You might also like
- BCA - 1st - SEMESTER - MATH NotesDocument25 pagesBCA - 1st - SEMESTER - MATH Noteskiller botNo ratings yet
- Problem 1: Homework 6Document11 pagesProblem 1: Homework 6Akansha Kalra0% (1)
- Quantitative Methods (10 Chapters)Document54 pagesQuantitative Methods (10 Chapters)Ravish Chandra67% (3)
- Smart Algorithms Multimedia ImagingDocument439 pagesSmart Algorithms Multimedia ImagingMukesh PanchalNo ratings yet
- Assignment Problems For OsDocument4 pagesAssignment Problems For Osmanishbhavesh0% (1)
- Module 2 - DS IDocument94 pagesModule 2 - DS IRoudra ChakrabortyNo ratings yet
- Analisis Peubah Ganda 2Document61 pagesAnalisis Peubah Ganda 2Azmi FaisalNo ratings yet
- Eigenvector and Eigenvalue ProjectDocument10 pagesEigenvector and Eigenvalue ProjectIzzy ConceptsNo ratings yet
- Module 1 Theory of MatricesDocument75 pagesModule 1 Theory of MatricesShashank MahaleNo ratings yet
- PcaDocument73 pagesPca1balamanianNo ratings yet
- 2 - Linear AlgebraDocument52 pages2 - Linear AlgebraJani Saida ShaikNo ratings yet
- Data Mining: Dimensionality Reduction Pca - SVDDocument33 pagesData Mining: Dimensionality Reduction Pca - SVDArul Kumar VenugopalNo ratings yet
- PresentationDocument31 pagesPresentationAileen AngNo ratings yet
- Basic Math Review for Linear Algebra CourseDocument13 pagesBasic Math Review for Linear Algebra Coursetejas.s.mathaiNo ratings yet
- Lec 4Document39 pagesLec 4Bint-E- Haw'waNo ratings yet
- MATRICESDocument25 pagesMATRICESAli RazaNo ratings yet
- Dimensionality ReductionDocument37 pagesDimensionality ReductionAkesh Varma KothapalliNo ratings yet
- Module 2 ML Mumbai UniversityDocument39 pagesModule 2 ML Mumbai University2021.shreya.pawaskarNo ratings yet
- Dimensionality Reduction Unit-5 Dr. H C Vijayalakshmi: Reference 1. AmpleDocument66 pagesDimensionality Reduction Unit-5 Dr. H C Vijayalakshmi: Reference 1. AmpleBatemanNo ratings yet
- Lecture 15Document43 pagesLecture 15Apel KingNo ratings yet
- Basic Mathematical Foundation of Vectors and MatricesDocument60 pagesBasic Mathematical Foundation of Vectors and Matricesayush247No ratings yet
- Matrices: Q1. What Is Diagonalization in Matrices Means? Also Explain by Constructing An ExampleDocument14 pagesMatrices: Q1. What Is Diagonalization in Matrices Means? Also Explain by Constructing An ExampleFaizan AhmadNo ratings yet
- Lecture 9 Unit2Document168 pagesLecture 9 Unit2Siddharth SidhuNo ratings yet
- Elhabian ICP09Document130 pagesElhabian ICP09angeliusNo ratings yet
- Deep LearningDocument28 pagesDeep Learning20010700No ratings yet
- Chapter9 - Eigenvector and EigenvalueDocument28 pagesChapter9 - Eigenvector and EigenvalueRahul SharmaNo ratings yet
- Linear Algebra - Module 1Document52 pagesLinear Algebra - Module 1TestNo ratings yet
- CL2014 - MATLAB Programming - Lec03Document16 pagesCL2014 - MATLAB Programming - Lec03UmarNo ratings yet
- Eigenvalues and EigenvectorsDocument24 pagesEigenvalues and EigenvectorswkpfckgwNo ratings yet
- Abdi EVD2007 Pretty PDFDocument10 pagesAbdi EVD2007 Pretty PDFaliNo ratings yet
- Principal Component Analysis: Courtesy:University of Louisville, CVIP LabDocument48 pagesPrincipal Component Analysis: Courtesy:University of Louisville, CVIP LabIyyakutti GanapathiNo ratings yet
- Graph Eigenvalues Explained: Largest, Smallest, Gap and MoreDocument29 pagesGraph Eigenvalues Explained: Largest, Smallest, Gap and MoreDenise ParksNo ratings yet
- CS168: The Modern Algorithmic Toolbox Lecture #9: The Singular Value Decomposition (SVD) and Low-Rank Matrix ApproximationsDocument10 pagesCS168: The Modern Algorithmic Toolbox Lecture #9: The Singular Value Decomposition (SVD) and Low-Rank Matrix Approximationsenjamamul hoqNo ratings yet
- Definition Eigenvalue and EigenvectorDocument5 pagesDefinition Eigenvalue and Eigenvectortunghuong211No ratings yet
- Lecture 1-Matrix AlgebraDocument56 pagesLecture 1-Matrix AlgebraNashwa mahgoubNo ratings yet
- Rank of A Matrix: M × N M × NDocument4 pagesRank of A Matrix: M × N M × NDevenderNo ratings yet
- Linear Algebra I: Matrix Fundamentals in 40 CharactersDocument43 pagesLinear Algebra I: Matrix Fundamentals in 40 CharactersDaniel GreenNo ratings yet
- 4 - Vectors and Tensors - Lesson4Document22 pages4 - Vectors and Tensors - Lesson4emmanuel FOYETNo ratings yet
- Eigen Vectors: TopicDocument7 pagesEigen Vectors: TopicUmar HaroonNo ratings yet
- Fom Assignment 1Document23 pagesFom Assignment 11BACS ABHISHEK KUMARNo ratings yet
- Vector Space PresentationDocument26 pagesVector Space Presentationmohibrajput230% (1)
- Session - 5: Eigen Values and Eigen VectorsDocument14 pagesSession - 5: Eigen Values and Eigen VectorsprakashjogaNo ratings yet
- Vector Algebra and Calculus: Stephen RobertsDocument36 pagesVector Algebra and Calculus: Stephen RobertsRoselle AnireNo ratings yet
- Application of Eigen Value N Eigen VectorDocument15 pagesApplication of Eigen Value N Eigen VectorAman KheraNo ratings yet
- Rank of A MatrixDocument4 pagesRank of A MatrixSouradeep J ThakurNo ratings yet
- Lecture2 12977Document13 pagesLecture2 12977Aayush GodaraNo ratings yet
- Shear transformation of vector 3i^+2jDocument23 pagesShear transformation of vector 3i^+2jIgorJales100% (1)
- 4..linear Algebra. 1Document36 pages4..linear Algebra. 1hiran peirisNo ratings yet
- Engg AnalysisDocument117 pagesEngg AnalysisrajeshtaladiNo ratings yet
- Prob RV Opt BasicsDocument35 pagesProb RV Opt BasicsjfdweijNo ratings yet
- Vectors and Spaces in 40 CharactersDocument73 pagesVectors and Spaces in 40 CharactersAhmed AdelNo ratings yet
- Matrix Factorizations and Low Rank ApproximationDocument11 pagesMatrix Factorizations and Low Rank ApproximationtantantanNo ratings yet
- Network Analysis and Mining: PagerankDocument18 pagesNetwork Analysis and Mining: PagerankManogna GvNo ratings yet
- Transforms PDFDocument30 pagesTransforms PDFmuskan agarwalNo ratings yet
- Eigenvalues and Eigenvectors and Their ApplicationsDocument43 pagesEigenvalues and Eigenvectors and Their ApplicationsDr. P.K.Sharma93% (15)
- PCA: Principle Components AnalysisDocument39 pagesPCA: Principle Components AnalysisAsimullah, M.Phil. Scholar Department of Computer Science, UoPNo ratings yet
- Eigen Vectors, Eigen Values and MatricesDocument2 pagesEigen Vectors, Eigen Values and MatricesShashank KumarNo ratings yet
- Properties and SignificanceDocument19 pagesProperties and SignificancexcalibratorNo ratings yet
- Term Paper of Mathematics: Submitted To:-Miss Saloni SUBMITTED ON:-12-11-2010Document21 pagesTerm Paper of Mathematics: Submitted To:-Miss Saloni SUBMITTED ON:-12-11-2010Charanjeet SinghNo ratings yet
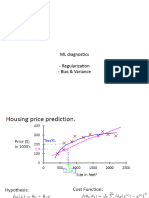
- Bias-Variance Trade-OffDocument28 pagesBias-Variance Trade-OffRoudra ChakrabortyNo ratings yet
- Module 4 SVM PCA KmeansDocument101 pagesModule 4 SVM PCA KmeansRoudra ChakrabortyNo ratings yet
- Module-2 - Assessing Accuracy of ModelDocument24 pagesModule-2 - Assessing Accuracy of ModelRoudra ChakrabortyNo ratings yet
- Orientation - Basic Mathematics and Statistics - NDDocument33 pagesOrientation - Basic Mathematics and Statistics - NDRoudra ChakrabortyNo ratings yet
- Orientation - Basic Mathematics and Statistics - ProbabilityDocument48 pagesOrientation - Basic Mathematics and Statistics - ProbabilityRoudra ChakrabortyNo ratings yet
- Orientation - Basic Mathematics and Statistics - DifferentiationDocument20 pagesOrientation - Basic Mathematics and Statistics - DifferentiationRoudra ChakrabortyNo ratings yet
- Basic Maths and Stats: Cartesian Coordinates, Straight Lines, Distance FormulasDocument15 pagesBasic Maths and Stats: Cartesian Coordinates, Straight Lines, Distance FormulasRoudra ChakrabortyNo ratings yet
- Orientation - Basic Mathematics and Statistics - CTDDocument35 pagesOrientation - Basic Mathematics and Statistics - CTDRoudra ChakrabortyNo ratings yet
- 2009-Worst-Case and Statistical Tolerance Analysis Monte CarloDocument12 pages2009-Worst-Case and Statistical Tolerance Analysis Monte CarloZvonko TNo ratings yet
- STANDARD COSTING With GP VARIANCE ANALYSIS KEY ANSWERSDocument19 pagesSTANDARD COSTING With GP VARIANCE ANALYSIS KEY ANSWERSaziel caith florentinNo ratings yet
- Anchor Chain Locker Volume CalculationDocument1 pageAnchor Chain Locker Volume Calculationbasant_konatNo ratings yet
- MATH TOS 2ND Q .DocxnewDocument3 pagesMATH TOS 2ND Q .DocxnewAiza Mae Libarnes DoleraNo ratings yet
- Analytic Geometry 3Document2 pagesAnalytic Geometry 3Aerdna Ela RuzNo ratings yet
- 8221 - Tutorial 1 Line IntegralDocument6 pages8221 - Tutorial 1 Line IntegralVictor LoongNo ratings yet
- Engine 2Document7 pagesEngine 2pilas_nikolaNo ratings yet
- Data Preparation: KIT306/606: Data Analytics A/Prof. Quan Bai University of TasmaniaDocument49 pagesData Preparation: KIT306/606: Data Analytics A/Prof. Quan Bai University of TasmaniaJason ZengNo ratings yet
- MDM EverlynDocument15 pagesMDM EverlynSeth OderaNo ratings yet
- Bayes Theorem 2Document14 pagesBayes Theorem 2Muhammad YahyaNo ratings yet
- The Operational MeteorologyDocument102 pagesThe Operational MeteorologyVasile AdrianNo ratings yet
- Kirchhoff Love Plate Theory Wikipedia The Free EncyclopediaDocument12 pagesKirchhoff Love Plate Theory Wikipedia The Free EncyclopediajoneNo ratings yet
- WErbsen CourseworkDocument562 pagesWErbsen CourseworkRoberto Alexis Rodríguez TorresNo ratings yet
- Probabilistic Information Retrieval ModelDocument51 pagesProbabilistic Information Retrieval ModelBirhane Bekele KebedeNo ratings yet
- Research Variables GuideDocument3 pagesResearch Variables GuideClaraNo ratings yet
- Sine-And-Cosine-Rules 3Document10 pagesSine-And-Cosine-Rules 3Farzad FarhadNo ratings yet
- UAE CST Framework PDFDocument280 pagesUAE CST Framework PDFChitra BharghavNo ratings yet
- To Data Structure: WWW - Eshikshak.co - inDocument10 pagesTo Data Structure: WWW - Eshikshak.co - inDiya MinhasNo ratings yet
- 2 Po1 PDFDocument13 pages2 Po1 PDFakileshwardinaNo ratings yet
- Bio-Data (DR.P.K.sharMA) As On 13th June 2023Document34 pagesBio-Data (DR.P.K.sharMA) As On 13th June 2023Poonam Kumar SharmaNo ratings yet
- Embedded Computing Systems - App - Mohamed KhalguiDocument559 pagesEmbedded Computing Systems - App - Mohamed KhalguiOssama Jdidi100% (1)
- Orthorectification Using Erdas ImagineDocument14 pagesOrthorectification Using Erdas ImagineArga Fondra OksapingNo ratings yet
- P3 Mathematics MIDTERM I JOINT EXAMINATION 2013 PDFDocument6 pagesP3 Mathematics MIDTERM I JOINT EXAMINATION 2013 PDFsimbi yusufNo ratings yet
- Entropy Measures For Plithogenic Sets and Applications in Multi-Attribute Decision MakingDocument17 pagesEntropy Measures For Plithogenic Sets and Applications in Multi-Attribute Decision MakingScience DirectNo ratings yet
- Unit 1 Language Acquisition: StructureDocument17 pagesUnit 1 Language Acquisition: StructureKarunakar MallickNo ratings yet
- Bevel ProtractorDocument3 pagesBevel ProtractorAnonymous k0timyBdYNo ratings yet
- Chapter 17 - Markov ChainsDocument51 pagesChapter 17 - Markov ChainsramixzNo ratings yet