You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5808)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (843)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (346)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- 1 PRISM Basic Guide v4Document59 pages1 PRISM Basic Guide v4Maria Rolenza PaladoNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Abs HaldexDocument2 pagesAbs HaldexBom_Jovi_681No ratings yet
- Ejemplos de Ensayos de Discurso PersuasivoDocument6 pagesEjemplos de Ensayos de Discurso Persuasivoz0s1nusef0l3100% (2)
- Pass Microsoft 70-741 Exam With 100% Guarantee: Networking With Windows Server 2016Document34 pagesPass Microsoft 70-741 Exam With 100% Guarantee: Networking With Windows Server 2016lucasNo ratings yet
- HCSCA112 Dual-System Hot StandbyDocument31 pagesHCSCA112 Dual-System Hot Standbymangla\No ratings yet
- 577013-614 Veeder-Root Dispenser Interface Module (DIM) For TLS-350R Systems Installation ManualDocument24 pages577013-614 Veeder-Root Dispenser Interface Module (DIM) For TLS-350R Systems Installation Manualjose moralesNo ratings yet
- Controler Thermoflow TP4Document5 pagesControler Thermoflow TP4Paulo CostaNo ratings yet
- NAV2013 01 Reporting PDFDocument82 pagesNAV2013 01 Reporting PDFMiguel De Dios SinovasNo ratings yet
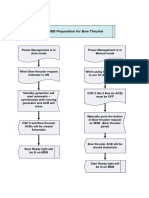
- Bow Thruster Starting ProcedureDocument2 pagesBow Thruster Starting ProcedureThe CapitalNo ratings yet
- Service Notes: Issued by RJADocument15 pagesService Notes: Issued by RJAcarlosNo ratings yet
- STEM in TVET Learning Design FrameworkDocument61 pagesSTEM in TVET Learning Design Frameworkprofjay2023No ratings yet
- Deploying The AlienVault HIDS Agents in AlienVault USM v5Document5 pagesDeploying The AlienVault HIDS Agents in AlienVault USM v5trollcapoeiraNo ratings yet
- App Inventor Cheat SheetDocument9 pagesApp Inventor Cheat SheetNAIR KRISHNA RAVEENDRANNo ratings yet
- Performance Tuning Addedinfo OracleDocument49 pagesPerformance Tuning Addedinfo OraclesridkasNo ratings yet
- FreeBitcoin Script Roll 10000Document4 pagesFreeBitcoin Script Roll 10000shakilanepaliNo ratings yet
- Prog5 ModuleDocument268 pagesProg5 ModuleNica Marie LumbaNo ratings yet
- Temperature Sensor With Buffer-Chain Based Time-To-Digital Converter For Ultralow Voltage OperationDocument14 pagesTemperature Sensor With Buffer-Chain Based Time-To-Digital Converter For Ultralow Voltage OperationJames MorenoNo ratings yet
- Ada4522 1 - 4522 2 - 4522 4Document32 pagesAda4522 1 - 4522 2 - 4522 4Saad AbdullahNo ratings yet
- Proposed Revisions and Addendum On Students' HandbookDocument9 pagesProposed Revisions and Addendum On Students' HandbookHarry Lord M. BolinaNo ratings yet
- Module 3: Hardware-Software Synchronization: Mazen A. R. SaghirDocument50 pagesModule 3: Hardware-Software Synchronization: Mazen A. R. SaghirYehya El hassanNo ratings yet
- TP4000ZC Serial ProtocolDocument2 pagesTP4000ZC Serial ProtocolBluff Flers100% (2)
- TruVista CPNI Cert StatementDocument3 pagesTruVista CPNI Cert StatementFederal Communications Commission (FCC)No ratings yet
- 02 OHC508203 USCDB Principle With Operation and Maintenance (VHSS)Document104 pages02 OHC508203 USCDB Principle With Operation and Maintenance (VHSS)rolandomhNo ratings yet
- Cellular Networks - Positioning Performance Analysis ReliabilityDocument416 pagesCellular Networks - Positioning Performance Analysis Reliabilitystranger_1No ratings yet
- 1982 BMW E528 Electrical Troubleshooting Manual PDFDocument77 pages1982 BMW E528 Electrical Troubleshooting Manual PDFwilderNo ratings yet
- Pumping PDFDocument3 pagesPumping PDFAmit KumarNo ratings yet
- Nokia 9500mpr Mss Indoor PDFDocument2 pagesNokia 9500mpr Mss Indoor PDFMED MOHNo ratings yet
- HDFC Ergo SME HandbookDocument56 pagesHDFC Ergo SME HandbookThe LoanWalaNo ratings yet
- The History of Project ManagementDocument9 pagesThe History of Project ManagementFabio Nelson Rodriguez DiazNo ratings yet
- SYNOPSIS (HOTEL MANAGEMENT SYSTEM Project) 1Document14 pagesSYNOPSIS (HOTEL MANAGEMENT SYSTEM Project) 1Sagar ChakrabartyNo ratings yet