29 pagesChap3 Basic ClassificationYosua SiregarNo ratings yet
- Chapter - 5 Machine LearningDocument25 pagesChapter - 5 Machine LearningWubliker BNo ratings yet
- 4-Chap4 Basic ClassificationDocument128 pages4-Chap4 Basic ClassificationmasunhomsiNo ratings yet
- Day 1Document33 pagesDay 1Sai SaiNo ratings yet
- Classification: Basic Concepts and Decision TreesDocument71 pagesClassification: Basic Concepts and Decision TreesFrozen_Heart_62No ratings yet
- Lecture Notes For Chapter 4: by Tan, Steinbach, KumarDocument107 pagesLecture Notes For Chapter 4: by Tan, Steinbach, KumarCarlos BurbanoNo ratings yet
- Lecture Notes For Chapter 4 Introduction To Data Mining: by Tan, Steinbach, KumarDocument101 pagesLecture Notes For Chapter 4 Introduction To Data Mining: by Tan, Steinbach, KumarSailesh RaoNo ratings yet
- Chap4 - Basic - Classification-Admin and EconomyDocument31 pagesChap4 - Basic - Classification-Admin and Economyali hussainNo ratings yet
- Hunt's Algorithm: D y (Y, Y, Y, ..., yDocument3 pagesHunt's Algorithm: D y (Y, Y, Y, ..., yRaj Dhakal100% (1)
- Classification Basic Concepts, Decision Trees, and Model EvaluationDocument67 pagesClassification Basic Concepts, Decision Trees, and Model Evaluationsarvesh_mishraNo ratings yet
- Liaquat Majeed Sheikh: National University of Computer and Emerging SciencesDocument79 pagesLiaquat Majeed Sheikh: National University of Computer and Emerging SciencesTalal AhmadNo ratings yet
- Classification 2Document46 pagesClassification 2Pinak DattaNo ratings yet
- Unit 4 Data Mining Algorithms: Dr. Anjan Krishnamurthy Associate Professor Bmsit&MDocument95 pagesUnit 4 Data Mining Algorithms: Dr. Anjan Krishnamurthy Associate Professor Bmsit&MbhattsbNo ratings yet
- Decision TreeDocument43 pagesDecision Treerafliraihan2113No ratings yet
- Tree Based Classifiers: An SEO-Optimized GuideDocument54 pagesTree Based Classifiers: An SEO-Optimized GuidedhruvaNo ratings yet
- Data Mining Course OverviewDocument38 pagesData Mining Course OverviewQomindawoNo ratings yet
- Lec 16,17Document90 pagesLec 16,17ABHIRAJ ENo ratings yet
- Classification: Dr. Yasmin Shaikh International Institute of Professional Studies, Devi Ahilya University, IndoreDocument95 pagesClassification: Dr. Yasmin Shaikh International Institute of Professional Studies, Devi Ahilya University, IndoreKaran AhireNo ratings yet
- Analyzing The Data Data MiningDocument52 pagesAnalyzing The Data Data MiningMahek MallNo ratings yet
- Decision TreesDocument88 pagesDecision TreesAhmed abdallahNo ratings yet
- Data Mining Classification: Naïve Bayes Classifier Lecture Notes For Chapter 4 &5Document26 pagesData Mining Classification: Naïve Bayes Classifier Lecture Notes For Chapter 4 &5HussainNo ratings yet
- Instructor:: Doaa Adil Mohamed AltayebDocument34 pagesInstructor:: Doaa Adil Mohamed AltayebMagnon Be7wakNo ratings yet
- Lecture 14&15Document81 pagesLecture 14&15QUANG ANH B18DCCN034 PHẠMNo ratings yet
- Data Mining Course OverviewDocument38 pagesData Mining Course OverviewIsraa AsNo ratings yet
- Week 4 Part 1 ClassificationDocument71 pagesWeek 4 Part 1 ClassificationMichael ZewdieNo ratings yet
- ML Classification TreeDocument36 pagesML Classification TreeadminNo ratings yet
- Classification: Lecture Notes For Chapters 4 & 5Document42 pagesClassification: Lecture Notes For Chapters 4 & 5Diaa MalahNo ratings yet
- AI-Regression, Classification and RegularizationDocument74 pagesAI-Regression, Classification and RegularizationSafouh AL-HelwaniNo ratings yet
- All Lectures BasicsDocument348 pagesAll Lectures BasicsKarim HassaanNo ratings yet
- 7 - Classfication - Concept - DecisionTree - EvaluationDocument47 pages7 - Classfication - Concept - DecisionTree - EvaluationPutri AnisaNo ratings yet
- Data Mining: Lecture - 03Document56 pagesData Mining: Lecture - 03Ahsan AsimNo ratings yet
- 22mbada303 Module 5Document61 pages22mbada303 Module 5Kiran VinnuNo ratings yet
- Introduction To Data Mining, 2 Edition: by Tan, Steinbach, Karpatne, KumarDocument95 pagesIntroduction To Data Mining, 2 Edition: by Tan, Steinbach, Karpatne, KumarsunilmeNo ratings yet
- INS2061 IntroductionsDocument75 pagesINS2061 IntroductionsBình NguyễnNo ratings yet
- Lecture 2Document98 pagesLecture 2pushpendra singhNo ratings yet
- Important For Data MiningDocument96 pagesImportant For Data MiningmpcNo ratings yet
- CH03 Classification Part IDocument58 pagesCH03 Classification Part IozgeNo ratings yet
- Foundations of Data Science - Unit 3Document18 pagesFoundations of Data Science - Unit 3song neeNo ratings yet
- Lecture 6 - Decision TreesDocument43 pagesLecture 6 - Decision TreesWaseem SajjadNo ratings yet
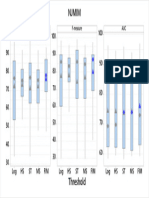
- NJMIMDocument1 pageNJMIMCSSCTube FCITubeNo ratings yet
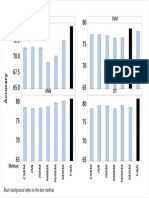
- FJMI Acc 1Document1 pageFJMI Acc 1CSSCTube FCITubeNo ratings yet
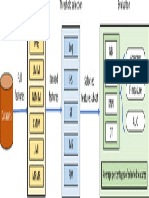
- FrameworkDocument1 pageFrameworkCSSCTube FCITubeNo ratings yet
- Bayesian Classifiers Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarDocument17 pagesBayesian Classifiers Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarCSSCTube FCITubeNo ratings yet
- 01 IntroDocument37 pages01 IntroJyothi JyoNo ratings yet
- K Nearest NeighborsDocument19 pagesK Nearest NeighborsCSSCTube FCITubeNo ratings yet
- Classification Basedon Decision Tree AlgorithmDocument10 pagesClassification Basedon Decision Tree AlgorithmAYMAN DAOUDINo ratings yet
- Research Article: Subha R., Anandakumar K and Bharathi ADocument7 pagesResearch Article: Subha R., Anandakumar K and Bharathi AyetsedawNo ratings yet
- One Size Does Not Fit All Methodological Consider PDFDocument12 pagesOne Size Does Not Fit All Methodological Consider PDFsiralkNo ratings yet
- ITNPAI1 Assignment S22Document3 pagesITNPAI1 Assignment S22Parisha BhatiaNo ratings yet
- ML Lab ManualDocument38 pagesML Lab ManualRahulNo ratings yet
- W7 Weka ClassificationDocument7 pagesW7 Weka ClassificationAzfar JijiNo ratings yet
- Heart Disease Prediction Using Adaptive Infinite Feature Selection and Deep Neural NetworksDocument6 pagesHeart Disease Prediction Using Adaptive Infinite Feature Selection and Deep Neural NetworksmanoNo ratings yet
- 2022 Biorxiv ESMFoldDocument28 pages2022 Biorxiv ESMFoldliuyuhang199912No ratings yet
- A Data Analytics Tutorial Building PredictiveDocument15 pagesA Data Analytics Tutorial Building PredictivesariNo ratings yet
- AI Promt Engineering Prelim ExamDocument19 pagesAI Promt Engineering Prelim ExamAdrian CrisostomoNo ratings yet
- Artificial Neural NetworksDocument15 pagesArtificial Neural NetworksSaiNo ratings yet
- Using Machine Learning Algorithms On Prediction of Stock Price-SVRDocument16 pagesUsing Machine Learning Algorithms On Prediction of Stock Price-SVRshahabcontrolNo ratings yet
- BTP ReportDocument17 pagesBTP ReportSAJAL PATHAKNo ratings yet
- Farzana 2020Document5 pagesFarzana 2020ShreerakshaNo ratings yet
- Dissertation PBA Publication VersionDocument225 pagesDissertation PBA Publication VersionErnesto Anaya OlivaresNo ratings yet
- ArticleDocument35 pagesArticleJasmine AwatramaniNo ratings yet
- 12 Bida - 630 - Final - Exam - Preparations PDFDocument7 pages12 Bida - 630 - Final - Exam - Preparations PDFWubneh AlemuNo ratings yet
- CNN sensor fault detectionDocument21 pagesCNN sensor fault detectionSrushti GiriNo ratings yet
- Vision Transformer Based Forest Fire Detection For Smart Alert SystemsDocument6 pagesVision Transformer Based Forest Fire Detection For Smart Alert Systemsvasuhi srinivasanNo ratings yet
- Research Article: A Model For Surface Defect Detection of Industrial Products Based On Attention AugmentationDocument12 pagesResearch Article: A Model For Surface Defect Detection of Industrial Products Based On Attention AugmentationUmar MajeedNo ratings yet
- MC4301 - ML Unit 2 (Model Evaluation and Feature Engineering)Document40 pagesMC4301 - ML Unit 2 (Model Evaluation and Feature Engineering)prathab031No ratings yet
- Students Placement Prediction Using Machine Learning AlgorithmsDocument14 pagesStudents Placement Prediction Using Machine Learning AlgorithmsIpsita MohantyNo ratings yet
- DSC652 Project-Stroke Prediction SystemDocument22 pagesDSC652 Project-Stroke Prediction SystemNur DanielNo ratings yet
- Eye-Tracking Image Encoding Autoencoders For The Crossing of Language Boundaries in Developmental Dyslexia DetectionDocument10 pagesEye-Tracking Image Encoding Autoencoders For The Crossing of Language Boundaries in Developmental Dyslexia DetectionLakshmi PriyaNo ratings yet
- Facereminder Mobile Application For Prosopagnosia Patients: EthodologyDocument4 pagesFacereminder Mobile Application For Prosopagnosia Patients: EthodologySuhaila AhmedNo ratings yet
- Diabetes Prediction Using Machine LearningDocument6 pagesDiabetes Prediction Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Construction Cost Estimation Model and Dynamic Management Control Analysis Based On Artificial IntelligenceDocument12 pagesConstruction Cost Estimation Model and Dynamic Management Control Analysis Based On Artificial IntelligenceSanyam AgrawalNo ratings yet
- Machine Learning SimplifiedDocument109 pagesMachine Learning SimplifiedGolamRasselNo ratings yet
- Tigist Hidru 2020Document89 pagesTigist Hidru 2020Mulugeta Tesfaye AlulaNo ratings yet
- Multilinear ProblemStatementDocument132 pagesMultilinear ProblemStatementSBS MoviesNo ratings yet