You might also like
- Upgrade Rev. Manual Q33-V2.7Document17 pagesUpgrade Rev. Manual Q33-V2.7KY WongNo ratings yet
- Starlink Services LLC ETC Designation Application PDFDocument39 pagesStarlink Services LLC ETC Designation Application PDFSimon AlvarezNo ratings yet
- Asce Wind Load Examples PDFDocument126 pagesAsce Wind Load Examples PDFbrionkettler100% (3)
- Markov Chain AnalysisDocument19 pagesMarkov Chain AnalysisRaees AhmadNo ratings yet
- Tutorial 05Document16 pagesTutorial 05eragornNo ratings yet
- 2014 CN - Material 8 - MARKOV ChainDocument17 pages2014 CN - Material 8 - MARKOV ChainAndrew SetiawanNo ratings yet
- Computational Genomics Hidden Markov Models (HMMS)Document55 pagesComputational Genomics Hidden Markov Models (HMMS)pranati putrevuNo ratings yet
- Markov Models: Current Next Transition Probabilities CurrentDocument53 pagesMarkov Models: Current Next Transition Probabilities Currentpranati putrevu100% (1)
- Chapter 5 Markov Chains LectureDocument30 pagesChapter 5 Markov Chains LectureAlex AbebeNo ratings yet
- Chapter 4 - Discrete Time Markov ChainsDocument37 pagesChapter 4 - Discrete Time Markov ChainsMinh QuânNo ratings yet
- CH 05 - Markov ModelDocument69 pagesCH 05 - Markov ModelNazar AzizNo ratings yet
- Sequential Data and Markov Models: Sargur N. Srihari Machine Learning CourseDocument21 pagesSequential Data and Markov Models: Sargur N. Srihari Machine Learning CourseasdfasdffdsaNo ratings yet
- Bioinformatics-Lesson 07 - Hidden Markov ModelDocument28 pagesBioinformatics-Lesson 07 - Hidden Markov Modelmahedi hasanNo ratings yet
- Manufacturing System Flow Analysis: Ron@sie - Arizona.eduDocument30 pagesManufacturing System Flow Analysis: Ron@sie - Arizona.edujaga_desh86No ratings yet
- Markov ChainsDocument63 pagesMarkov Chainsprits92No ratings yet
- Min ImDocument17 pagesMin ImRam Charan KonidelaNo ratings yet
- Modified Nested Gridding For Upscaling Downscaling of Reservoir SimulationDocument22 pagesModified Nested Gridding For Upscaling Downscaling of Reservoir SimulationNaufal FadhlurachmanNo ratings yet
- Profiles HMMDocument27 pagesProfiles HMMRoshan PoudelNo ratings yet
- Markov Chain Monte Carlo in RDocument14 pagesMarkov Chain Monte Carlo in RCươngNguyễnBáNo ratings yet
- Week 6aDocument15 pagesWeek 6ahairen jegerNo ratings yet
- Binomial and Poission Distribution 6Document34 pagesBinomial and Poission Distribution 6ss tNo ratings yet
- (Last Week) : - Macroscopic Continuous Concentration RatesDocument54 pages(Last Week) : - Macroscopic Continuous Concentration RatesSatyam MohlaNo ratings yet
- Markov Chain - Math - 380 - F - s1 - 41corrDocument11 pagesMarkov Chain - Math - 380 - F - s1 - 41corrDiego SalazarNo ratings yet
- Lecture23 PDFDocument30 pagesLecture23 PDFVrundNo ratings yet
- CS109/Stat121/AC209/E-109 Data Science: Bayesian Methods Continued, Text DataDocument35 pagesCS109/Stat121/AC209/E-109 Data Science: Bayesian Methods Continued, Text Dataankit devNo ratings yet
- Quantum ComputingDocument30 pagesQuantum Computingmateo cangrejo angelNo ratings yet
- Ch5 Ken BlackDocument53 pagesCh5 Ken BlackArpit KapoorNo ratings yet
- Quantum AiDocument65 pagesQuantum AiVikram Babu mamidishettiNo ratings yet
- Mcmc-A Comparative StudyDocument29 pagesMcmc-A Comparative StudyNishantNo ratings yet
- COS495 Lecture14 MarkovLocalizationDocument30 pagesCOS495 Lecture14 MarkovLocalizationK04Anoushka TripathiNo ratings yet
- Hma13 Chapter09Document16 pagesHma13 Chapter09HARRY HINGNo ratings yet
- Lecture5 hmms1Document37 pagesLecture5 hmms1Beyene TsegayeNo ratings yet
- Orion Center: Computer Simulation: W.B.MoriDocument24 pagesOrion Center: Computer Simulation: W.B.Moridjyoti96No ratings yet
- Kunci Jawaban PMS Asis 9 (Markov)Document13 pagesKunci Jawaban PMS Asis 9 (Markov)Anida LalaNo ratings yet
- Markov Chains (Part 3) : State ClassificationDocument19 pagesMarkov Chains (Part 3) : State ClassificationEleazar Sierra EspinozaNo ratings yet
- T1 Light ScatteringDocument55 pagesT1 Light ScatteringMadurika AhugammanaNo ratings yet
- Markov ChainsDocument63 pagesMarkov ChainsIbrahim El SharNo ratings yet
- 3D QsarDocument83 pages3D Qsarmilin100% (2)
- Physics 332 Special RelativityDocument34 pagesPhysics 332 Special RelativityFisModerna Fisica Ieica Esimez IpnNo ratings yet
- EE769 13 Density Estimation and SamplingDocument19 pagesEE769 13 Density Estimation and Samplingfun worldNo ratings yet
- MarkovDocument31 pagesMarkovPratik GoenkaNo ratings yet
- Grinfeldstrang-Eigenvalues On PolygonsDocument15 pagesGrinfeldstrang-Eigenvalues On Polygonslogsdad291No ratings yet
- Markov Chains and Markov Chain Monte Carlo: Yee Whye Teh Department of Statistics Tas: Luke Kelly, Lloyd ElliottDocument93 pagesMarkov Chains and Markov Chain Monte Carlo: Yee Whye Teh Department of Statistics Tas: Luke Kelly, Lloyd ElliottBetoNo ratings yet
- MorphDocument20 pagesMorphYosueNo ratings yet
- Aspects of Certified Randomness From Quantum Supremacy: Scott Aaronson (UT Austin)Document22 pagesAspects of Certified Randomness From Quantum Supremacy: Scott Aaronson (UT Austin)JerimiahNo ratings yet
- Eeng415 Power System Reliability Introduction To StochasticprocessDocument75 pagesEeng415 Power System Reliability Introduction To Stochasticprocessk xcd9No ratings yet
- CSE291D Lecture 6: Monte Carlo Methods 2: Markov Chain Monte CarloDocument66 pagesCSE291D Lecture 6: Monte Carlo Methods 2: Markov Chain Monte CarloballechaseNo ratings yet
- Chapter1 - Queuing TheoryDocument67 pagesChapter1 - Queuing TheorybobNo ratings yet
- Som 5Document42 pagesSom 5Muhamed zameelNo ratings yet
- EEET2465 Lecture 5 Introduction To Digital CommunicationsDocument75 pagesEEET2465 Lecture 5 Introduction To Digital CommunicationsKenny MakNo ratings yet
- Advanced Molecular Dynamics: Sampling May 8, 2019Document25 pagesAdvanced Molecular Dynamics: Sampling May 8, 2019parultNo ratings yet
- Outline: - Error Correction Codes (Chapter 8) (Week 10 and 11)Document31 pagesOutline: - Error Correction Codes (Chapter 8) (Week 10 and 11)HarshaNo ratings yet
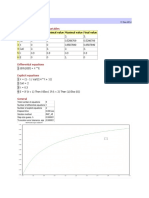
- Calculated Values of DEQ Variables: Variable Initial Value Minimal Value Maximal Value Final ValueDocument1 pageCalculated Values of DEQ Variables: Variable Initial Value Minimal Value Maximal Value Final ValueCer No RusNo ratings yet
- CHEM 440/740: Introduction To Quantum Information and Quantum Control in Physical SystemsDocument43 pagesCHEM 440/740: Introduction To Quantum Information and Quantum Control in Physical Systemsmakumba1972No ratings yet
- Generate States of MCDocument2 pagesGenerate States of MCgacixa8674No ratings yet
- System Modeling Using Markov Chain and Matlab PDFDocument20 pagesSystem Modeling Using Markov Chain and Matlab PDFNazer HdaifehNo ratings yet
- Process Modeling Lecture 6Document51 pagesProcess Modeling Lecture 6Muddys007No ratings yet
- Hidden Markov ModelDocument32 pagesHidden Markov ModelAnubhab BanerjeeNo ratings yet
- Pattern Recognition and Machine Learning: Fuzzy Sets in Pattern Recognition Debrup Chakraborty CinvestavDocument15 pagesPattern Recognition and Machine Learning: Fuzzy Sets in Pattern Recognition Debrup Chakraborty CinvestavAvishek ChandraNo ratings yet
- Introduction To Machine Learning CMU-10701: Hidden Markov ModelsDocument30 pagesIntroduction To Machine Learning CMU-10701: Hidden Markov Modelsricksant2003No ratings yet
- Hidden Markov ModelssDocument59 pagesHidden Markov ModelssAna MariaNo ratings yet
- Hidden Markov ModelDocument36 pagesHidden Markov ModelMıghty ItaumaNo ratings yet
- Sikagrout Cable PTDocument3 pagesSikagrout Cable PTYASHICA VAITTIANATHANNo ratings yet
- Semi-Detailed Lesson Plan Tle 6 (Industrial Arts) Fourth QuarterDocument3 pagesSemi-Detailed Lesson Plan Tle 6 (Industrial Arts) Fourth QuarterEiram Williams78% (9)
- How The Internet Hunted Down An "Anonymous" Employee, Using His Own PhotoDocument5 pagesHow The Internet Hunted Down An "Anonymous" Employee, Using His Own PhotoMarian DavidoaiaNo ratings yet
- TF in SAPDocument21 pagesTF in SAPChandan MukherjeeNo ratings yet
- Project Management: To AccompanyDocument66 pagesProject Management: To AccompanyRazel TercinoNo ratings yet
- Social Media Marketing - AssignmentDocument8 pagesSocial Media Marketing - AssignmentAllen RodaNo ratings yet
- PathaoDocument9 pagesPathaoAfia Azad Hridita 2111622630No ratings yet
- Perspective Drawing Perspective Drawing: What Is This Type of Drawing Called?Document17 pagesPerspective Drawing Perspective Drawing: What Is This Type of Drawing Called?Rommel Lazaro100% (1)
- Classroom: Solutions GuideDocument15 pagesClassroom: Solutions GuideMaaeglobal ResourcesNo ratings yet
- Pelton Turbine ExperimentDocument6 pagesPelton Turbine ExperimentvedNo ratings yet
- Charger Test Report: Electrical TestsDocument2 pagesCharger Test Report: Electrical TestshadiNo ratings yet
- Oriss Quartz Kitchen Sink Price ListDocument4 pagesOriss Quartz Kitchen Sink Price ListamitNo ratings yet
- Refsheet 2nd Namhae Bridge CH enDocument1 pageRefsheet 2nd Namhae Bridge CH en王小波No ratings yet
- GE OEC Elite User manualDocument4 pagesGE OEC Elite User manualjhsinNo ratings yet
- BP 344 Toilets and Baths g1 ReportDocument24 pagesBP 344 Toilets and Baths g1 ReportCrispin NasamNo ratings yet
- 5111 Deutz-Fahr - Serie 5 e Serie 5 TTV - Nd-Ba 2Document24 pages5111 Deutz-Fahr - Serie 5 e Serie 5 TTV - Nd-Ba 2Oleg KuryanNo ratings yet
- Manual Diesel Test BenchDocument18 pagesManual Diesel Test BenchMelchor EstradaNo ratings yet
- UnimecDocument43 pagesUnimecayavuzbvsNo ratings yet
- Hino-ePc System Operating Manual PDFDocument124 pagesHino-ePc System Operating Manual PDFVerónica Maila FigueroaNo ratings yet
- Oxo AQA16 P101 pr01 XxaannDocument6 pagesOxo AQA16 P101 pr01 XxaannAlenNo ratings yet
- 05 Jan 2015guidelines For Manufacturing Quality Fly Ash BricksDocument11 pages05 Jan 2015guidelines For Manufacturing Quality Fly Ash BricksJoy Prokash RoyNo ratings yet
- Technical Detail - EHRW + SHRWDocument10 pagesTechnical Detail - EHRW + SHRWBalaji JenarthananNo ratings yet
- PostScript SDK v2 - PssdkdsDocument2 pagesPostScript SDK v2 - PssdkdsSándor NagyNo ratings yet
- Yabai Toggle WindowDocument3 pagesYabai Toggle WindowBinay BudhathokiNo ratings yet
- Too Many Cooks: Bayesian Inference For Coordinating Multi-Agent CollaborationDocument19 pagesToo Many Cooks: Bayesian Inference For Coordinating Multi-Agent CollaborationJocesesNo ratings yet
- Govt. Acctg. CO 2020-2021Document5 pagesGovt. Acctg. CO 2020-2021leyn sanburgNo ratings yet
- OKI 5112 PartsDocument22 pagesOKI 5112 PartsMarcelo Shimatai de MedioNo ratings yet