You might also like
- Computer Systems: Lecture 7: Virtual MemoryDocument103 pagesComputer Systems: Lecture 7: Virtual MemoryBindu K RNo ratings yet
- Module 2 ACA NotesDocument31 pagesModule 2 ACA NotesShylaja100% (1)
- Segmentation and Paging: SolutionsDocument6 pagesSegmentation and Paging: SolutionsNguyễn Phan Đăng KhoaNo ratings yet
- Paging Virtual Memory: Nima Honarmand (Based On Slides by Prof. Andrea Arpaci-Dusseau)Document39 pagesPaging Virtual Memory: Nima Honarmand (Based On Slides by Prof. Andrea Arpaci-Dusseau)HIRAN KUMAR SINHANo ratings yet
- Virtual Memory: Programmer Illusion of Large Memory SpaceDocument18 pagesVirtual Memory: Programmer Illusion of Large Memory SpaceMudit JainNo ratings yet
- Chapter-4-Continued (Autosaved)Document29 pagesChapter-4-Continued (Autosaved)Doc TelNo ratings yet
- Advanced Operating Systems Memory Management TechniquesDocument22 pagesAdvanced Operating Systems Memory Management TechniquesGES ISLAMIA PATTOKINo ratings yet
- Main Memory: Address Translation: (Chapter 8)Document38 pagesMain Memory: Address Translation: (Chapter 8)GauravNo ratings yet
- Uà U U ! "#À $ % U #! ! % !! &'à (U!! ! %) U Usually We Don't Notice Any Performance Problems)Document37 pagesUà U U ! "#À $ % U #! ! % !! &'à (U!! ! %) U Usually We Don't Notice Any Performance Problems)smadi13No ratings yet
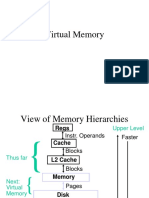
- Virtual Memory: View of Memory Hierarchies and Address TranslationDocument23 pagesVirtual Memory: View of Memory Hierarchies and Address Translationshailendra tripathiNo ratings yet
- Matdid 834000Document16 pagesMatdid 834000drerNo ratings yet
- 12 VirtualMemoryDocument22 pages12 VirtualMemoryManoj Kumar GNo ratings yet
- 9-Memory Management PDFDocument20 pages9-Memory Management PDFanotherstupidregistrNo ratings yet
- IKI10230 Pengantar Organisasi Komputer Kuliah No. 04: Assembly LanguageDocument73 pagesIKI10230 Pengantar Organisasi Komputer Kuliah No. 04: Assembly LanguageHerman YuliandokoNo ratings yet
- Chapter 8 - Main Memory - Part IIDocument19 pagesChapter 8 - Main Memory - Part IIas ddadaNo ratings yet
- L06 - RISCVII (Revised)Document48 pagesL06 - RISCVII (Revised)itheachtholly1227No ratings yet
- 1 AnnouncementsDocument3 pages1 AnnouncementsDaveNo ratings yet
- Explore Computer Architecture Memory HierarchyDocument20 pagesExplore Computer Architecture Memory HierarchyUmair KhalidNo ratings yet
- VM PagingDocument46 pagesVM PagingchetanNo ratings yet
- Fixing Memory IssuesDocument171 pagesFixing Memory IssuesSubhapam KunduNo ratings yet
- Virtualmemory 1upDocument57 pagesVirtualmemory 1upcalvinndzi82No ratings yet
- CSE 332 L 15 Complete - 26th Sep 2020Document16 pagesCSE 332 L 15 Complete - 26th Sep 2020Nz SaadNo ratings yet
- ECE344 Memory Management Lecture Covers Virtual Memory ConceptsDocument41 pagesECE344 Memory Management Lecture Covers Virtual Memory ConceptsPartha KuriNo ratings yet
- Lec7 - Os - PK - MemDocument41 pagesLec7 - Os - PK - MemPartha KuriNo ratings yet
- Lec7 - Os - PK - MemDocument41 pagesLec7 - Os - PK - MemPartha KuriNo ratings yet
- Virtual Memory ExplainedDocument14 pagesVirtual Memory Explainedking vjNo ratings yet
- Comp Science BestDocument24 pagesComp Science BestcollenNo ratings yet
- Igcse Computer Science Paper 1 Revision Notes Igcse Computer Science Paper 1 Revision NotesDocument25 pagesIgcse Computer Science Paper 1 Revision Notes Igcse Computer Science Paper 1 Revision NotesGhost VenomousNo ratings yet
- FilesDocument26 pagesFilesArnaldo CanelasNo ratings yet
- Virtual Memory: CS151B/EE M116C Computer Systems ArchitectureDocument16 pagesVirtual Memory: CS151B/EE M116C Computer Systems ArchitecturetinhtrilacNo ratings yet
- Virtual Memory OptimizationDocument20 pagesVirtual Memory Optimizationmhmd2222No ratings yet
- s13 Address TranslationDocument33 pagess13 Address TranslationSrinivasa Rao TNo ratings yet
- Memory ManagementDocument13 pagesMemory ManagementRowid Sami RulesNo ratings yet
- Oracle Cloud Block Volume 100Document23 pagesOracle Cloud Block Volume 100Dharmesh BNo ratings yet
- The Internals of Hello WorldDocument74 pagesThe Internals of Hello WorldstanleyhsuNo ratings yet
- Core Dump Analysis Guide for Debugging CrashesDocument31 pagesCore Dump Analysis Guide for Debugging CrashesRahul BiliyeNo ratings yet
- Computer Systems: Lecture 7: Virtual MemoryDocument103 pagesComputer Systems: Lecture 7: Virtual MemorysravaniNo ratings yet
- Lecture21 PDFDocument34 pagesLecture21 PDFTimothy EngNo ratings yet
- DBMS Storage and IndexingDocument90 pagesDBMS Storage and IndexingKarthik_Srinan_6524No ratings yet
- Mansoura University Faculty of Computers and Information Department of Computer Science First Semester: 2021-2022Document29 pagesMansoura University Faculty of Computers and Information Department of Computer Science First Semester: 2021-2022Yahia ShahinNo ratings yet
- Operating Systems Memory ManagementDocument32 pagesOperating Systems Memory ManagementSahra SoltaneNo ratings yet
- Addressing Modes I: - The MFC5270 Registers Have 32 Bits - The Data Bus Is 32 Bits Wide - Instructions Can Operate OnDocument24 pagesAddressing Modes I: - The MFC5270 Registers Have 32 Bits - The Data Bus Is 32 Bits Wide - Instructions Can Operate OnMoe M.DiraaNo ratings yet
- Disk Storage DependabilityDocument79 pagesDisk Storage Dependabilitysdhanesh84No ratings yet
- Chapter 3 Large and FastDocument86 pagesChapter 3 Large and Fastquejaukennoitrei-2168No ratings yet
- Week 9 Segmentation Paged Seg Virtual ConceptDocument24 pagesWeek 9 Segmentation Paged Seg Virtual Conceptmanyagarg787No ratings yet
- Memory Management TopicsDocument6 pagesMemory Management Topicstemp321No ratings yet
- 01 IntroDocument34 pages01 IntroManpreet SinghNo ratings yet
- Chapter 3 HandoutDocument23 pagesChapter 3 HandoutSileshi Bogale HaileNo ratings yet
- 10 Os Paging PDFDocument30 pages10 Os Paging PDFanotherstupidregistrNo ratings yet
- COA MemorySystemDocument76 pagesCOA MemorySystemAMARTYA KUMARNo ratings yet
- OS Chapter Key Terms and ReviewDocument2 pagesOS Chapter Key Terms and ReviewJuan L AlarconNo ratings yet
- Asm 1Document400 pagesAsm 1EnzoVibioNo ratings yet
- Operating System Ch10Document22 pagesOperating System Ch10shahrianNo ratings yet
- Answers of Chapter (8) : Course: Operating SystemDocument7 pagesAnswers of Chapter (8) : Course: Operating SystemasdNo ratings yet
- Assignment 2 SolutionDocument5 pagesAssignment 2 SolutionRaza KazmiNo ratings yet
- Operating System 2nd Edition - Topik 10Document57 pagesOperating System 2nd Edition - Topik 10mhmmdnaufalmuflihNo ratings yet
- Advanced Buffer Overflow Technique: Greg HoglundDocument76 pagesAdvanced Buffer Overflow Technique: Greg HoglundNunu CreebowNo ratings yet
- Slide 5Document43 pagesSlide 5dejenedagime999No ratings yet
- INSTR-40Document35 pagesINSTR-40Arsalan JohnNo ratings yet
- 09 SecurityDocument51 pages09 SecuritymaykelnawarNo ratings yet
- 15 MLDocument60 pages15 MLmaykelnawarNo ratings yet
- Parallel Progamming With PthreadsDocument79 pagesParallel Progamming With PthreadsmaykelnawarNo ratings yet
- Cheat SheetDocument6 pagesCheat SheetmaykelnawarNo ratings yet
- Fall 2015 PHD OrientationDocument54 pagesFall 2015 PHD OrientationmaykelnawarNo ratings yet
- Osproject 2010Document2 pagesOsproject 2010maykelnawarNo ratings yet
- Live ForensicsDocument116 pagesLive ForensicsAmarsammy VakaNo ratings yet
- OSDocument32 pagesOSAnjali VermaNo ratings yet
- CS4310 MemoryManagementDocument40 pagesCS4310 MemoryManagementtototoNo ratings yet
- CS3350B Computer Architecture Memory Hierarchy: Why?: Marc Moreno MazaDocument30 pagesCS3350B Computer Architecture Memory Hierarchy: Why?: Marc Moreno MazaAsHraf G. ElrawEiNo ratings yet
- Docs Openhwgroup Org Cva6 User Manual en LatestDocument150 pagesDocs Openhwgroup Org Cva6 User Manual en LatestJim JimNo ratings yet
- Assignment in Memory ManagementDocument2 pagesAssignment in Memory ManagementBajjuri RõhanNo ratings yet
- ITEC582 Chapter15Document22 pagesITEC582 Chapter15Moataz BelkhairNo ratings yet
- Datasheet AMD Alchemy Au1100Document414 pagesDatasheet AMD Alchemy Au1100Cosmin CodrescuNo ratings yet
- SPRING 2015 CDA 3101 Homework 3: Date-Assigned: Mar 27th, 2015 Due Dates: 11:55pm, April 7th, 2015Document5 pagesSPRING 2015 CDA 3101 Homework 3: Date-Assigned: Mar 27th, 2015 Due Dates: 11:55pm, April 7th, 2015ayylmao kekNo ratings yet
- Virtual Memory: S. DandamudiDocument45 pagesVirtual Memory: S. DandamudiPrem PrakashNo ratings yet
- Answer:: CS1541 Fall 2008 Solution To The Optional Homework On Virtual MemoryDocument6 pagesAnswer:: CS1541 Fall 2008 Solution To The Optional Homework On Virtual MemoryJohn BoyNo ratings yet
- William Stallings Computer Organization and Architecture 8 Edition Operating System SupportDocument66 pagesWilliam Stallings Computer Organization and Architecture 8 Edition Operating System SupportRenu PeriketiNo ratings yet
- OsDocument8 pagesOsCristina TocuNo ratings yet
- Unit 4aDocument104 pagesUnit 4aKoushik ThummalaNo ratings yet
- Chapter 04 Processors and Memory HierarchyDocument50 pagesChapter 04 Processors and Memory Hierarchyশেখ আরিফুল ইসলাম75% (8)
- Unit 5 DpcoDocument20 pagesUnit 5 Dpcoshinyshiny966No ratings yet
- Kernel Memory ManagementDocument37 pagesKernel Memory ManagementSneha DollyNo ratings yet
- Two Marks Questions with Answers on Computer ArchitectureDocument19 pagesTwo Marks Questions with Answers on Computer ArchitectureAKASH KSNo ratings yet
- VirtualDocument9 pagesVirtualOsaigbovo TimothyNo ratings yet
- Unit 4Document39 pagesUnit 4PrashantNo ratings yet
- Explain The Concept of ReentrancyDocument3 pagesExplain The Concept of ReentrancymaniarunaiNo ratings yet
- DDI0333H Arm1176jzs r0p7 TRMDocument658 pagesDDI0333H Arm1176jzs r0p7 TRMసుమధుర కళ్యాణ్No ratings yet
- GATE Paper CS-2006Document28 pagesGATE Paper CS-2006Vijaya GoelNo ratings yet
- CMPSCI 377 Operating Systems Lecture 15Document2 pagesCMPSCI 377 Operating Systems Lecture 15DaveNo ratings yet
- OSDocument40 pagesOSAmalaDevi LakshminarayanaNo ratings yet
- Assignment 5 OsDocument11 pagesAssignment 5 OsAmit SharmaNo ratings yet
- CSE 378 - Machine Organization & Assembly Language - Winter 2009 HW #4Document11 pagesCSE 378 - Machine Organization & Assembly Language - Winter 2009 HW #4Sia SharmaNo ratings yet
- Anasua Bhowmik - RYZEN PROCESSOR MICROARCHITECTURE at CASS18Document26 pagesAnasua Bhowmik - RYZEN PROCESSOR MICROARCHITECTURE at CASS18Vlad VahnovanuNo ratings yet
- Arm11 Mpcore r1p0 TRMDocument730 pagesArm11 Mpcore r1p0 TRMAman SainiNo ratings yet