You might also like
- Linear Regression Model with Gradient DescentDocument52 pagesLinear Regression Model with Gradient DescentshinjoNo ratings yet
- Lecture 3 aiDocument48 pagesLecture 3 aiEnes sağnakNo ratings yet
- Lecture 6,7-Linear RegressionDocument47 pagesLecture 6,7-Linear RegressionWaseem ShahzadNo ratings yet
- Week 04Document101 pagesWeek 04Osii CNo ratings yet
- Linear regression with one variableDocument21 pagesLinear regression with one variableauro auroNo ratings yet
- Linear Regression FundamentalsDocument116 pagesLinear Regression Fundamentalsmr robotNo ratings yet
- Applied Machine Learning: Multiple Linear RegressionDocument25 pagesApplied Machine Learning: Multiple Linear RegressionWanida KrataeNo ratings yet
- Machine Learning Week 3Document4 pagesMachine Learning Week 3AnandhsNo ratings yet
- Machine Learning and Data Mining: Prof. Alexander IhlerDocument46 pagesMachine Learning and Data Mining: Prof. Alexander IhleroriontherecluseNo ratings yet
- HW1Document4 pagesHW1sun_917443954No ratings yet
- AC-ED L03 - RegressionDocument83 pagesAC-ED L03 - RegressionAbel EspinNo ratings yet
- Sam HW2Document4 pagesSam HW2Ali HassanNo ratings yet
- 1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsDocument6 pages1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsJeremy WangNo ratings yet
- MM Algorithm Guide for Optimization ProblemsDocument40 pagesMM Algorithm Guide for Optimization Problemssanka csaatNo ratings yet
- Applied Machine Learning: One Variable (Simple) Linear RegressionDocument38 pagesApplied Machine Learning: One Variable (Simple) Linear RegressionWanida KrataeNo ratings yet
- ML Course Notes: Linear RegressionDocument10 pagesML Course Notes: Linear RegressioncopsamostoNo ratings yet
- Sample Research PaperDocument26 pagesSample Research Paperfb8ndyffmcNo ratings yet
- Chapter 3 Modeling of Physical SystemsDocument29 pagesChapter 3 Modeling of Physical Systemssaleh1978No ratings yet
- Machine Learning Lecture 4: Intuition Behind Derivatives, Linear Regression, and Finding Minima/MaximaDocument38 pagesMachine Learning Lecture 4: Intuition Behind Derivatives, Linear Regression, and Finding Minima/MaximaSaqlain ArshadNo ratings yet
- (Machine Learning Coursera) Lecture Note Week 1Document8 pages(Machine Learning Coursera) Lecture Note Week 1JonnyJackNo ratings yet
- Lecture 3-Linear-Regression-Part2Document45 pagesLecture 3-Linear-Regression-Part2Nada ShaabanNo ratings yet
- ML:Introduction: Week 1 Lecture NotesDocument8 pagesML:Introduction: Week 1 Lecture NotesAmanda GarciaNo ratings yet
- 3.3 Bias VarianceDocument14 pages3.3 Bias VarianceDavi Sousa e SilvaNo ratings yet
- 02 Linear RegressionDocument6 pages02 Linear RegressionMatixNo ratings yet
- CS229 Problem Set #1 Solutions: Supervised LearningDocument10 pagesCS229 Problem Set #1 Solutions: Supervised Learningsuhar adiNo ratings yet
- ML:Introduction: Week 1 Lecture NotesDocument10 pagesML:Introduction: Week 1 Lecture NotesShubhamNo ratings yet
- Optimization and Linear RegressionDocument61 pagesOptimization and Linear RegressionJose Ramon VillatuyaNo ratings yet
- 1 ModuleEcontent - Session5Document24 pages1 ModuleEcontent - Session5devesh vermaNo ratings yet
- Mat FungsiDocument36 pagesMat FungsimazayaNo ratings yet
- ML Week 4 To 10 PDFDocument146 pagesML Week 4 To 10 PDFdcs sfscollegeNo ratings yet
- DNN - M2 - Deep Feedforward NN 23decDocument97 pagesDNN - M2 - Deep Feedforward NN 23decManju Prasad NNo ratings yet
- L3 Linear Regression and Gradient DescentDocument46 pagesL3 Linear Regression and Gradient Descentjoseph karimNo ratings yet
- Linear regression with one variableDocument48 pagesLinear regression with one variableesteban1815No ratings yet
- CS221 - Artificial Intelligence - Machine Learning - 3 Linear ClassificationDocument28 pagesCS221 - Artificial Intelligence - Machine Learning - 3 Linear ClassificationArdiansyah Mochamad NugrahaNo ratings yet
- Lecture 2 - Supervised LearningDocument6 pagesLecture 2 - Supervised LearningEric WangNo ratings yet
- Week 3 NotesDocument10 pagesWeek 3 Notessandhiya sunainaNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- GM - W1-4 (Activity)Document11 pagesGM - W1-4 (Activity)Jhezza Mae Coraza TeroNo ratings yet
- Integer Programming: Wolfram WiesemannDocument62 pagesInteger Programming: Wolfram WiesemannVipul TiwariNo ratings yet
- Week 2 Introduction To Linear Models - Revised - v1Document54 pagesWeek 2 Introduction To Linear Models - Revised - v1Ahmad HammoudehNo ratings yet
- Department of Electrical Engineering School of Science and Engineering EE514/CS535 Machine Learning Homework 1Document11 pagesDepartment of Electrical Engineering School of Science and Engineering EE514/CS535 Machine Learning Homework 1Muhammad HusnainNo ratings yet
- MatlabDocument36 pagesMatlabMuhammmedNo ratings yet
- Introduction To Matlab: Doikon@Document26 pagesIntroduction To Matlab: Doikon@Milind RavindranathNo ratings yet
- Linear Regerssion With 1var Lecture2Document49 pagesLinear Regerssion With 1var Lecture26441 Abdul RehmanNo ratings yet
- Introduction To Machine Learning: Workshop On Machine Learning For Intelligent Image ProcessingDocument44 pagesIntroduction To Machine Learning: Workshop On Machine Learning For Intelligent Image ProcessingLekshmiNo ratings yet
- Machine Learning Model for House Price PredictionDocument80 pagesMachine Learning Model for House Price PredictionAbel EspinNo ratings yet
- AST Exam 2021 03 19Document9 pagesAST Exam 2021 03 19Rehman SaleemNo ratings yet
- ACT6100 A2020 Sup 12Document37 pagesACT6100 A2020 Sup 12lebesguesNo ratings yet
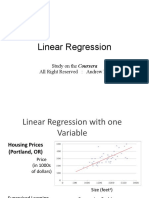
- Linear Regression: Study On The Coursera All Right Reserved: Andrew NGDocument29 pagesLinear Regression: Study On The Coursera All Right Reserved: Andrew NGRabbia KhalidNo ratings yet
- 41 DeepLearningDocument4 pages41 DeepLearningCaballero Alférez Roy TorresNo ratings yet
- Machine Learning in Action: Linear RegressionDocument47 pagesMachine Learning in Action: Linear RegressionRaushan Kashyap100% (1)
- Lecture LinearRegressionDocument42 pagesLecture LinearRegressionRaunak AsnaniNo ratings yet
- TechnicalReport CEC2017 FinalDocument17 pagesTechnicalReport CEC2017 Finalmohammed adnanNo ratings yet
- Linear RegressionDocument51 pagesLinear RegressionKunal Langer100% (1)
- Chapter 2 (Part 2) : Bayesian Decision Theory (Sections 2.3-2.5)Document39 pagesChapter 2 (Part 2) : Bayesian Decision Theory (Sections 2.3-2.5)Anvit MangalNo ratings yet
- Ode 45Document6 pagesOde 45Gustavo SalgeNo ratings yet
- Ass 1Document3 pagesAss 1Vibhanshu LodhiNo ratings yet
- Convolutional Neural NetworkDocument78 pagesConvolutional Neural NetworkAaqib InamNo ratings yet
- Introduction To Big Data and Deep LearningDocument100 pagesIntroduction To Big Data and Deep LearningAaqib InamNo ratings yet
- Parallel ComputingDocument91 pagesParallel ComputingAaqib InamNo ratings yet
- A Bug and A PupDocument15 pagesA Bug and A PupAaqib InamNo ratings yet
- Tayangan Organisasi Komputer D3 - TKDocument358 pagesTayangan Organisasi Komputer D3 - TKMelkie WalelignNo ratings yet
- COSC 3101A - Design and Analysis of Algorithms 7Document50 pagesCOSC 3101A - Design and Analysis of Algorithms 7Aaqib InamNo ratings yet
- A Bug and A PupDocument12 pagesA Bug and A PupBernard ChanNo ratings yet
- All About PakistanDocument9 pagesAll About PakistanAaqib InamNo ratings yet
- Filtering SQL Injection From Classic ASPDocument130 pagesFiltering SQL Injection From Classic ASPAaqib InamNo ratings yet
- 8-Frank Lees - Loss Prevention - Hazard Idenitification, Assessment and Control (Volume 1) - Butterworth-Heinemann (1996) - 250-357Document108 pages8-Frank Lees - Loss Prevention - Hazard Idenitification, Assessment and Control (Volume 1) - Butterworth-Heinemann (1996) - 250-357RafaelNo ratings yet
- Attachment insecurity and breadcrumbing - cross cultural between india and spainDocument11 pagesAttachment insecurity and breadcrumbing - cross cultural between india and spainAkanksha MehtaNo ratings yet
- Periodismo CoolDocument26 pagesPeriodismo CoolAreli FranciscoNo ratings yet
- Mgt602 Mgt602 Assignment 2Document3 pagesMgt602 Mgt602 Assignment 2Abdul MananNo ratings yet
- Quiz 1 K53Document4 pagesQuiz 1 K53HàMềmNo ratings yet
- 7th GR Science Curriculum Map 2015-2016Document4 pages7th GR Science Curriculum Map 2015-2016Julius Memeg PanayoNo ratings yet
- EnergyDocument13 pagesEnergyThine Aliyah Robea GayapaNo ratings yet
- Scientific Method: Piercing Survey AnalysisDocument3 pagesScientific Method: Piercing Survey AnalysisSharon Rose Genita MedezNo ratings yet
- Kamrul Hasan PDFDocument153 pagesKamrul Hasan PDFayshabegumNo ratings yet
- Exponential DistributionDocument20 pagesExponential DistributionAhmar NiaziNo ratings yet
- Research Methodology and Profile of Respondents: Appendix ADocument92 pagesResearch Methodology and Profile of Respondents: Appendix AEllie YsonNo ratings yet
- Internship Report on Garments Accessories in BangladeshDocument38 pagesInternship Report on Garments Accessories in BangladeshzilanibenazirNo ratings yet
- Factors Affecting Accounting Information Systems Success ImplementationDocument13 pagesFactors Affecting Accounting Information Systems Success ImplementationTariq RahimNo ratings yet
- Practica L Research 1: Week 1: Nature of Inquiry and ResearchDocument46 pagesPractica L Research 1: Week 1: Nature of Inquiry and ResearchAnalyn Pasto100% (1)
- Reflection About Threats To Biodiversity and Thought Piece About Extreme MeasuresDocument2 pagesReflection About Threats To Biodiversity and Thought Piece About Extreme MeasuresNiña Dae GambanNo ratings yet
- Module 3Document7 pagesModule 3Aira Mae Quinones OrendainNo ratings yet
- POMA - IM - Chapter 5Document28 pagesPOMA - IM - Chapter 5Pham Phu Cuong B2108182No ratings yet
- Botox Research PaperDocument9 pagesBotox Research PaperMarinaNo ratings yet
- DISC 203-Probability and Statistics-Muhammad Asim PDFDocument6 pagesDISC 203-Probability and Statistics-Muhammad Asim PDFMinhal MalikNo ratings yet
- Unit 1Document76 pagesUnit 1Aditya GuptaNo ratings yet
- 2018 - The Episteme Journal of Linguistics and Literature Vol 4 No 1 - 3. NurhayatiDocument9 pages2018 - The Episteme Journal of Linguistics and Literature Vol 4 No 1 - 3. NurhayatiJayanta SarkarNo ratings yet
- Research Paper Title/Cover Page: Writing A Literature ReviewDocument1 pageResearch Paper Title/Cover Page: Writing A Literature ReviewFelix DawnNo ratings yet
- E-HRM: Emerging HR Practices in Private Banks: ISSN (ONLINE) : 2250-0758, ISSN (PRINT) : 2394-6962Document6 pagesE-HRM: Emerging HR Practices in Private Banks: ISSN (ONLINE) : 2250-0758, ISSN (PRINT) : 2394-6962Ifthisam banuNo ratings yet
- Shotgun Fungus LabDocument6 pagesShotgun Fungus LabSuleiman DaudaNo ratings yet
- IFB Project Abhishek NathTiwari 1Document67 pagesIFB Project Abhishek NathTiwari 1Abhishek Tiwari67% (3)
- Curriculum Leadership Chapter 5Document15 pagesCurriculum Leadership Chapter 5JeyShidaNo ratings yet
- God Rej Hi CareDocument92 pagesGod Rej Hi CaremohideenbashaNo ratings yet
- Critical ReadingDocument4 pagesCritical ReadingIccy LaoNo ratings yet
- Project Steel September 2015Document9 pagesProject Steel September 2015Faka AminNo ratings yet
- Content Analysis in Social Sciences: Manual to Automated ApproachesDocument75 pagesContent Analysis in Social Sciences: Manual to Automated Approachesdiablero999No ratings yet