You might also like
- Biological Data and Database Biological DataDocument10 pagesBiological Data and Database Biological Databiochem moocNo ratings yet
- Biological Databases GuideDocument31 pagesBiological Databases GuideSir RutherfordNo ratings yet
- Bioinformatics: The Application of Computational Tools to Biological DataDocument26 pagesBioinformatics: The Application of Computational Tools to Biological DataSunaina RNo ratings yet
- Biological DatabaseDocument19 pagesBiological DatabaseMahesh Yadav100% (8)
- Databases - FinalDocument50 pagesDatabases - FinalAbhi SachdevNo ratings yet
- Lec2 DatabasesDocument135 pagesLec2 DatabasesDeepali SinghNo ratings yet
- Bioinformatics. CH 3 Databases (Summarized Notes)Document5 pagesBioinformatics. CH 3 Databases (Summarized Notes)Trinity HarborNo ratings yet
- FALLSEM2019-20 BIT2001 ETH VL2019201000690 Reference Material I 11-Jul-2019 Unit I NewDocument48 pagesFALLSEM2019-20 BIT2001 ETH VL2019201000690 Reference Material I 11-Jul-2019 Unit I NewkumarklNo ratings yet
- Introduction to Biological DatabasesDocument13 pagesIntroduction to Biological DatabasesSham BabuNo ratings yet
- Biological DatabasesDocument13 pagesBiological DatabasesKeerthyGaneshNo ratings yet
- Databases BioinformaticsDocument42 pagesDatabases BioinformaticsSukhdeep SinghNo ratings yet
- Lecture-5-Information-retrieval-from-databasesDocument22 pagesLecture-5-Information-retrieval-from-databasesVeer khadeNo ratings yet
- Data Base in BioinformaticsDocument30 pagesData Base in BioinformaticsGanesh V GaonkarNo ratings yet
- NCBI, EMBL, DDBJ and Entrez: Major Biological DatabasesDocument28 pagesNCBI, EMBL, DDBJ and Entrez: Major Biological DatabasesNandni JhaNo ratings yet
- Database: Formats and FunctionsDocument103 pagesDatabase: Formats and FunctionsSuraj VermaNo ratings yet
- Biological Databases: Structured Collections of Life Science DataDocument47 pagesBiological Databases: Structured Collections of Life Science DataMutsawashe MunetsiNo ratings yet
- Biological Database 1Document50 pagesBiological Database 1Muhammad uzairNo ratings yet
- Bioinformatics Database and ApplicationsDocument82 pagesBioinformatics Database and ApplicationsRekha Singh100% (2)
- Exp 1Document7 pagesExp 1Ishan KumarNo ratings yet
- NcbiDocument25 pagesNcbiPakistan ZindaabdaNo ratings yet
- CSC 224 Introduction To Computational Biology: Module Two - Biological Databases & Resources Dr. Isewon I. MDocument25 pagesCSC 224 Introduction To Computational Biology: Module Two - Biological Databases & Resources Dr. Isewon I. MKofi AkporNo ratings yet
- ManualDocument68 pagesManualGANESHAN SNo ratings yet
- BIOINFORMATICS - eNOTESDocument23 pagesBIOINFORMATICS - eNOTESRaja Durai RNo ratings yet
- CR MicroDocument2 pagesCR Microankitraj318No ratings yet
- Database IIDocument16 pagesDatabase IIRoshan PoudelNo ratings yet
- Biological DatabaseDocument8 pagesBiological DatabasePRASHANT SOLANKINo ratings yet
- Rese RachDocument37 pagesRese RachpmtallyNo ratings yet
- The EMBL Nucleotide Sequence DatabaseDocument5 pagesThe EMBL Nucleotide Sequence DatabaseJorge Luis ParraNo ratings yet
- Generating Structural Data AnalysisDocument8 pagesGenerating Structural Data AnalysisTejinder SinghNo ratings yet
- Unit IDocument28 pagesUnit IDr. R. K. Selvakesavan PSGRKCWNo ratings yet
- Lecture 2 Introduction To The Computational ToolsDocument15 pagesLecture 2 Introduction To The Computational ToolsBhawna RathiNo ratings yet
- DNA and Protein Databases for Molecular BiologyDocument31 pagesDNA and Protein Databases for Molecular Biologyaditya.2352700No ratings yet
- Introduction To Ncbi, Types of Databases: by Dhatrika Kavya Roll No-20211A0573Document12 pagesIntroduction To Ncbi, Types of Databases: by Dhatrika Kavya Roll No-20211A0573KAVYA DHATRIKANo ratings yet
- Database Resources of The National Center For Biotechnology InformationDocument8 pagesDatabase Resources of The National Center For Biotechnology InformationMarwa GamalNo ratings yet
- #1 L1 BioDatabasesDocument89 pages#1 L1 BioDatabasesersamaylaNo ratings yet
- Bioinformatics Tools For Nucleotide Sequence Analysis and Database ExplorationDocument75 pagesBioinformatics Tools For Nucleotide Sequence Analysis and Database Explorationvarijnayan1No ratings yet
- Bioinformatics and Omics Topic: Database and Biological Database With Examples Assignment-3Document5 pagesBioinformatics and Omics Topic: Database and Biological Database With Examples Assignment-3vidushi srivastavaNo ratings yet
- Bioinformatics: Nadiya Akmal Binti Baharum (PHD)Document54 pagesBioinformatics: Nadiya Akmal Binti Baharum (PHD)Nur RazinahNo ratings yet
- Introduction to Bioinformatics Databases and ToolsDocument34 pagesIntroduction to Bioinformatics Databases and ToolsSaqlain Ali ShahNo ratings yet
- Introduction To DatabasesDocument7 pagesIntroduction To Databasesjonny deppNo ratings yet
- Biological DatabasesDocument28 pagesBiological DatabasesMoiz Ahmed BhattiNo ratings yet
- Lecture 2Document28 pagesLecture 2Salix MattNo ratings yet
- Bioinformatics: Intended Learning OutcomesDocument9 pagesBioinformatics: Intended Learning OutcomesPerl CortesNo ratings yet
- Basics of Bioinformatics in Biological ResearchDocument5 pagesBasics of Bioinformatics in Biological ResearchVisakan .KNo ratings yet
- NT Seq DatabaseDocument4 pagesNT Seq DatabaseDevinder KaurNo ratings yet
- ECNaga - BIOINFORMATICS - WRITTEN REPORTDocument10 pagesECNaga - BIOINFORMATICS - WRITTEN REPORTEileen NagaNo ratings yet
- Bioinformatics OverviewDocument18 pagesBioinformatics OverviewBrijesh Singh YadavNo ratings yet
- Bio in For Ma TicsDocument52 pagesBio in For Ma TicsSwapnesh SinghNo ratings yet
- National Center For Biotechnology InformationDocument4 pagesNational Center For Biotechnology Informationmcdonald212No ratings yet
- 1 - Introduction and Sequence DatabaseDocument51 pages1 - Introduction and Sequence DatabaseAlishaNo ratings yet
- Biological Databases GenbankDocument31 pagesBiological Databases GenbankjaineemNo ratings yet
- Introduction To Bioinformatics (Databases)Document28 pagesIntroduction To Bioinformatics (Databases)Shanu ShahNo ratings yet
- Day 1Document38 pagesDay 1Farsana PsNo ratings yet
- GKX 1095Document6 pagesGKX 1095jonny deppNo ratings yet
- Resumen Unidad 1 y 2 BioinformaticaDocument14 pagesResumen Unidad 1 y 2 BioinformaticaPaulette GuerreroNo ratings yet
- Bioinformatics Databases - An IntroductionDocument10 pagesBioinformatics Databases - An IntroductionVarshika SinghNo ratings yet
- Ahmed Saad Qatea / 4 StageDocument10 pagesAhmed Saad Qatea / 4 Stageاحمد سعد كاطعNo ratings yet
- Data Retrival SystemsDocument3 pagesData Retrival SystemsShubham PawadeNo ratings yet
- Lab 1Document39 pagesLab 1Nurul AzeraNo ratings yet
- Bioinformatics for Beginners: Genes, Genomes, Molecular Evolution, Databases and Analytical ToolsFrom EverandBioinformatics for Beginners: Genes, Genomes, Molecular Evolution, Databases and Analytical ToolsRating: 4.5 out of 5 stars4.5/5 (3)
- Grest LAMMPS 2011 PDFDocument21 pagesGrest LAMMPS 2011 PDFstevekct10No ratings yet
- Bioconductor Case Studies - TOCDocument5 pagesBioconductor Case Studies - TOCstevekct10No ratings yet
- UntitledDocument2 pagesUntitledstevekct10No ratings yet
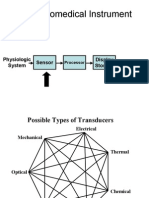
- Basic Biomedical Instrument: Sensor Display Storage Physiologic System ObserverDocument29 pagesBasic Biomedical Instrument: Sensor Display Storage Physiologic System Observerstevekct10No ratings yet
- UntitledDocument1 pageUntitledstevekct10No ratings yet
- How To Make AspirinDocument7 pagesHow To Make Aspirinafzal4u100% (8)
- Drain Mats: and MoreDocument4 pagesDrain Mats: and Morestevekct10No ratings yet
- De Guzman OE - 4Document3 pagesDe Guzman OE - 4Jericson De GuzmanNo ratings yet
- BIOPROCESSDocument814 pagesBIOPROCESSSumedha sNo ratings yet
- Molecular DiagnosticsDocument583 pagesMolecular DiagnosticsAnthony93% (14)
- All Quiz Questions Quiz - 02Document9 pagesAll Quiz Questions Quiz - 02Shahadath HossenNo ratings yet
- Lacto Globulin ADocument49 pagesLacto Globulin AJonas cardosoNo ratings yet
- Trilobata Exhibits Molecular Impediment On TheDocument10 pagesTrilobata Exhibits Molecular Impediment On TheInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Biology - Classification of Organisms - TutorialspointDocument3 pagesBiology - Classification of Organisms - TutorialspointRana EsharibNo ratings yet
- Genetic Diversity Wild Almonds PDFDocument21 pagesGenetic Diversity Wild Almonds PDFCarles JiménezNo ratings yet
- Tristan Scott - BIOL-1408-46440 - LAB 04 Microscopy and The Cell - MaymesterDocument9 pagesTristan Scott - BIOL-1408-46440 - LAB 04 Microscopy and The Cell - MaymesterTristan ScottNo ratings yet
- 12 Bio CH 24 MCQsDocument19 pages12 Bio CH 24 MCQsAhmad NawazNo ratings yet
- Tutorial - Shane's Simple Guide To F-StatisticsDocument21 pagesTutorial - Shane's Simple Guide To F-StatisticsKS VelArcNo ratings yet
- Grade 10 Science Learning PlanDocument12 pagesGrade 10 Science Learning PlanMaricar Feb Maturan100% (1)
- Trans - Patten's Foundations of Embryology Chapters 1-7Document21 pagesTrans - Patten's Foundations of Embryology Chapters 1-7Lorenzo Daniel Antonio0% (1)
- Artificial intelligence approach in building automated diagnostics venipuncture blood analysis machineDocument14 pagesArtificial intelligence approach in building automated diagnostics venipuncture blood analysis machineKIPNGENO EMMANUELNo ratings yet
- Ajanta 48 PDFDocument8 pagesAjanta 48 PDFRohitDalalNo ratings yet
- The Journey of Man A Genetic OdysseyDocument7 pagesThe Journey of Man A Genetic OdysseylpinargotiNo ratings yet
- Chapter 27: Basic Genetics - Multiple-Choice QuestionsDocument37 pagesChapter 27: Basic Genetics - Multiple-Choice Questionsjoeylamch126No ratings yet
- Network Pharmacology and TCM - Alternative MedicineDocument23 pagesNetwork Pharmacology and TCM - Alternative MedicineyayanicaNo ratings yet
- Science 7 Unit 5 Study GuideDocument15 pagesScience 7 Unit 5 Study GuideMae RicañaNo ratings yet
- 2.1. Genetics and ReproductionDocument34 pages2.1. Genetics and ReproductionChristian Ramos NievesNo ratings yet
- BIOLOGICAL CLASSIFICATIONDocument4 pagesBIOLOGICAL CLASSIFICATIONVishalNo ratings yet
- Chemical Weapons Haber Life PDFDocument60 pagesChemical Weapons Haber Life PDFtatianaNo ratings yet
- IGCSE Biology Section 3 Lesson 5Document29 pagesIGCSE Biology Section 3 Lesson 5mosneagu.anaNo ratings yet
- Tuesday, August 1Document43 pagesTuesday, August 11B DEGOMA JAYD ANDREI A.No ratings yet
- NEET Biology Chapter Wise Mock Test - Biological Classification - CBSE TutsDocument17 pagesNEET Biology Chapter Wise Mock Test - Biological Classification - CBSE Tutssreenandhan 2017No ratings yet
- Readings For Week 4 General BiologyDocument39 pagesReadings For Week 4 General BiologyKym DacudaoNo ratings yet
- Chapter 18 AP Bio Study GuideDocument6 pagesChapter 18 AP Bio Study GuideHolly SullivanNo ratings yet
- GF Master DocumentDocument330 pagesGF Master DocumentShmuel RosenthalNo ratings yet
- Lecture 1 - Basics of BiotechnologyDocument54 pagesLecture 1 - Basics of BiotechnologyShretima AgrawalNo ratings yet
- Kehr CV Summer 2022 No AddressDocument7 pagesKehr CV Summer 2022 No Addressapi-637076493No ratings yet