You might also like
- Biofilter Design PDFDocument119 pagesBiofilter Design PDFSumoharjo La MpagaNo ratings yet
- 02 - Rational InequalitiesDocument2 pages02 - Rational InequalitiesMahmoud Abdel-SalamNo ratings yet
- CredenceDocument2 pagesCredenceAlan AnunciaçãoNo ratings yet
- 2 ADA Cluster AnalysisDocument12 pages2 ADA Cluster AnalysisAshNo ratings yet
- Your Feminine Roadmap To His CommitmentDocument74 pagesYour Feminine Roadmap To His CommitmentAndreea Lungu100% (2)
- Method Statement Concrete PouringDocument4 pagesMethod Statement Concrete PouringSmart ShivaNo ratings yet
- 02 - Rational Inequalities PDFDocument2 pages02 - Rational Inequalities PDFMaria Hupie OndoNo ratings yet
- Fly Me To The MoonDocument5 pagesFly Me To The MoonFranco SeminarioNo ratings yet
- Mindsets&Habits - Tej DosaDocument28 pagesMindsets&Habits - Tej DosaDylan Lopez100% (1)
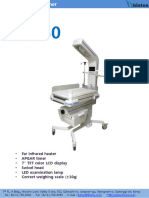
- Bistos BT-550 - CatalogoDocument3 pagesBistos BT-550 - CatalogoRobinsson Tafur FloridaNo ratings yet
- Grid Level1 1Document2 pagesGrid Level1 1api-256386911No ratings yet
- Short Time Fourier AnalysisDocument28 pagesShort Time Fourier AnalysisMohamed Hasan MutarNo ratings yet
- 09 - Cramer's RuleDocument2 pages09 - Cramer's Rulehey shartyNo ratings yet
- Heathers SongDocument12 pagesHeathers SongFrancisco RuaNo ratings yet
- Dip QpaperDocument4 pagesDip QpaperSHOBHIT KUMAR SONI cs20No ratings yet
- CredenceDocument2 pagesCredenceAlan AnunciaçãoNo ratings yet
- CredenceDocument2 pagesCredenceAlan AnunciaçãoNo ratings yet
- (This Band) - Hindi Na Nga - Arrange by Mark SagumDocument11 pages(This Band) - Hindi Na Nga - Arrange by Mark SagumShane Liah MapilesNo ratings yet
- 10 - Exercise On One Way ANOVADocument4 pages10 - Exercise On One Way ANOVAJohn Cedric Vale CruzNo ratings yet
- Derivatives 1Document2 pagesDerivatives 1Alexander HwangNo ratings yet
- TC - CH 2.7 Implicit Diff Extra PracticeDocument2 pagesTC - CH 2.7 Implicit Diff Extra PracticeGene TecsonNo ratings yet
- 4.multiplenaive - Jupyter NotebookDocument4 pages4.multiplenaive - Jupyter NotebookDevansh SuwalkaNo ratings yet
- Chapter ThreeDocument32 pagesChapter ThreemathewosNo ratings yet
- Pascals Triangle and Binomial WsDocument3 pagesPascals Triangle and Binomial WsJiwanshi ShahNo ratings yet
- Unit 5 HW 5 Solving Systems by Elimination WSDocument2 pagesUnit 5 HW 5 Solving Systems by Elimination WSheckerNo ratings yet
- Differentiating Productsand Quotientsof Functions PR4 BDocument4 pagesDifferentiating Productsand Quotientsof Functions PR4 BAlperen ÇelebiNo ratings yet
- AnswersDocument6 pagesAnswerspvqyhzfgy6No ratings yet
- Year 4 Worksheet With AnswerDocument6 pagesYear 4 Worksheet With Answerpvqyhzfgy6No ratings yet
- Second Moment of Composite AreasDocument3 pagesSecond Moment of Composite AreasCarl SorensenNo ratings yet
- Chapter P Preparation For CalculusDocument44 pagesChapter P Preparation For CalculusAsad MehboobNo ratings yet
- 2 D Transformation: Computer GraphicDocument43 pages2 D Transformation: Computer Graphicarup sarkerNo ratings yet
- Lay 1.2Document11 pagesLay 1.2pri shNo ratings yet
- 02 - Rational Inequalities PDFDocument2 pages02 - Rational Inequalities PDFJulius LitaNo ratings yet
- 02 - Rational Inequalities PDFDocument2 pages02 - Rational Inequalities PDFWeslie Tabasa LegaspiNo ratings yet
- 02 - Rational InequalitiesDocument2 pages02 - Rational Inequalities0242605No ratings yet
- Math Grade 8Document2 pagesMath Grade 8Reximie D. Dollete Jr.No ratings yet
- Lattice Multiplication: Use The Lattice Grids To Solve The Multiplication Problems. 32 X 71 30 X 54Document2 pagesLattice Multiplication: Use The Lattice Grids To Solve The Multiplication Problems. 32 X 71 30 X 54kalam715265No ratings yet
- I'm Awake: Intervals The Shape of ColourDocument15 pagesI'm Awake: Intervals The Shape of ColourNicolasFigueroaLeonNo ratings yet
- Intro - Background MusicDocument2 pagesIntro - Background MusichgvjhgjhvkNo ratings yet
- Intro No.1 PDFDocument2 pagesIntro No.1 PDFAn Nguyen VinhNo ratings yet
- Intro 1 PDFDocument2 pagesIntro 1 PDFAn Nguyen VinhNo ratings yet
- Intro - Background MusicDocument2 pagesIntro - Background MusicJonNo ratings yet
- Intro - Background Music PDFDocument2 pagesIntro - Background Music PDFponnyangNo ratings yet
- A lover's Concerto小步舞曲Document4 pagesA lover's Concerto小步舞曲Yun Kwan ChongNo ratings yet
- 5.5 WKSHT Solve For Y and GraphDocument2 pages5.5 WKSHT Solve For Y and GraphDraco MalfoyNo ratings yet
- Sungha Jung MosaicDocument10 pagesSungha Jung MosaicDanielGutierrezTorresNo ratings yet
- 3 The Midpoint FormulaDocument5 pages3 The Midpoint FormulaJohn Ramer Lazarte InocencioNo ratings yet
- Konosuba 2 OP TommorowDocument6 pagesKonosuba 2 OP TommorowHải ĐăngNo ratings yet
- Quadratic Forms Intercept FormDocument4 pagesQuadratic Forms Intercept FormdevikaNo ratings yet
- Depapepe: Let's GoDocument4 pagesDepapepe: Let's Go黄子岳No ratings yet
- COE4TL4 Lecture17Document13 pagesCOE4TL4 Lecture17Anonymous hDKqasfNo ratings yet
- Standard Form To Slope-Intercept Form: X y X yDocument2 pagesStandard Form To Slope-Intercept Form: X y X yasdwasdwaNo ratings yet
- Day2Handout (March21) 2024Document5 pagesDay2Handout (March21) 2024chaturvedikrish1No ratings yet
- Answer Surface Area and VolumeDocument2 pagesAnswer Surface Area and VolumepriyaNo ratings yet
- X̄ Weighted Mean (W X) Sum of The Multiplied Frequency W Sum of The PopulationDocument5 pagesX̄ Weighted Mean (W X) Sum of The Multiplied Frequency W Sum of The PopulationArnel AcojedoNo ratings yet
- (Tab) Fly Me To The MoonDocument3 pages(Tab) Fly Me To The MoonHenry Pava100% (1)
- Unit 4 Notes and Homework Answers ProofsDocument78 pagesUnit 4 Notes and Homework Answers Proofsvanessam100109No ratings yet
- Asal Kau Bahagia PDFDocument3 pagesAsal Kau Bahagia PDFdaniel aizatNo ratings yet
- BCI PHD SeminarDocument20 pagesBCI PHD Seminarastronom.saradnikNo ratings yet
- CS273a Final ExamDocument9 pagesCS273a Final ExamImeldaNo ratings yet
- Statistics Tutorial Solution 2020Document8 pagesStatistics Tutorial Solution 2020Sospeter EnockNo ratings yet
- Sungha Jung - (IU) EightDocument5 pagesSungha Jung - (IU) EighthianyoNo ratings yet
- 02 Impulsively Responsible GPDocument8 pages02 Impulsively Responsible GPNicolas Andres Guerrero Remolina33% (6)
- Ohp Week 8Document34 pagesOhp Week 8farah_natasha_5No ratings yet
- Impact of Airport'S Physical Environment On Passengers SatisfactionDocument16 pagesImpact of Airport'S Physical Environment On Passengers SatisfactionmeaowNo ratings yet
- Student Brag Sheet For Letter of RecommendationDocument4 pagesStudent Brag Sheet For Letter of RecommendationBatukaNo ratings yet
- CK140 Micro CNC LatheDocument5 pagesCK140 Micro CNC LatheWilson Sergio Martins DantasNo ratings yet
- Azrak Pipe ScheduleDocument1 pageAzrak Pipe ScheduleErcan YilmazNo ratings yet
- Office of The Mayor: Republic of The Philippines Province of La Union Municipality of Caba Tel. # (072) 607-03-12Document3 pagesOffice of The Mayor: Republic of The Philippines Province of La Union Municipality of Caba Tel. # (072) 607-03-12Sunshine MaglayaNo ratings yet
- Jetcontrol 600-S UK 17072014Document4 pagesJetcontrol 600-S UK 17072014Zeko AmeenNo ratings yet
- High-Quality Performance: Envg-B Enhanced Night Vision Goggle-BinocularDocument2 pagesHigh-Quality Performance: Envg-B Enhanced Night Vision Goggle-BinocularKyle YangNo ratings yet
- Review ArticleDocument20 pagesReview ArticleAndrés Camilo LópezNo ratings yet
- Fuel Consumption SpreadsheetDocument63 pagesFuel Consumption SpreadsheetcaptulccNo ratings yet
- Cambridge IGCSE (9-1) : Physics 0972/12Document20 pagesCambridge IGCSE (9-1) : Physics 0972/12Tristan GrahamNo ratings yet
- Educ 103Document2 pagesEduc 103Nina RkiveNo ratings yet
- Angl 5Document24 pagesAngl 5Latika ChoudhuryNo ratings yet
- MAT1175Document7 pagesMAT1175Naruto UwzumakiNo ratings yet
- Krauss - Photography's Discursive Spaces - Landscape-View - 1982Document10 pagesKrauss - Photography's Discursive Spaces - Landscape-View - 1982Noam GonnenNo ratings yet
- The in Uence of The Bourdon Effect On Pipe Elbow: September 2016Document11 pagesThe in Uence of The Bourdon Effect On Pipe Elbow: September 2016araz_1985No ratings yet
- 3QGB Screw PumpDocument7 pages3QGB Screw PumpWily WayerNo ratings yet
- GLR - CT Lesson PlanDocument4 pagesGLR - CT Lesson PlanMARY JOY DELAROSANo ratings yet
- Addis Ababa University Collage of Business and Economics Department of Accounting and Finance Project Title Abc FurnitureDocument40 pagesAddis Ababa University Collage of Business and Economics Department of Accounting and Finance Project Title Abc FurnitureHalu FikaduNo ratings yet
- Optical Fibre Cables SILECDocument12 pagesOptical Fibre Cables SILECTalha LiaqatNo ratings yet
- Information Transmission Using The Nonlinear Fourier Transform, Part I: Mathematical ToolsDocument18 pagesInformation Transmission Using The Nonlinear Fourier Transform, Part I: Mathematical Toolslina derbikhNo ratings yet
- Chapter 9-Hydroelectric Plant PDFDocument118 pagesChapter 9-Hydroelectric Plant PDFsindyNo ratings yet
- HIC SEA IV - Delegate ProspectusDocument12 pagesHIC SEA IV - Delegate ProspectusNguyễn Hồng PhượngNo ratings yet
- What Marijuana Does To The Teenage BrainDocument2 pagesWhat Marijuana Does To The Teenage BrainAdriana MirandaNo ratings yet
- Dynamic Child 1st Edition Manis Solutions Manual 1Document20 pagesDynamic Child 1st Edition Manis Solutions Manual 1lois100% (36)