You might also like
- Wireless and Mobile Communication: Lab Slot:L37+L38 Prof: Abhijit BhowmickDocument5 pagesWireless and Mobile Communication: Lab Slot:L37+L38 Prof: Abhijit BhowmickAbhiramNo ratings yet
- Module 5: Fabrication Methods Photolithography: Raja SellappanDocument24 pagesModule 5: Fabrication Methods Photolithography: Raja SellappanAbhiramNo ratings yet
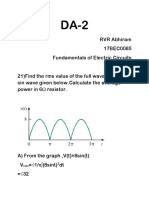
- RVR Abhiram 17BEC0085 Fundamentals of Electric CircuitsDocument2 pagesRVR Abhiram 17BEC0085 Fundamentals of Electric CircuitsAbhiramNo ratings yet
- "I Have A Dream ..": 17BEC00085 RVR Abhiram English For EngineersDocument2 pages"I Have A Dream ..": 17BEC00085 RVR Abhiram English For EngineersAbhiramNo ratings yet
- 17bec0085 GDDocument2 pages17bec0085 GDAbhiramNo ratings yet
- Assignment: 1: School of Electronics Engineering ECE4009-Wireless and Mobile CommunicationsDocument2 pagesAssignment: 1: School of Electronics Engineering ECE4009-Wireless and Mobile CommunicationsAYUSH GURTU 17BEC0185No ratings yet
- Els Lab FatDocument5 pagesEls Lab FatAbhiramNo ratings yet
- Wireless and Mobile Communication: Lab Slot:L37+L38 Prof: Abhijit BhowmickDocument6 pagesWireless and Mobile Communication: Lab Slot:L37+L38 Prof: Abhijit BhowmickAbhiramNo ratings yet
- Ethics 1Document13 pagesEthics 1DeepakKumarNo ratings yet
- Prevention of TerrorismDocument18 pagesPrevention of TerrorismAbhiramNo ratings yet
- Digital Assignment - 1: Name: RVR Abhiram Reg No: 17BEC0085 Subject: Engineering Physics PHY-1701Document6 pagesDigital Assignment - 1: Name: RVR Abhiram Reg No: 17BEC0085 Subject: Engineering Physics PHY-1701AbhiramNo ratings yet
- Prevention of HarassmentDocument4 pagesPrevention of HarassmentmansurNo ratings yet
- Prevention of TerrorismDocument18 pagesPrevention of TerrorismAbhiramNo ratings yet
- Societys Interest Vs Self InterestsDocument7 pagesSocietys Interest Vs Self InterestsAbhiramNo ratings yet
- Tax Evasion in IndiaDocument4 pagesTax Evasion in IndiamansurNo ratings yet
- Tax EvasionDocument5 pagesTax EvasionAbhiramNo ratings yet
- White Collar CrimeDocument17 pagesWhite Collar CrimeAbhiramNo ratings yet
- Prevention of HarassmentDocument4 pagesPrevention of HarassmentmansurNo ratings yet
- Corruption in IndiaDocument10 pagesCorruption in IndiaNaveen YannamaniNo ratings yet
- Gandhian ValuesDocument21 pagesGandhian ValuesAbhiram100% (1)
- Preventing Harassment in The WorkplaceDocument32 pagesPreventing Harassment in The WorkplaceAbhiramNo ratings yet
- Prevention of ViolenceDocument8 pagesPrevention of ViolenceAbhiramNo ratings yet
- Leaders of Past and PresentDocument54 pagesLeaders of Past and PresentAbhiramNo ratings yet
- Prevention of Suicides AJDocument22 pagesPrevention of Suicides AJAbhiramNo ratings yet
- Quality Check For SoftdrinksDocument2 pagesQuality Check For SoftdrinksAbhiram0% (1)
- Dr. M. Bhuvaneswari, PHD PsyDocument21 pagesDr. M. Bhuvaneswari, PHD PsyAbhiramNo ratings yet
- Social ResponsibilityDocument2 pagesSocial ResponsibilityAbhiramNo ratings yet
- Drug AbuseDocument59 pagesDrug AbuseAbhiramNo ratings yet
- Chemistry of MethanolDocument1 pageChemistry of MethanolAbhiramNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Application of MicroprocessorDocument6 pagesApplication of Microprocessorberhe2121No ratings yet
- MIPS Instruction Set Architecture PDFDocument70 pagesMIPS Instruction Set Architecture PDFhalfaiaNo ratings yet
- PIC Introduction PDFDocument46 pagesPIC Introduction PDFPeeyush Kp100% (1)
- Chap 9Document59 pagesChap 9utkarsh1223No ratings yet
- User Manual To LPC ControllersDocument709 pagesUser Manual To LPC ControllersAnna Sandoval0% (1)
- Introduction To Microprocessors and MicrocontrollersDocument27 pagesIntroduction To Microprocessors and Microcontrollerskapasitor 2017100% (1)
- 3rd Sem SyllabusDocument15 pages3rd Sem Syllabustest mailNo ratings yet
- Implementation of Drowsiness, Vehicle Safety and Alcohol Intoxication Detection Using Raspberry PIDocument10 pagesImplementation of Drowsiness, Vehicle Safety and Alcohol Intoxication Detection Using Raspberry PIHarshaNo ratings yet
- Chapter 1 EditDocument463 pagesChapter 1 Edittthanhhoa17112003No ratings yet
- Computer Organization & Architecture: Dr. Muhammad UsmanDocument58 pagesComputer Organization & Architecture: Dr. Muhammad UsmanShafaat AliNo ratings yet
- 18cs441 MC-1 PDFDocument2 pages18cs441 MC-1 PDFM.A rajaNo ratings yet
- Gip UNIT IDocument39 pagesGip UNIT IjesudosssNo ratings yet
- Computer Organization: Sandeep KumarDocument117 pagesComputer Organization: Sandeep KumarGaurav NNo ratings yet
- Design & Simulation of A 32-Bit Risc Based Mips Processor Using VerilogDocument7 pagesDesign & Simulation of A 32-Bit Risc Based Mips Processor Using VerilogTàiLươngNo ratings yet
- 8051 NotesDocument61 pages8051 Notessubramanyam62No ratings yet
- Principles of Computer Hardware - PDF RoomDocument705 pagesPrinciples of Computer Hardware - PDF Roomboniface ChosenNo ratings yet
- MA C6000 2DAY Student Guide Rev2.3Document164 pagesMA C6000 2DAY Student Guide Rev2.3gsmsbyNo ratings yet
- Advanced Microprocessors and MicrocontrollersDocument1 pageAdvanced Microprocessors and MicrocontrollersVijayaraghavan V0% (1)
- WINSEM2022-23 BECE204L TH VL2022230500878 2022-12-13 Reference-Material-IDocument27 pagesWINSEM2022-23 BECE204L TH VL2022230500878 2022-12-13 Reference-Material-IAshwin Raj 21BEC0400No ratings yet
- CH-1.Central Processing UnitDocument75 pagesCH-1.Central Processing UnitDevanshi GudsariyaNo ratings yet
- Patient Monitoring System Project Report OriginalDocument84 pagesPatient Monitoring System Project Report OriginalAmar Dharmadhikari62% (13)
- (New) Coa Unit1Document76 pages(New) Coa Unit1Adolf HitlerNo ratings yet
- Lecture3 AssemblyDocument26 pagesLecture3 Assemblyecevitmert1453No ratings yet
- ES - 2 Marks Questions-1Document17 pagesES - 2 Marks Questions-1DurgadeviNo ratings yet
- Module - 1 NotesDocument18 pagesModule - 1 NotesAnkith S RaoNo ratings yet
- Passenger Bus Alert System For Easy Navigation of Blind Diravath Chander, M.Venkata SireeshaDocument7 pagesPassenger Bus Alert System For Easy Navigation of Blind Diravath Chander, M.Venkata SireeshaAchyuth AchyuthNo ratings yet
- Computer Architecture Lesson 2 (Instruction Set Architecture)Document9 pagesComputer Architecture Lesson 2 (Instruction Set Architecture)ghassanNo ratings yet
- Combined14 S 2Document520 pagesCombined14 S 2Umair Mujtaba QureshiNo ratings yet
- BSC H Computer ScienceDocument209 pagesBSC H Computer ScienceSmNo ratings yet
- Toaz - Info Solution Manual of Probability Amp Statistics For Engineers Amp Scientists PRDocument31 pagesToaz - Info Solution Manual of Probability Amp Statistics For Engineers Amp Scientists PRRashmitha RavichandranNo ratings yet