You might also like
- WAN TECHNOLOGY FRAME-RELAY: An Expert's Handbook of Navigating Frame Relay NetworksFrom EverandWAN TECHNOLOGY FRAME-RELAY: An Expert's Handbook of Navigating Frame Relay NetworksNo ratings yet
- Configuration of a Simple Samba File Server, Quota and Schedule BackupFrom EverandConfiguration of a Simple Samba File Server, Quota and Schedule BackupNo ratings yet
- Upgrade SRX With ISSU (All KB in One GO)Document8 pagesUpgrade SRX With ISSU (All KB in One GO)Asif Hamidul HaqueNo ratings yet
- VNX How To Remote Power On Off A DiskDocument2 pagesVNX How To Remote Power On Off A DiskemcviltNo ratings yet
- Netapp-How To Rescan and Recover LUN Paths in A Host After Modifying SLM Reporting NodesDocument45 pagesNetapp-How To Rescan and Recover LUN Paths in A Host After Modifying SLM Reporting NodeschengabNo ratings yet
- Juniper Networks - How To Run Packet Profiling On Firewall To Determine Cause of HighDocument2 pagesJuniper Networks - How To Run Packet Profiling On Firewall To Determine Cause of HighZhuzhu ZhuNo ratings yet
- Dial Home HandbookDocument20 pagesDial Home HandbookVasu PogulaNo ratings yet
- Emc 257758Document7 pagesEmc 257758Bahman MirNo ratings yet
- Network Appliance - Actualtests.ns0 155.v2014!03!03.by - Brown.189qDocument81 pagesNetwork Appliance - Actualtests.ns0 155.v2014!03!03.by - Brown.189qjency_storageNo ratings yet
- EMC-CX Tips 2Document3 pagesEMC-CX Tips 2liuylNo ratings yet
- MB - V Fas6000 Sa600 C 013Document20 pagesMB - V Fas6000 Sa600 C 013Feston_FNo ratings yet
- SVA Excercise 1Document9 pagesSVA Excercise 1sujaataNo ratings yet
- CLI in Eng ModeDocument13 pagesCLI in Eng ModeSumanta MaitiNo ratings yet
- Ans:-There Is No Direct Answer For This Question But We Shall Do It in Several WayDocument26 pagesAns:-There Is No Direct Answer For This Question But We Shall Do It in Several WayWilliam SmithNo ratings yet
- Dialhome AlertsDocument5 pagesDialhome AlertsSunil GarnayakNo ratings yet
- Factory InstallDocument2 pagesFactory InstallPravesh UpadhyayNo ratings yet
- Configure Lan Monitor: HP APA Provides The FollowingDocument32 pagesConfigure Lan Monitor: HP APA Provides The FollowingajeetaryaNo ratings yet
- TimeFinder From EMCDocument4 pagesTimeFinder From EMCNaseer MohammedNo ratings yet
- P1-P2 H I: Revision HistoryDocument18 pagesP1-P2 H I: Revision HistoryBiplab ParidaNo ratings yet
- Dial Home Handbook-1 PDFDocument20 pagesDial Home Handbook-1 PDFSunil GarnayakNo ratings yet
- Configuring Transparent Web Proxy Using Squid 2Document4 pagesConfiguring Transparent Web Proxy Using Squid 2agunggumilarNo ratings yet
- A Redundant LoadDocument7 pagesA Redundant LoadMohd Iskandar OmarNo ratings yet
- IPL1A RC35 Mechid ArtifactsDocument47 pagesIPL1A RC35 Mechid Artifactsdurga selvaNo ratings yet
- ActionPlan HA Update 2015 V1.3Document19 pagesActionPlan HA Update 2015 V1.3Shailesh RansingNo ratings yet
- Migration Proces EMC To HDSDocument6 pagesMigration Proces EMC To HDSPrasadValluraNo ratings yet
- BSS L1 TroubleshootingDocument39 pagesBSS L1 TroubleshootingVinay Bhardwaj100% (1)
- EMC VNX DataDocument21 pagesEMC VNX Datapadhiary jagannathNo ratings yet
- TimeFinder & SRDF Operations SOPDocument12 pagesTimeFinder & SRDF Operations SOPPeter KidiavaiNo ratings yet
- Procedure For Installing VXVM and Vxfs Patches in Sfrac: Stopping OracleDocument3 pagesProcedure For Installing VXVM and Vxfs Patches in Sfrac: Stopping Oracleakkati123No ratings yet
- Manual Tests PADocument41 pagesManual Tests PAJAMESJANUSGENIUS5678No ratings yet
- Manual Multi-Node Patching of Grid Infrastructure and Rac DB Environment Using OpatchautoDocument7 pagesManual Multi-Node Patching of Grid Infrastructure and Rac DB Environment Using OpatchautoAriel Pacheco RinconNo ratings yet
- HPUX by ShrikantDocument21 pagesHPUX by ShrikantmanmohanmirkarNo ratings yet
- Linux+Recommended+Settings-Multipathing-IO BalanceDocument11 pagesLinux+Recommended+Settings-Multipathing-IO BalanceMeganathan RamanathanNo ratings yet
- Test /acceptance Criteria (TAC) For Implementation (Was EIP-2)Document8 pagesTest /acceptance Criteria (TAC) For Implementation (Was EIP-2)liew99No ratings yet
- Boot - Device AFF - A150 ASA - A150 AFF - C190 AFF - A220 ASA - AFF A220 - FAS2720 50 Ev20 024aDocument19 pagesBoot - Device AFF - A150 ASA - A150 AFF - C190 AFF - A220 ASA - AFF A220 - FAS2720 50 Ev20 024anaret.seaNo ratings yet
- NS0 155Document110 pagesNS0 155ringoletNo ratings yet
- HACMP Storage Migration ProcedureDocument5 pagesHACMP Storage Migration Procedureraja rajanNo ratings yet
- RSP Troubleshooting GuideDocument11 pagesRSP Troubleshooting Guidenitesh dayamaNo ratings yet
- Allocating, Unallocating Storage On A EMC SANDocument5 pagesAllocating, Unallocating Storage On A EMC SANSrinivas KumarNo ratings yet
- MB FAS8040 60 80 C Ev20 050Document19 pagesMB FAS8040 60 80 C Ev20 050nixdorfNo ratings yet
- Backup Cluster Configuration: Task Details Commands DescriptionDocument4 pagesBackup Cluster Configuration: Task Details Commands Descriptionik reddyNo ratings yet
- APG 40 ChangeDocument16 pagesAPG 40 ChangerajNo ratings yet
- Features Supported: Inventory Details Logical Details Monitors Report DetailsDocument3 pagesFeatures Supported: Inventory Details Logical Details Monitors Report DetailsbrpindiaNo ratings yet
- Diplomado CCNPDocument172 pagesDiplomado CCNPalexis pedrozaNo ratings yet
- Netbackup Key PointsDocument10 pagesNetbackup Key PointsSahil AnejaNo ratings yet
- Isilon Cluster ShutdownDocument12 pagesIsilon Cluster ShutdownAmit KumarNo ratings yet
- HPUX MCSG MigHPUX MCSG Migrage Storage From Netapp 3240 To 3270Document4 pagesHPUX MCSG MigHPUX MCSG Migrage Storage From Netapp 3240 To 3270Mq SfsNo ratings yet
- VCS NotesDocument7 pagesVCS Notesmail2cibyNo ratings yet
- Cpu Bottle Neck Issues NetappDocument10 pagesCpu Bottle Neck Issues NetappSrikanth MuthyalaNo ratings yet
- RAC Backup and Recovery Using RMANDocument7 pagesRAC Backup and Recovery Using RMANpentiumonceNo ratings yet
- SCM CONS LC RunbookDocument61 pagesSCM CONS LC Runbookviniec116No ratings yet
- Template Configuration For MA5600Document12 pagesTemplate Configuration For MA5600Hai LuongNo ratings yet
- Hellcat Pilot InstructionsDocument22 pagesHellcat Pilot InstructionsRefugio Hernandez ArceNo ratings yet
- File: /Home/Vissistl/Desktop/Interview-New/Linux - Inter Page 1 of 3Document3 pagesFile: /Home/Vissistl/Desktop/Interview-New/Linux - Inter Page 1 of 3Sistla567No ratings yet
- Configuring Ipv6 Acls: Lab TopologyDocument3 pagesConfiguring Ipv6 Acls: Lab TopologyAye KyawNo ratings yet
- Acro Whoop FC ManualDocument12 pagesAcro Whoop FC ManualChristopher HudginsNo ratings yet
- Lab Exercise 9: Configuring Host Access To Clariion Luns - LinuxDocument9 pagesLab Exercise 9: Configuring Host Access To Clariion Luns - LinuxrasoolvaliskNo ratings yet
- Setup PT Cluster No deDocument19 pagesSetup PT Cluster No deliew99No ratings yet
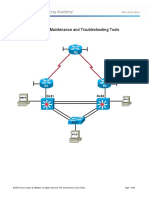
- CCNPv7 TSHOOT Lab3 1 Assembling Maintenance and Troubleshooting Tools StudentDocument45 pagesCCNPv7 TSHOOT Lab3 1 Assembling Maintenance and Troubleshooting Tools StudentThomas Schougaard TherkildsenNo ratings yet
- Networker Command Line ExamplesDocument6 pagesNetworker Command Line ExamplesShefali MishraNo ratings yet
- CTA - Containers Explained v1Document25 pagesCTA - Containers Explained v1liew99No ratings yet
- Floor Load RequirementsDocument4 pagesFloor Load Requirementsliew99No ratings yet
- How To Access SPP On KCDocument1 pageHow To Access SPP On KCliew99No ratings yet
- Install/Upgrade Array Health Analyzer: Inaha010 - R001Document2 pagesInstall/Upgrade Array Health Analyzer: Inaha010 - R001liew99No ratings yet
- NSD TuningDocument6 pagesNSD Tuningliew99No ratings yet
- Pacemaker CookbookDocument4 pagesPacemaker Cookbookliew99No ratings yet
- SONAS Security Strategy - SecurityDocument38 pagesSONAS Security Strategy - Securityliew99No ratings yet
- Update Software On A CX300 series/CX500 series/CX700/CX3 Series ArrayDocument13 pagesUpdate Software On A CX300 series/CX500 series/CX700/CX3 Series Arrayliew99No ratings yet
- Cable Cx600 Sps To Switch Ports and Check ConnectionsDocument1 pageCable Cx600 Sps To Switch Ports and Check Connectionsliew99No ratings yet
- Configure Distributed Monitor Email-Home Webex Remote AccessDocument6 pagesConfigure Distributed Monitor Email-Home Webex Remote Accessliew99No ratings yet
- Cable CX3-20-Series Data Ports To Switch Ports: cnspr160 - R002Document1 pageCable CX3-20-Series Data Ports To Switch Ports: cnspr160 - R002liew99No ratings yet
- Cable CX3-10c Data Ports To Switch Ports: cnspr170 - R001Document1 pageCable CX3-10c Data Ports To Switch Ports: cnspr170 - R001liew99No ratings yet
- Post Hardware/Software Upgrade Procedure: Collecting Clariion Storage System InformationDocument2 pagesPost Hardware/Software Upgrade Procedure: Collecting Clariion Storage System Informationliew99No ratings yet
- Cable The CX3-40-Series Array To The LAN: Cnlan160 - R006Document2 pagesCable The CX3-40-Series Array To The LAN: Cnlan160 - R006liew99No ratings yet
- Upndu 410Document5 pagesUpndu 410liew99No ratings yet
- Prepare CX300, 500, 700, and CX3 Series For Update To Release 24 and AboveDocument15 pagesPrepare CX300, 500, 700, and CX3 Series For Update To Release 24 and Aboveliew99No ratings yet
- Verify and Restore LUN OwnershipDocument1 pageVerify and Restore LUN Ownershipliew99No ratings yet
- Cable The CX3-80 Array To The LAN: Cnlan150 - R005Document2 pagesCable The CX3-80 Array To The LAN: Cnlan150 - R005liew99No ratings yet
- Cable The CX3-20-Series Array To The LAN: Storage System Serial Number (See Note Below)Document2 pagesCable The CX3-20-Series Array To The LAN: Storage System Serial Number (See Note Below)liew99No ratings yet
- Test /acceptance Criteria (TAC) For Implementation (Was EIP-2)Document8 pagesTest /acceptance Criteria (TAC) For Implementation (Was EIP-2)liew99No ratings yet
- Test and Acceptance Criteria (TAC) Procedure For Installation (Was EIP)Document3 pagesTest and Acceptance Criteria (TAC) Procedure For Installation (Was EIP)liew99No ratings yet
- and Install Software On The Service Laptop: cnhck010 - R006Document1 pageand Install Software On The Service Laptop: cnhck010 - R006liew99No ratings yet
- Hardware/software Upgrade Readiness CheckDocument2 pagesHardware/software Upgrade Readiness Checkliew99No ratings yet
- Disable Array From Calling Home: ImportantDocument2 pagesDisable Array From Calling Home: Importantliew99No ratings yet
- Verify You Have Reviewed The Latest Clariion Activity Guide (Cag)Document1 pageVerify You Have Reviewed The Latest Clariion Activity Guide (Cag)liew99No ratings yet
- Restore Array Call Home Monitoring: ImportantDocument2 pagesRestore Array Call Home Monitoring: Importantliew99No ratings yet
- An Introduction To Intrusion-Detection SystemsDocument19 pagesAn Introduction To Intrusion-Detection SystemsGeraud TchadaNo ratings yet
- CYS-501 - Lab-1Document20 pagesCYS-501 - Lab-1Zahida PerveenNo ratings yet
- Packet Sniffing: - by Aarti DhoneDocument13 pagesPacket Sniffing: - by Aarti Dhonejaveeed0401No ratings yet
- CUCM BK T863AF5C 00 Troubleshooting-Guide-Cucm-90 PDFDocument208 pagesCUCM BK T863AF5C 00 Troubleshooting-Guide-Cucm-90 PDFisamadinNo ratings yet
- DEF CON 24 Marc Newlin MouseJack Injecting Keystrokes Into Wireless Mice UPDATED - PDDocument86 pagesDEF CON 24 Marc Newlin MouseJack Injecting Keystrokes Into Wireless Mice UPDATED - PDWALDEKNo ratings yet
- Assignment6 PDFDocument14 pagesAssignment6 PDFBilalNo ratings yet
- How To Sniff Wireless Packets With WiresharkDocument3 pagesHow To Sniff Wireless Packets With WiresharkSudipta Das100% (1)
- SnifferDocument17 pagesSnifferRavi RavindraNo ratings yet
- T.4.1. QoS Measurement Methods and ToolsDocument26 pagesT.4.1. QoS Measurement Methods and ToolsEmina LučkinNo ratings yet
- Rsa NW 11.6.0.0 Release NotesDocument32 pagesRsa NW 11.6.0.0 Release NotesDiegoNo ratings yet
- Cain and AbelDocument3 pagesCain and AbelGrace RoselioNo ratings yet
- Week 7 Final - AssignmentDocument30 pagesWeek 7 Final - Assignmentapi-414181025No ratings yet
- Laboratory Experiment # 8: Don Bosco Technical College Information Technology DepartmentDocument9 pagesLaboratory Experiment # 8: Don Bosco Technical College Information Technology DepartmentDennis SinnedNo ratings yet
- FortiGate II 5-4-1 Student GuideDocument595 pagesFortiGate II 5-4-1 Student GuideDiego Suarez100% (3)
- Analisis Keamanan Jaringan Pada Fasilitas Internet (Wifi) Terhadap Serangan Packet SniffingDocument16 pagesAnalisis Keamanan Jaringan Pada Fasilitas Internet (Wifi) Terhadap Serangan Packet Sniffingcyber security 99100% (1)
- 49 WiresharkDocument8 pages49 Wiresharkalguacil2013No ratings yet
- Assignment# 01 Wireshark - IntroDocument7 pagesAssignment# 01 Wireshark - IntroAnimentalNo ratings yet
- Fortigate T.shootDocument4 pagesFortigate T.shootneoaltNo ratings yet
- Sniff Your Own Networks With TcpdumpDocument8 pagesSniff Your Own Networks With TcpdumpMahmood MustafaNo ratings yet
- CEH Module 10: SniffersDocument30 pagesCEH Module 10: SniffersAhmad Mahmoud0% (1)
- Siva Wlan Testing ResumeDocument3 pagesSiva Wlan Testing Resumemadhubaddapuri0% (1)
- Arbor APS STT - Unit 07 - Analyzing Packet Captures - 25jan2018 PDFDocument30 pagesArbor APS STT - Unit 07 - Analyzing Packet Captures - 25jan2018 PDFmasterlinh2008No ratings yet
- CLI Commands For Troubleshooting FortiGate FirewallsDocument6 pagesCLI Commands For Troubleshooting FortiGate Firewallschandrakant.raiNo ratings yet
- Lib P Cap Hakin 9 Luis Martin GarciaDocument9 pagesLib P Cap Hakin 9 Luis Martin Garciaf2zubacNo ratings yet
- Sniffing SpoofingDocument6 pagesSniffing SpoofingDeTRoyDNo ratings yet
- Practical 4 Wireshark EXTC 4Document8 pagesPractical 4 Wireshark EXTC 4Darshan AherNo ratings yet
- Principles of Information Security, Fifth EditionDocument55 pagesPrinciples of Information Security, Fifth EditionCharlito MikolliNo ratings yet
- Linux' Packet MmapDocument87 pagesLinux' Packet MmapsmallakeNo ratings yet
- Network LAB SheetDocument10 pagesNetwork LAB SheetDaya Ram BudhathokiNo ratings yet
- KPI Optimization Test Plan For LTEDocument42 pagesKPI Optimization Test Plan For LTEhuzaif zahoorNo ratings yet